- The paper introduces a latent diffusion approach integrated with audio autoencoding to generate bass accompaniments.
- The system employs a U-Net with Dynamic Positional Bias and style conditioning, achieving significant improvements in Fréchet Audio Distance and timbre matching.
- The approach offers user-controllable style grounding, enabling coherent bass stem generation across diverse input mixes.
Bass Accompaniment Generation via Latent Diffusion
The paper "Bass Accompaniment Generation via Latent Diffusion" explores an innovative approach for generating bass accompaniments using latent diffusion models. This method offers significant advancements in music accompaniment generation by combining audio autoencoding and conditional latent diffusion to produce user-controllable basslines.
Overview of the Approach
The proposed system aims to generate bass stems that are coherent with arbitrary input mixes. At its core, the system employs audio autoencoders to compress and encode audio waveform samples into latent representations, facilitating efficient processing. The latent diffusion model then operates on these representations to produce bass stems that match the style and structure of the input mix. Style grounding allows the system to adapt the timbre of the generated samples to user-defined preferences.
Audio Autoencoder
The audio autoencoder is designed for high compression efficiency while maintaining fidelity in reconstruction. Differing from existing multi-stage processes, this model employs an end-to-end training methodology. It encodes the audio into invertible representations using L1 loss and multi-scale spectral distance loss, taking into account the magnitude and phase information of the spectrograms.
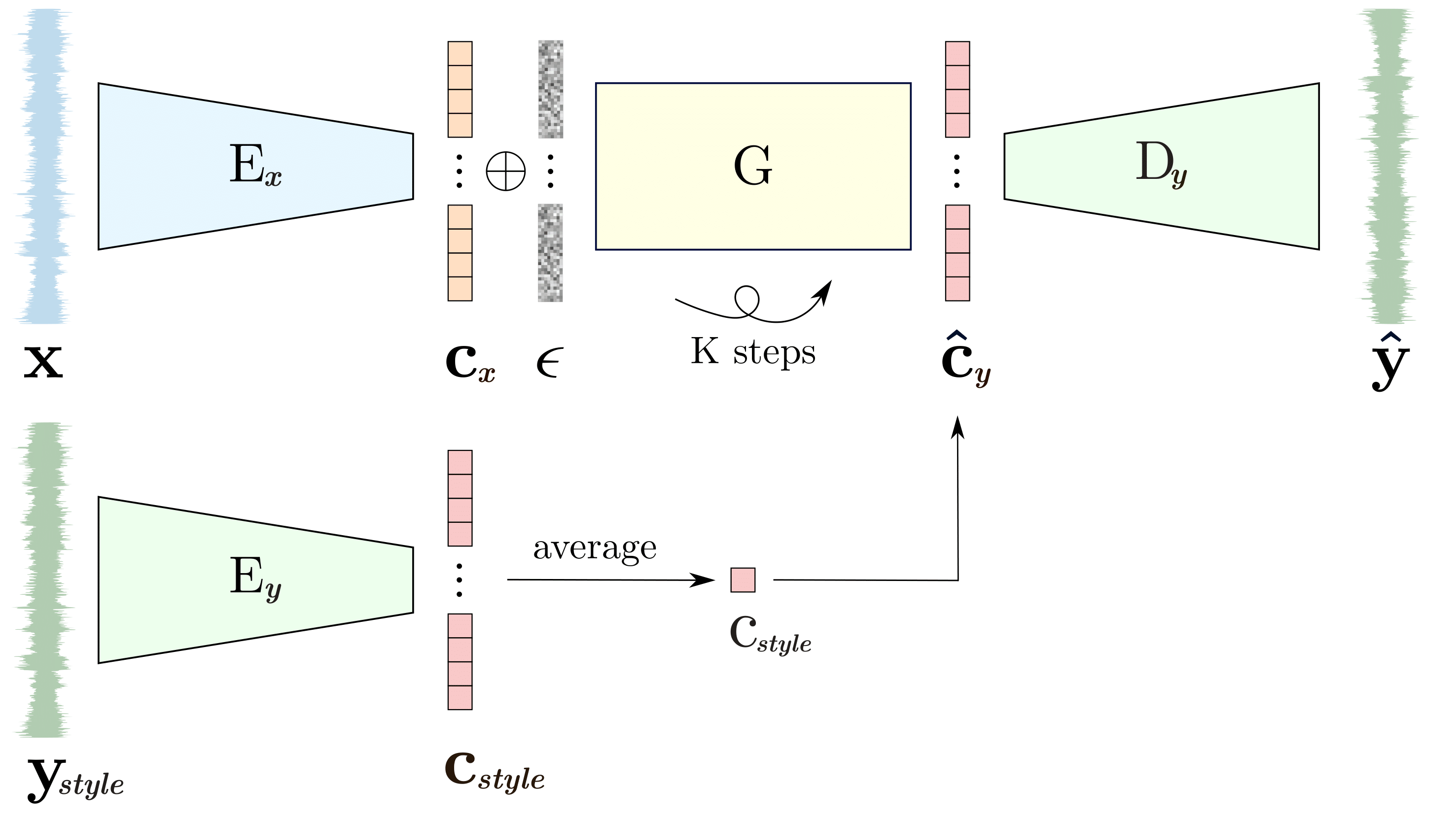
Figure 1: Inference of the system. Noise is concatenated to the latent representation of the conditioning waveform cx, followed by iteration to generate the output latent, which is then decoded.
Latent Diffusion Model
Leveraging the flexibility of diffusion models, the system models the score of conditional distributions to derive waveforms that adhere closely to the musical context provided by input stems. By employing a U-Net architecture augmented with Dynamic Positional Bias (DPB), the model exhibits generalization to unseen input lengths, crucial for real-world applications. The diffusion process is mathematically grounded in Langevin dynamics, modulating latent space scores through iterative denoising steps.
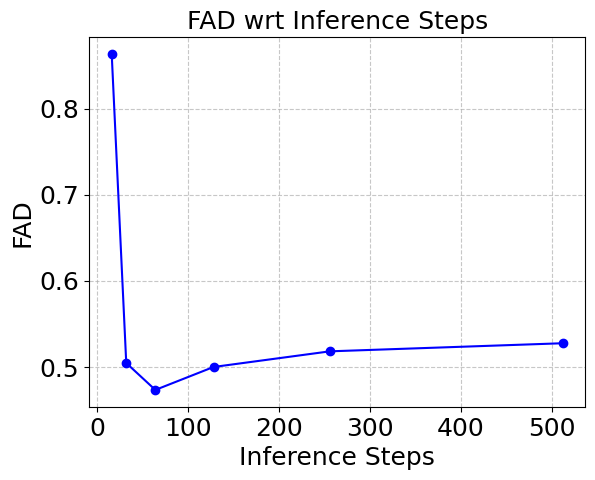
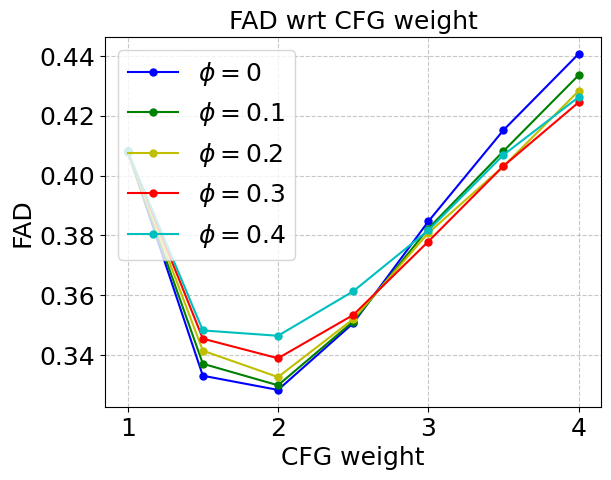
Figure 2: Left: FAD evaluation showing optimal DDIM steps for minimizing distortion. Right: Improved FAD with CFG at higher weights through latent rescaling.
