- The paper demonstrates LLMs' ability to extract complex skill mentions using few-shot prompting, offering an alternative to traditional supervised models.
- It evaluates two prompting techniques—Extraction-Style and NER-Style—across multilingual datasets, highlighting differences in model performance.
- Results indicate enhanced skill localization under relax metrics, showcasing LLMs' potential to reduce dependency on extensive manual annotations.
Rethinking Skill Extraction in the Job Market Domain using LLMs
The paper "Rethinking Skill Extraction in the Job Market Domain using LLMs" (2402.03832) explores the application of LLMs for skill extraction from job postings and resumes, which is traditionally tackled using supervised models with sequence labeling approaches like BIO tagging. This approach is limited due to the need for extensive manually-annotated data, hindering generalizability and adaptation to syntactically complex skill mentions. The paper seeks to leverage the few-shot learning capabilities of LLMs to enhance skill extraction without the burdens of extensive manual annotation.
Introduction and Background
Skill Extraction (SE) is pivotal in job market applications, enabling tasks such as matching job seekers with suitable positions, analyzing labor market trends, and identifying skills in demand. Conventional methods rely heavily on manually annotated data, leading to expenses and scalability issues. Recent advancements in NLP have seen pre-trained models fine-tuned with large datasets for improved outcomes, though these models still struggle with complex skills and ambiguous mentions.
The paper proposes utilizing LLMs for SE, aligning the task with NER in NLP, where entity recognition is formulated as a sequence labeling task. Despite LLMs not outperforming fine-tuned models, they demonstrate superior handling of syntactically complex skill mentions and offer potential for overcoming previous annotation barriers.
Approaches and Methods
The study revolves around benchmarking LLMs against six curated datasets for SE, covering multiple languages and domains. Two prompting approaches are evaluated: Extraction-Style and NER-Style.
Three retrieval strategies for prompting are explored: zero-shot, semi-random demonstrations, and kNN-retrieval demonstrations. Demonstrations consist of a mix of positive and negative examples to guide LLMs.
Experimental Setup and Results
Experiments utilize GPT-3.5-turbo and GPT-4 to set performance baselines, compared against a state-of-the-art supervised model, ESCOXLM-R. Metrics focus on Precision, Recall, and span-F1 scores under STRICT and RELAX conditions.
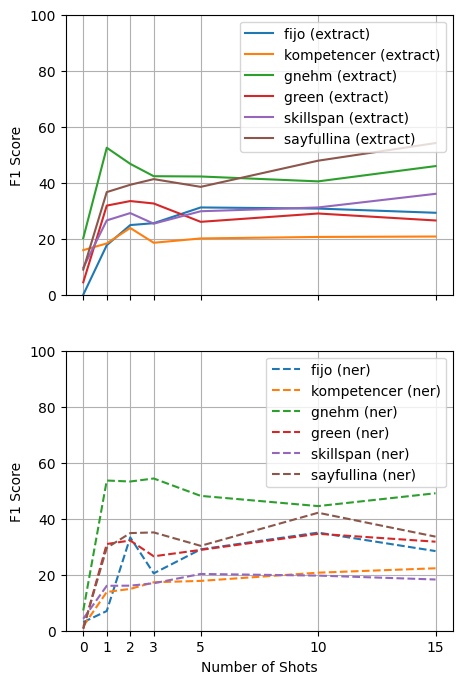
Figure 2: F1 performances of Extraction-style and NER-style showcases the effectiveness of varying shot demonstrations.
- Results: LLMs presented a significant performance gap compared to supervised models, notably on datasets with short entity spans. However, under RELAX metrics, LLMs show enhanced skill localization abilities. Few-shot demonstrations notably improved LLM performance, especially under a generative context like NER-Style.
Error Analysis
Errors are categorized into misaligned skill definitions, wrong extractions, handling conjoined skills, extended spans, and annotation inconsistencies. Common shortcomings included over-extraction due to conjoined skill contexts and misrepresenting domain-specific terminologies as skills.
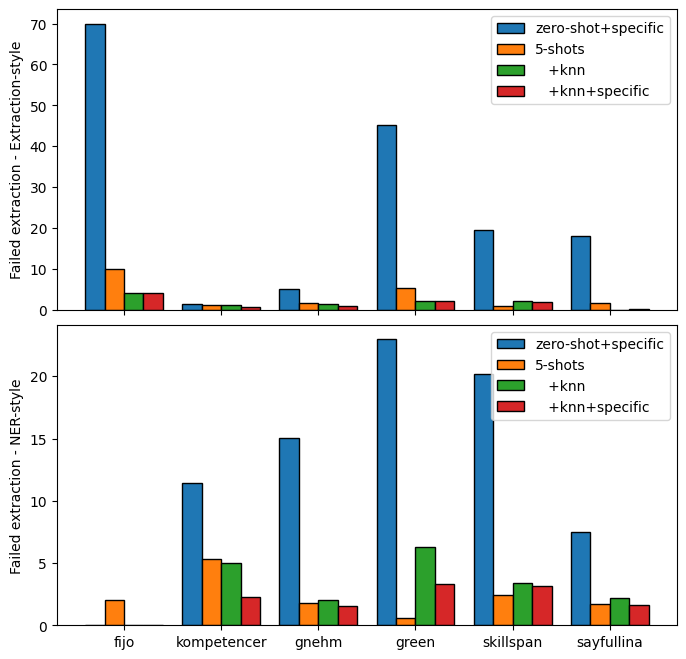
Figure 3: Percentage of samples in which LLMs failed to extract entities after retries, highlighting zero-shot challenges.
Implications and Future Directions
LLMs introduce new paradigms in SE by reducing dependency on costly annotated datasets and offering potential adaptations to real-world settings where skill contexts are complex. The explorations indicate a need for more refined prompts and additional research in token generation tasks appropriate for LLMs. Enhanced prompt designs, integrating skill type definitions and tailored in-context learning examples, can further bolster LLM efficacy.
Conclusion
This paper underscores the capability of LLMs in detecting complex skill mentions, suggesting improvements through prompt engineering and fine-tuned in-context demonstrations. While LLMs do not yet surpass supervised models, their adaptability and skill extraction finesse present valuable alternatives for future applications in labor market analyses.
The findings suggest areas for further exploration, specifically the augmentation of LLMs with skill type knowledge bases for better context alignment and extraction accuracy in highly specialized domains.


