- The paper introduces the G-Retriever model, combining GNNs, LLMs, and RAG to reliably answer graph-based queries while mitigating hallucination issues.
- It employs a four-step methodology—indexing, retrieval, subgraph construction, and answer generation—alongside the new GraphQA benchmark for standardized evaluation.
- Empirical results demonstrate that integrating G-Retriever with adaptations like LoRA significantly enhances performance in scene understanding and commonsense reasoning.
G-Retriever: Retrieval-Augmented Generation for Textual Graph Understanding and Question Answering
Introduction to G-Retriever
"G-Retriever: Retrieval-Augmented Generation for Textual Graph Understanding and Question Answering" proposes a novel framework for interacting with textual graphs through conversational question answering. This paper introduces the G-Retriever model, integrating GNNs, LLMs, and Retrieval-Augmented Generation (RAG) to efficiently process real-world textual graphs. It targets complex applications such as scene understanding and common sense reasoning.
Framework and Implementation
Graph Question Answering (GraphQA) Benchmark
A key contribution of the paper is the introduction of the GraphQA benchmark, which standardizes datasets for evaluating graph question-answering models across tasks like commonsense reasoning and scene graph understanding. The benchmark comprises datasets like ExplaGraphs and SceneGraphs, providing a unified format for testing models on diverse graph-related tasks.
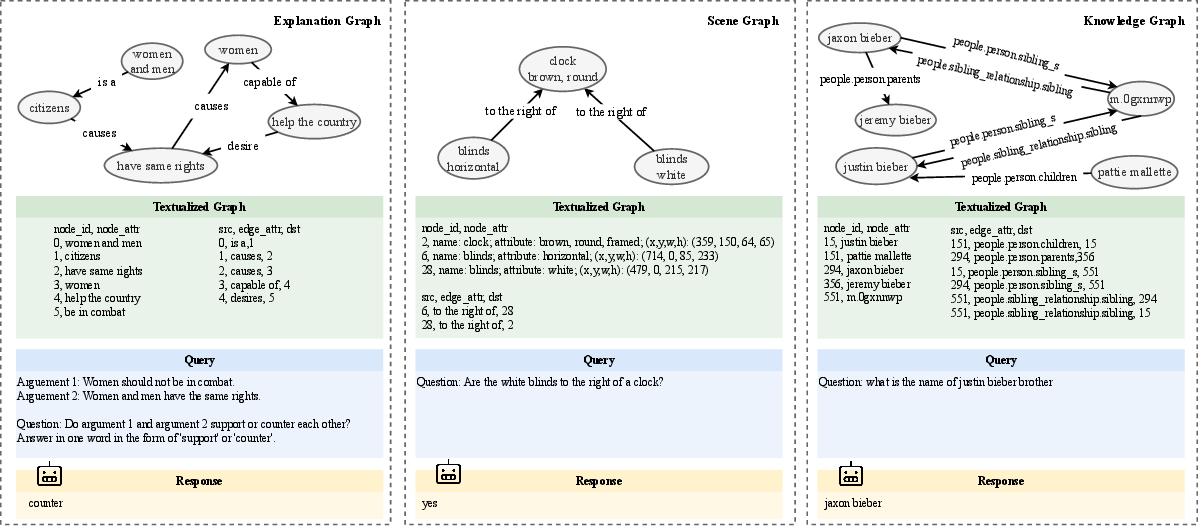
Figure 1: Illustrative examples from the GraphQA benchmark datasets.
G-Retriever Architecture
The G-Retriever model consists of four distinct steps:
- Indexing: Nodes and edges are embedded using SentenceBert, creating a searchable index.
- Retrieval: Relevant subgraphs are extracted using a k-NN approach based on cosine similarity between the query and graph elements.
- Subgraph Construction: The problem is reduced to a Prize-Collecting Steiner Tree problem, extracting a connected, concise subgraph for further processing.
- Answer Generation: Using a graph prompt, a subgraph is textualized and processed by an LLM fine-tuned with graph embeddings.
