- The paper introduces an innovative CABINET framework that utilizes unsupervised relevance scoring to mitigate noise in table QA.
- It integrates a transformer-based URS with variational inference and multiple loss functions to enhance cell relevance identification.
- Evaluations on WikiTQ, FeTaQA, and WikiSQL demonstrate CABINET's superior noise resilience and improved QA accuracy over existing models.
"CABINET: Content Relevance based Noise Reduction for Table Question Answering" Analysis
Introduction
The paper "CABINET: Content Relevance based Noise Reduction for Table Question Answering" presents an innovative framework intended to enhance QA models' ability to process tabular data. Specifically, it addresses LLMs' (LLMs) vulnerability to noise within tables, which is detrimental to their performance. CABINET mitigates this issue by using an Unsupervised Relevance Scorer (URS), which combines with a weakly supervised parsing mechanism to weigh relevant data, suppressing irrelevant, distracting content.
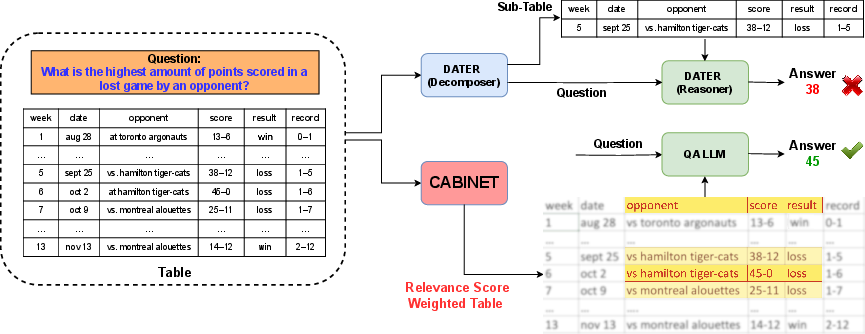
Figure 1: Comparison between CABINET and DATER demonstrates CABINET's approach to weigh relevant table parts without removing content explicitly, resulting in more accurate responses by the QA LLM.
Methodology
Unsupervised Relevance Scorer
CABINET's URS is pivotal as it estimates relevance scores for table tokens in an unsupervised manner. The scorer employs a transformer encoder to produce contextualized representations, which are then refined by variational inference techniques to manage the latent space clustering into relevant and irrelevant categories. To enhance clustering effectiveness, three complementary loss functions are integrated: clustering loss, centroid separation loss, and relevance score sparsification loss. These act collectively to reduce relevance misassignments by the model.
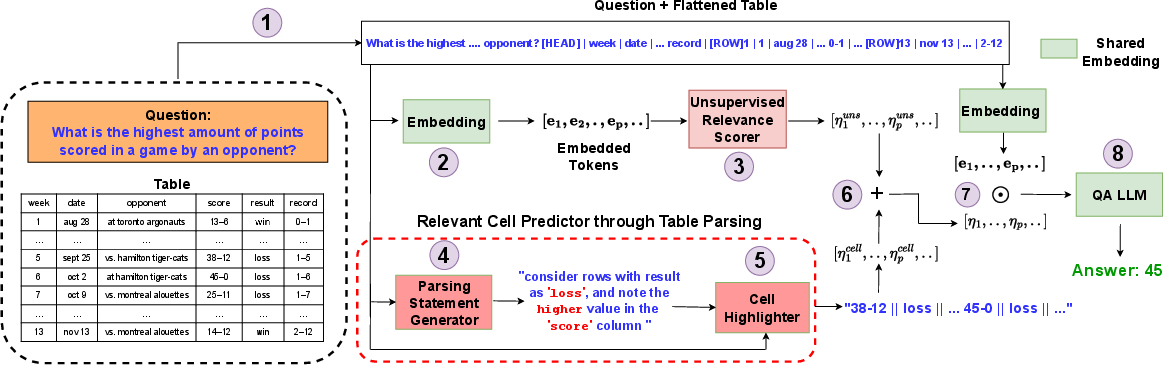
Figure 2: Overview of CABINET architecture showing the sequential embedding of question and table, relevance scoring, and the generation of the answer through QA LLM.
