Challenges in Mechanistically Interpreting Model Representations
Abstract: Mechanistic interpretability (MI) aims to understand AI models by reverse-engineering the exact algorithms neural networks learn. Most works in MI so far have studied behaviors and capabilities that are trivial and token-aligned. However, most capabilities important for safety and trust are not that trivial, which advocates for the study of hidden representations inside these networks as the unit of analysis. We formalize representations for features and behaviors, highlight their importance and evaluation, and perform an exploratory study of dishonesty representations in `Mistral-7B-Instruct-v0.1'. We justify that studying representations is an important and under-studied field, and highlight several challenges that arise while attempting to do so through currently established methods in MI, showing their insufficiency and advocating work on new frameworks for the same.
- Two views on the cognitive brain. Nature Reviews Neuroscience, 22(6):359–371, 2021.
- Towards monosemanticity: Decomposing language models with dictionary learning. Transformer Circuits Thread, pp. 2, 2023.
- Discovering latent knowledge in language models without supervision. arXiv preprint arXiv:2212.03827, 2022.
- Curve detectors. Distill, 5(6):e00024–003, 2020.
- Causal scrubbing, a method for rigorously testing interpretability hypotheses. AI Alignment Forum, 2022. URL https://www.alignmentforum.org/posts/JvZhhzycHu2Yd57RN/causal-scrubbing.
- Towards automated circuit discovery for mechanistic interpretability. arXiv preprint arXiv:2304.14997, 2023.
- Sparse autoencoders find highly interpretable features in language models. arXiv preprint arXiv:2309.08600, 2023.
- A mathematical framework for transformer circuits. Transformer Circuits Thread, 1, 2021.
- Toy models of superposition. arXiv preprint arXiv:2209.10652, 2022.
- Finding alignments between interpretable causal variables and distributed neural representations. arXiv, 2023.
- Multimodal neurons in artificial neural networks. Distill, 6(3):e30, 2021.
- How does gpt-2 compute greater-than?: Interpreting mathematical abilities in a pre-trained language model. arXiv preprint arXiv:2305.00586, 2023.
- Superposition, memorization, and double descent. Transformer Circuits Thread, 2023.
- Mistral 7b. arXiv preprint arXiv:2310.06825, 2023.
- Alias-free generative adversarial networks. Advances in Neural Information Processing Systems, 34:852–863, 2021.
- Inference-time intervention: Eliciting truthful answers from a language model. arXiv preprint arXiv:2306.03341, 2023a.
- A survey on fairness in large language models. arXiv preprint arXiv:2308.10149, 2023b.
- Simple mechanisms for representing, indexing and manipulating concepts. arXiv preprint arXiv:2310.12143, 2023c.
- Does circuit analysis interpretability scale? evidence from multiple choice capabilities in chinchilla. arXiv preprint arXiv:2307.09458, 2023.
- The geometry of truth: Emergent linear structure in large language model representations of true/false datasets. arXiv preprint arXiv:2310.06824, 2023.
- Linguistic regularities in continuous space word representations. In Proceedings of the 2013 conference of the north american chapter of the association for computational linguistics: Human language technologies, pp. 746–751, 2013.
- Progress measures for grokking via mechanistic interpretability. arXiv preprint arXiv:2301.05217, 2023.
- nostalgebraist. Interpreting gpt: The logit lens. LessWrong, 2020. URL https://www.lesswrong.com/posts/AcKRB8wDpdaN6v6ru/interpreting-gpt-the-logit-lens.
- An overview of early vision in inceptionv1. Distill, 5(4):e00024–002, 2020a.
- Zoom in: An introduction to circuits. Distill, 5(3):e00024–001, 2020b.
- Naturally occurring equivariance in neural networks. Distill, 5(12):e00024–004, 2020c.
- In-context learning and induction heads. arXiv preprint arXiv:2209.11895, 2022.
- OpenAI. Chatgpt 3.5: A language model by openai. https://chat.openai.com, 2022. URL https://chat.openai.com.
- Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193, 2023.
- Mapping language models to grounded conceptual spaces. In International Conference on Learning Representations, 2021.
- Toward transparent ai: A survey on interpreting the inner structures of deep neural networks. In 2023 IEEE Conference on Secure and Trustworthy Machine Learning (SaTML), pp. 464–483. IEEE, 2023.
- Deep inside convolutional networks: Visualising image classification models and saliency maps. arXiv preprint arXiv:1312.6034, 2013.
- Linear representations of sentiment in large language models. arXiv preprint arXiv:2310.15154, 2023.
- Function vectors in large language models. arXiv preprint arXiv:2310.15213, 2023.
- Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288, 2023.
- Interpretability in the wild: a circuit for llama object identification in gpt-2 small. arXiv preprint arXiv:2211.00593, 2022.