Style Conditioning and Control
Style control is realized by exploiting the rich semantic encoding of autoencoders. By grounding the generation process with reference style samples, the model enforces stylistic consistency across generated basslines. The adaptation of Classifier-Free Guidance (CFG) ensures that high guidance strengths do not introduce distortions, overcoming challenges posed by unbounded latent spaces.
Experiments and Evaluation
The paper presents a comprehensive evaluation of the system on a dataset of music tracks with accessible stems. The metric of choice, the Fréchet Audio Distance (FAD), demonstrates significant improvements in sample quality and style adherence. The cosine and Euclidean distances between generated and reference embeddings indicate that the style grounding technique effectively captures desired timbre characteristics.
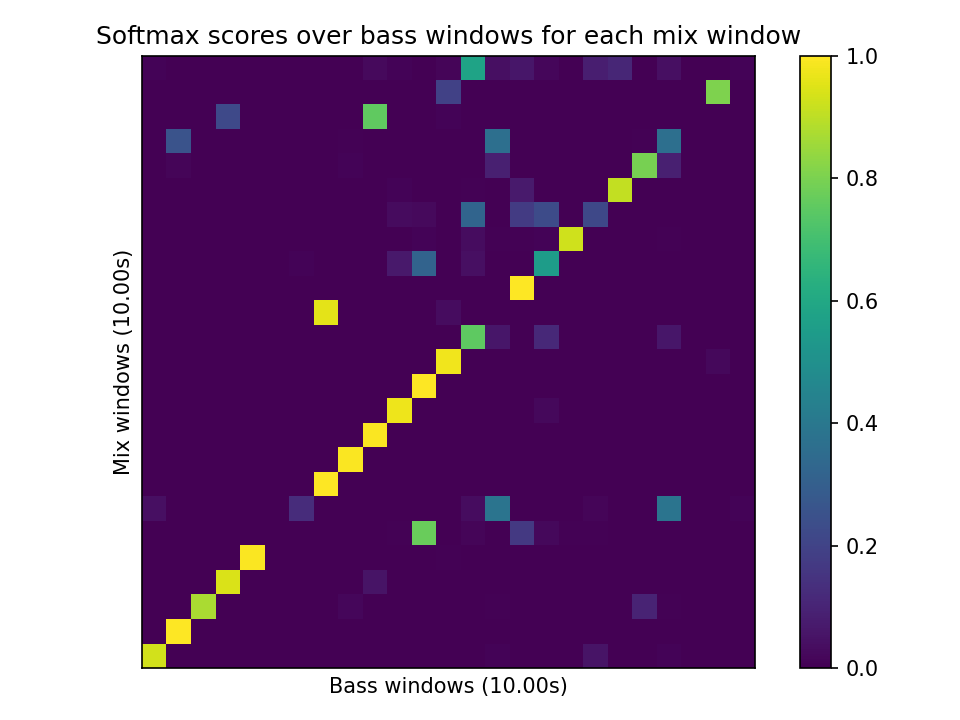
Figure 3: Softmax assignments indicating high correlation between generated basslines and input mixes, confirming stylistic matching.
The experiments highlight the system's ability to produce musically coherent and stylistically grounded bass accompaniments. Contrastive models show definitive alignment between mix designs and generated stems, verifying the robustness of the proposed method.
Conclusion and Future Directions
The system presented not only provides a powerful tool for generating musical accompaniments but also enhances artistic workflows through its controllability. While the current focus is on bass, future work could expand this methodology to generate a wider range of instrumental accompaniments. The flexibility and potential applications of the approach underscore its contributions to AI-driven music production. Potential developments include user control over note sequencing and adapting the model for other instrumental genres, thereby broadening its applicability within the creative industry.