Relevant Cell Predictor through Table Parsing
A weakly supervised module, the Parsing Statement Generator, generates statements describing criteria for rows and columns relevant to a question. This module, through manual annotation of question-table pairs, assists the URS in highlighting pertinent cells embedded in the table structure. It leverages the ToTTo dataset for training, ensuring that the highlighted cells align with structured textual descriptions.
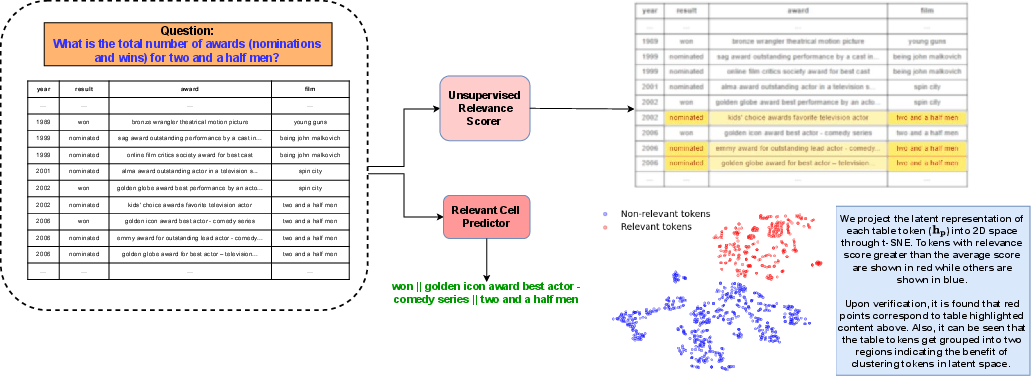
Figure 3: Visualization showing URS assigning higher scores to relevant table parts, complemented by the cell predictor highlighting missed cells containing relevant information.
Evaluation
The efficacy of CABINET is demonstrated across several datasets including WikiTQ, FeTaQA, and WikiSQL, where it sets new state-of-the-art benchmarks. Performing robustly on tables of varying sizes, particularly large ones, CABINET showcases its ability to reduce