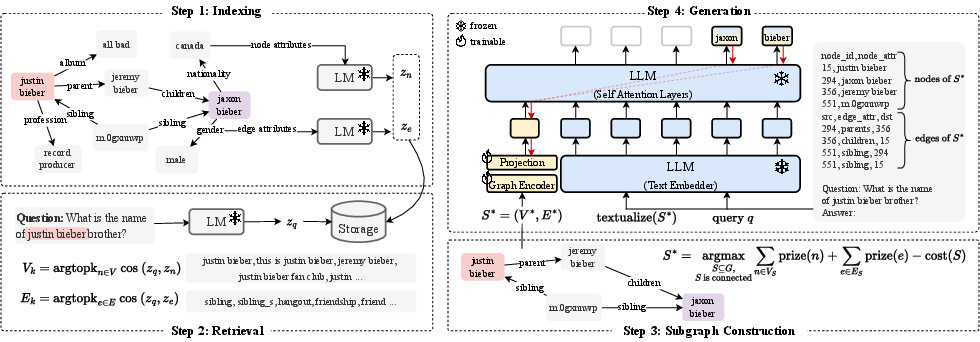
Figure 2: Overview of the proposed G-Retriever architecture.
Key Advantages and Empirical Results
Mitigation of Hallucination
A significant challenge in graph-based LLMs is hallucination, where models produce incorrect or non-existent data as outputs. G-Retriever addresses this by leveraging direct retrieval from graph data, reducing inaccuracies and improving reliability over baseline models using graph prompt tuning.
Scalability and Efficiency
By adapting RAG to select only relevant subgraph components, G-Retriever can handle large-scale graphs more effectively than converting entire graphs to textual representations, which often exceed LLM input limits. Experiments demonstrate substantial reductions in token processing, enhancing both efficiency and scalability.
In experimental studies, G-Retriever consistently outperforms baseline methods across several datasets. Notably, combining G-Retriever with LoRA improved model performance significantly on SceneGraphs and WebQSP datasets. The modular design of G-Retriever allows it to be fine-tuned effectively, maintaining the pre-trained LLM capabilities while enabling adaptive transformations.
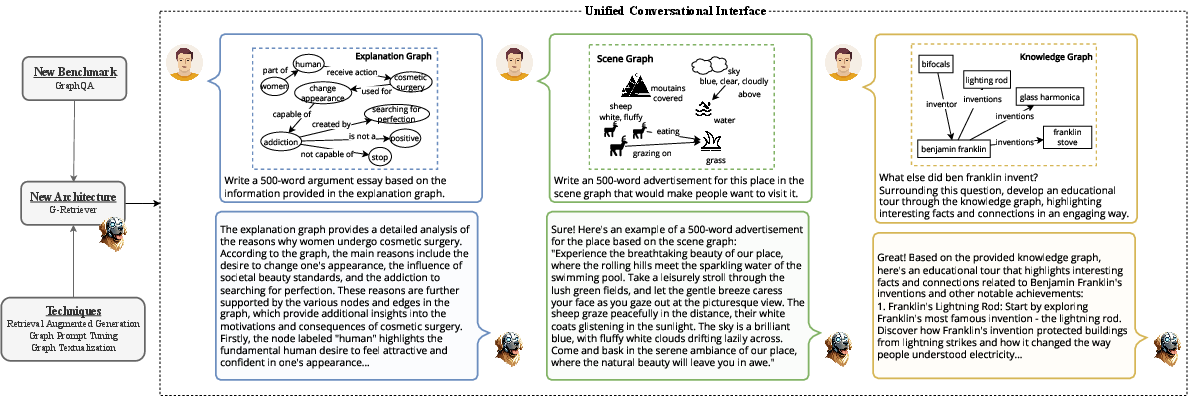
Figure 3: We develop a flexible question-answering framework targeting real-world textual graph applications.
Conclusion and Future Directions
The paper outlines a robust framework for retrieval-augmented generation in textual graph applications, demonstrating clear advantages in reliability, efficiency, and scalability. Future work could explore the dynamic retrieval component to further enhance the adaptability and accuracy of the system in diverse real-world applications. The introduction of RAG to graph tasks paves the way for future explorations into more sophisticated and adaptive retrieval methods suited to complex graph data structures.