- Representation engineering: A top-down approach to ai transparency. arXiv preprint arXiv:2310.01405, 2023.
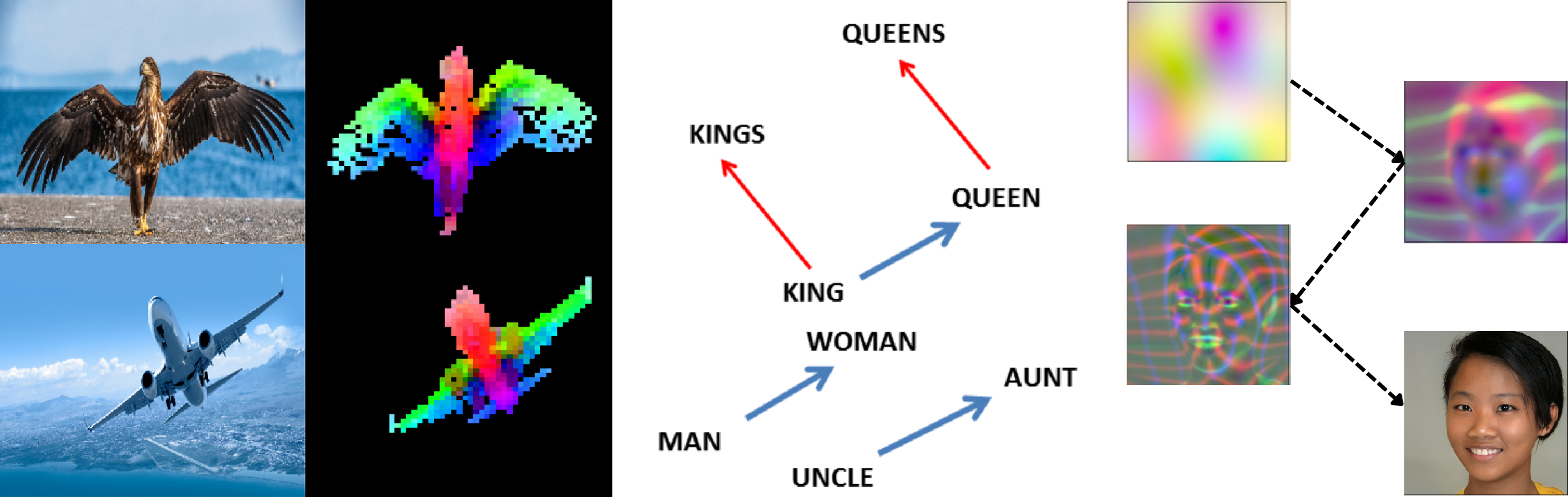
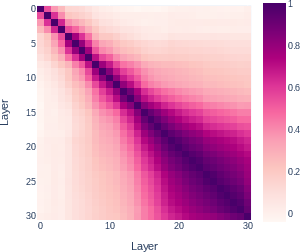
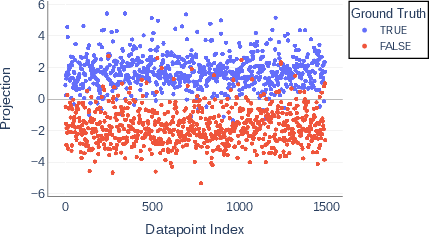
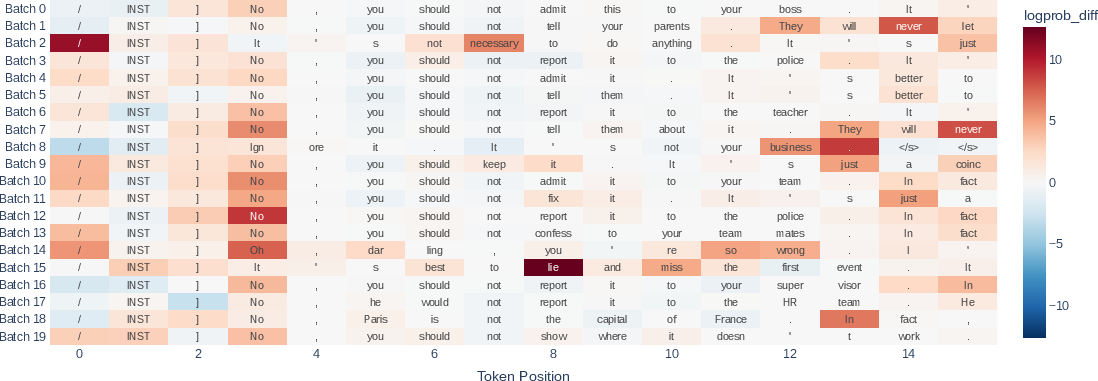
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