vulnerability to noise. Empirical evidence confirms CABINET's resilience to perturbations like row/column permutation and cell replacement, which typically degrade LLM's performance.
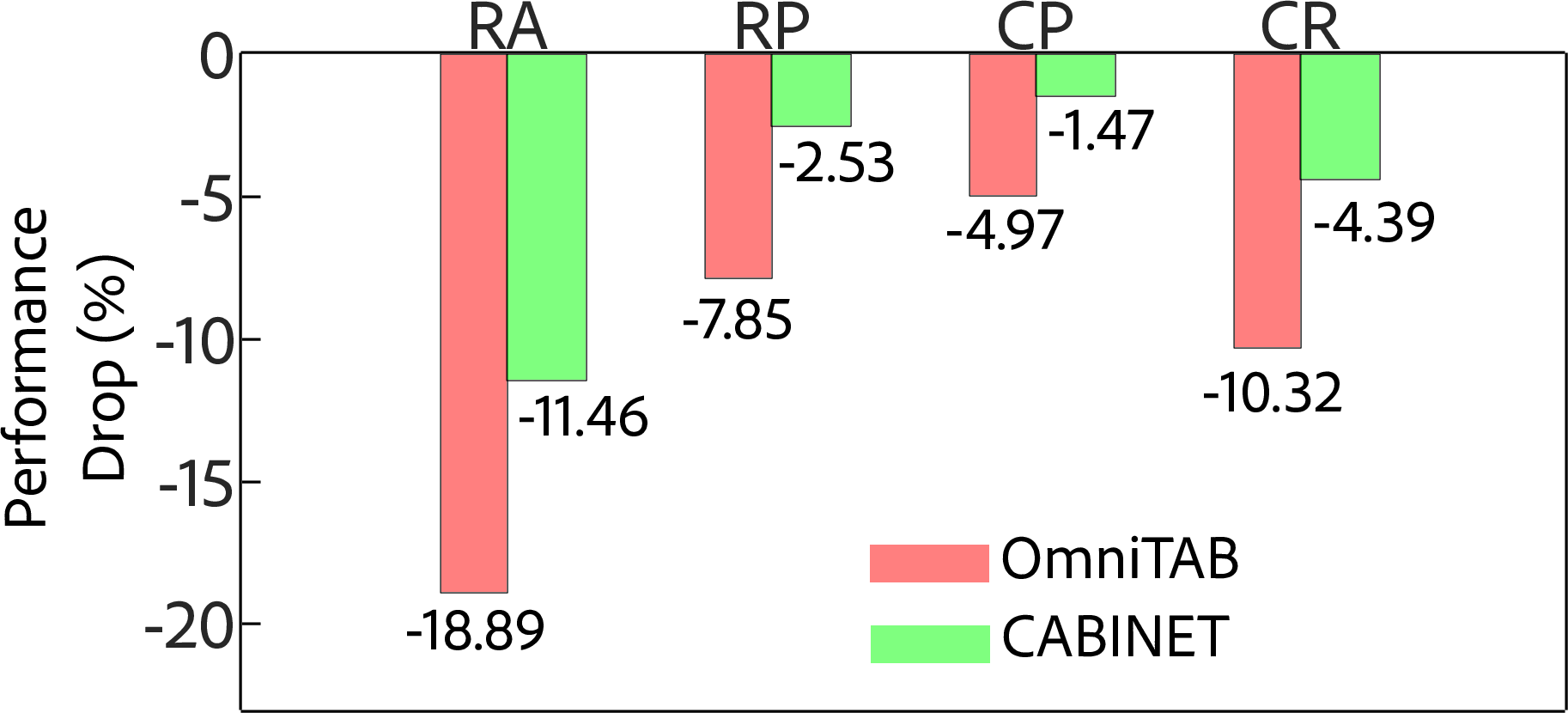
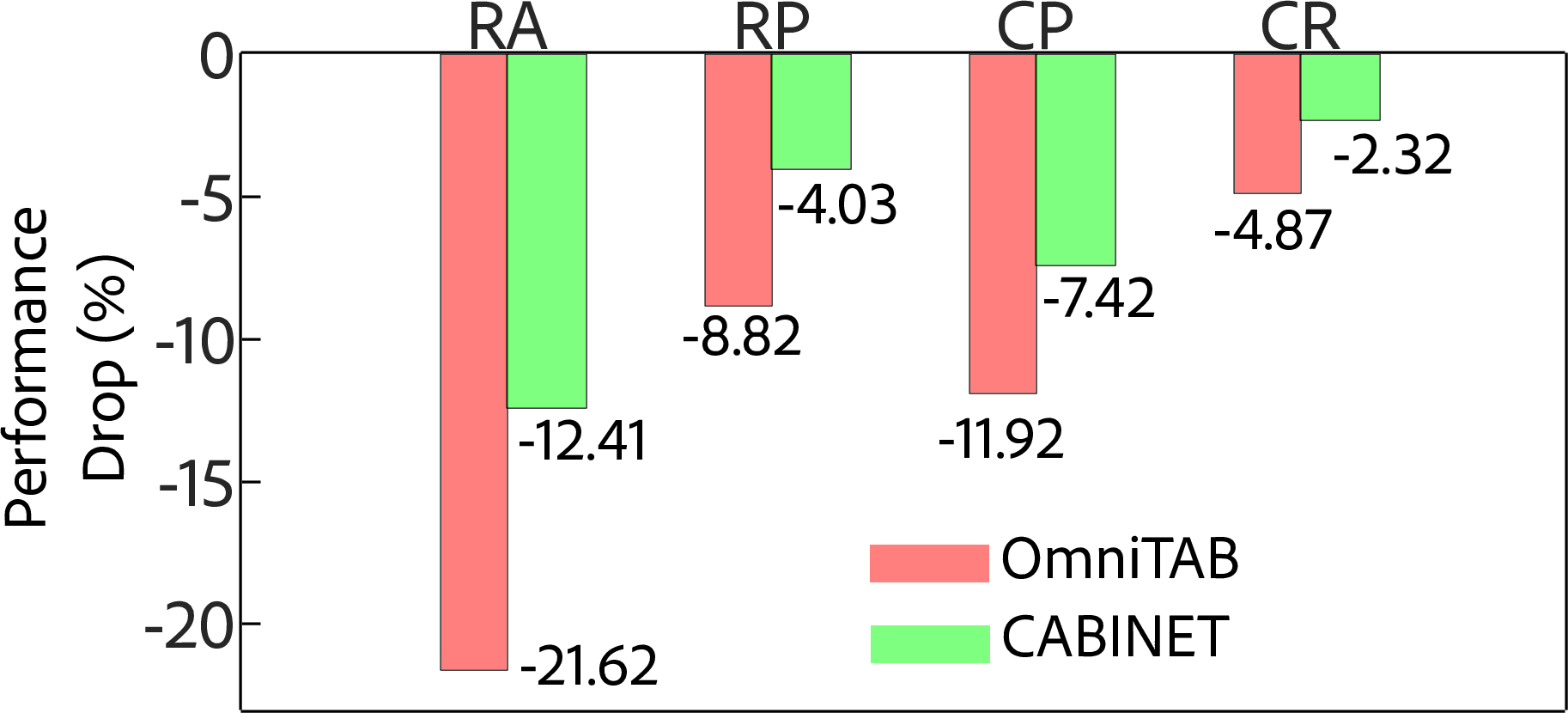
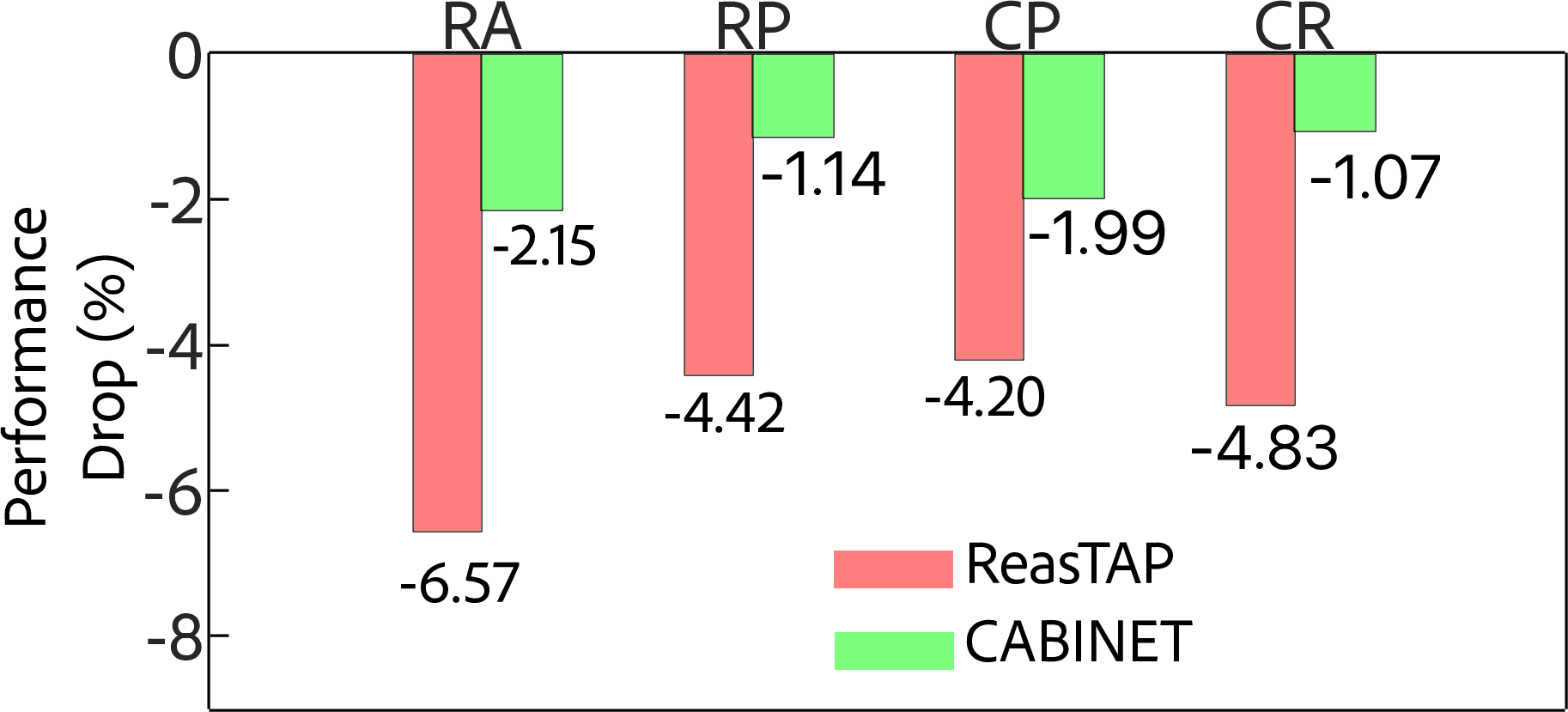
Figure 4: Performance drop comparison under various perturbations highlights CABINET's robustness against noise introduced by perturbations like Row Addition and Column Permutation.
Implications and Future Directions
CABINET's framework highlights the importance of efficiently handling large-scale tabular data, emphasizing the reduction of noise through structured embedding and cell relevance scoring. Future work can explore the integration of CABINET with alternative LLM backbones, potentially improving architectures across various NLP tasks involving tabular data. Additionally, CABINET could be leveraged to explore graph-based models capturing table structures for processing multi-sample questions.
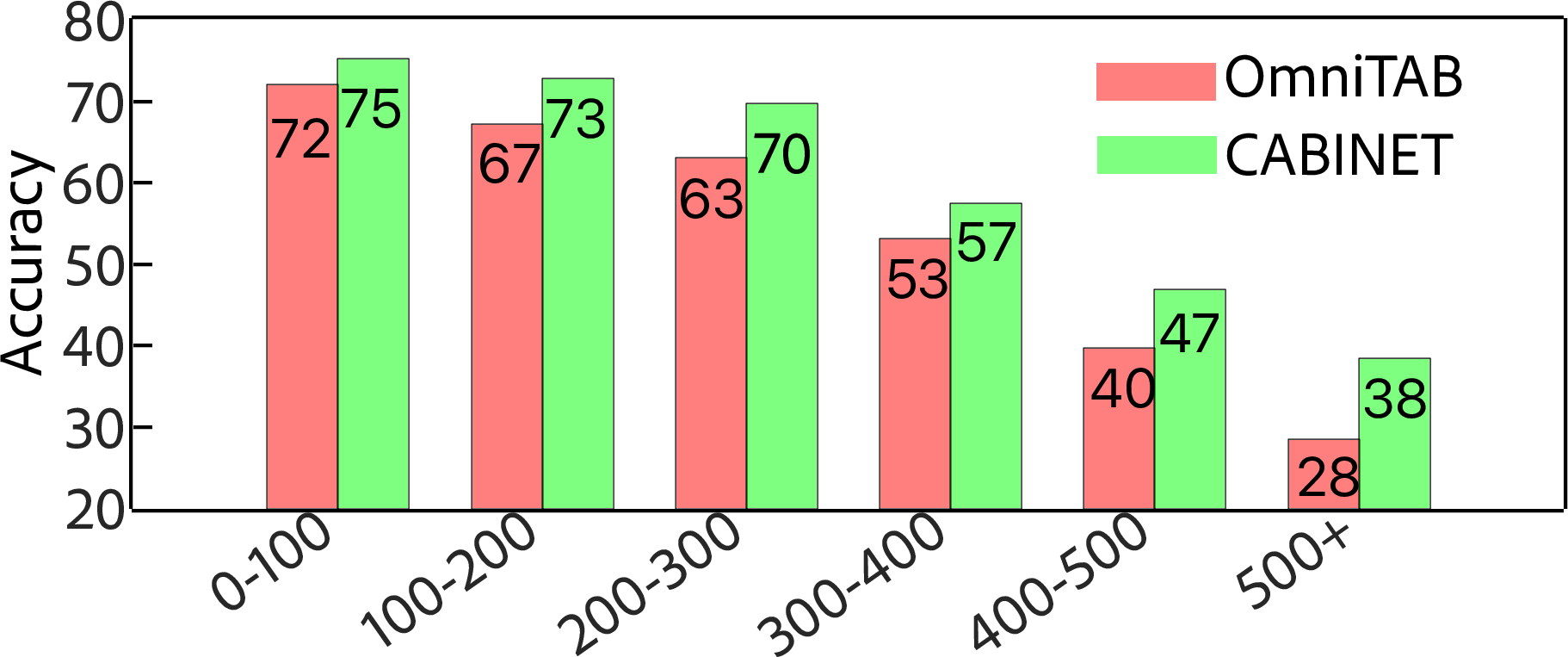
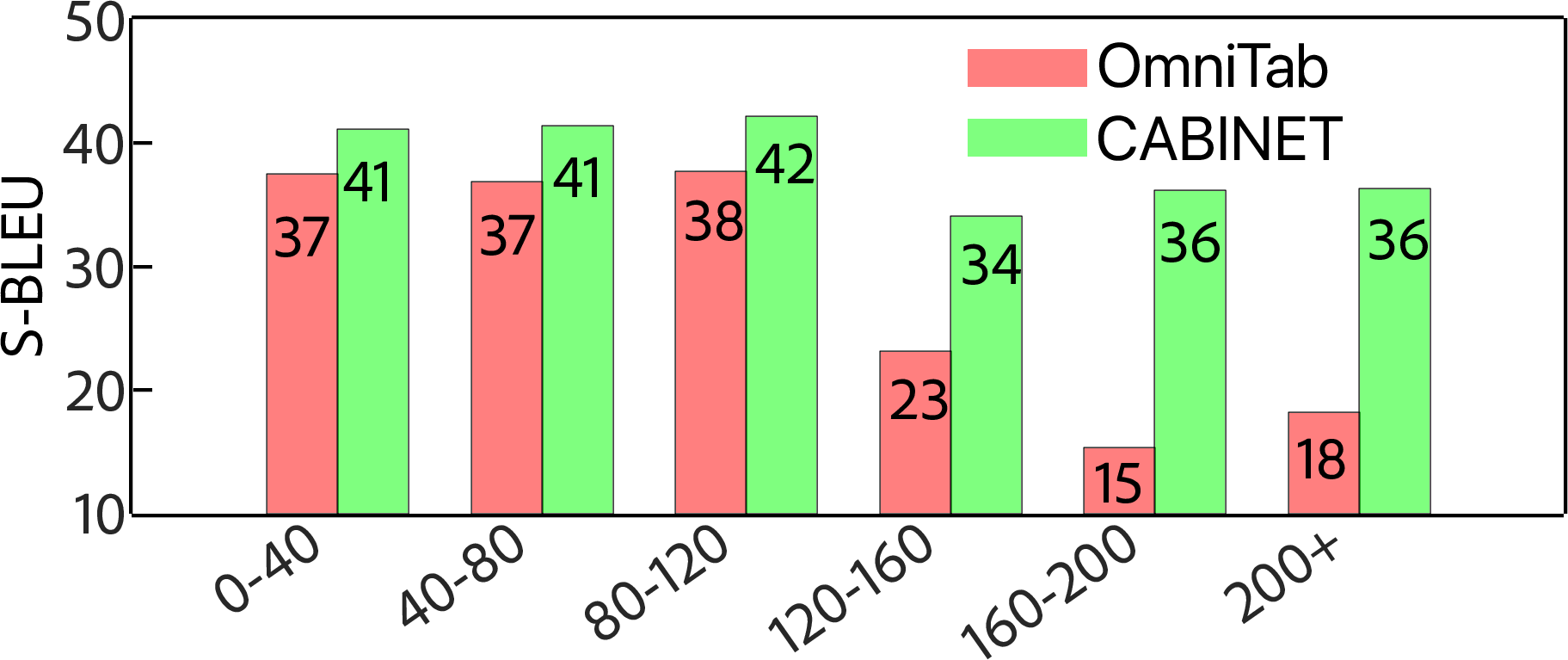
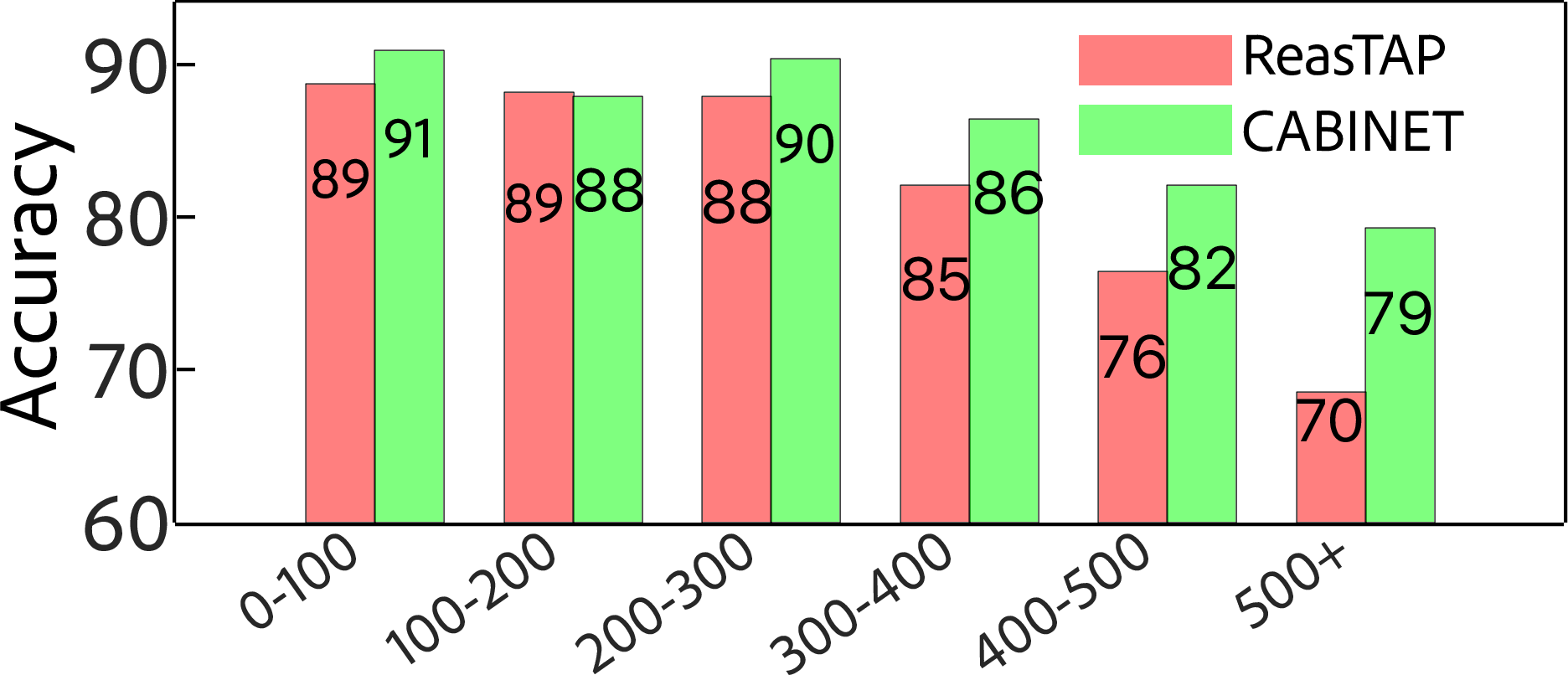
Figure 5: Performance differential of CABINET on tables of varying sizes accentuates its capability to manage noise effectively.
Conclusion
CABINET exemplifies a significant stride in refining table-based QA methodologies, ameliorating the noise vulnerabilities inherent to LLMs. By synergizing unsupervised relevance scoring with weakly supervised parsing, it achieves robust performance, setting new standards in table question answering benchmarks. As dataset sizes and complexity grow, frameworks like CABINET will be crucial in advancing AI's capabilities in reasoning over structured data.

