- The paper demonstrates that optimizing tokenizer settings yields significant improvements in compression efficiency and downstream model performance.
- Modifying vocabulary sizes and pre-tokenization rules results in faster generation speeds and better utilization of large-scale training data.
- Experimental results with 1.5B and 7B models validate that tailored tokenizers enhance inference speed and memory usage without sacrificing accuracy.
Tokenizer Optimization for Pre-training and Domain Adaptation
Tokenization plays a crucial role in the development of modern LLMs (LMs), significantly impacting generation speed, context size, and downstream performance. This essay explores various aspects of tokenizer optimization, particularly for code generation tasks, and explores the implications of different tokenizer configurations.
Introduction to Tokenization
Tokenizers transform raw text into tokens, which are the fundamental units processed by LLMs. The Byte-Pair Encoding (BPE) algorithm is widely used for this purpose, although alternatives like Unigram have also been explored. The choice of tokenizer parameters, including size, pre-tokenization rules, and training data, can have a profound effect on model efficiency and performance.
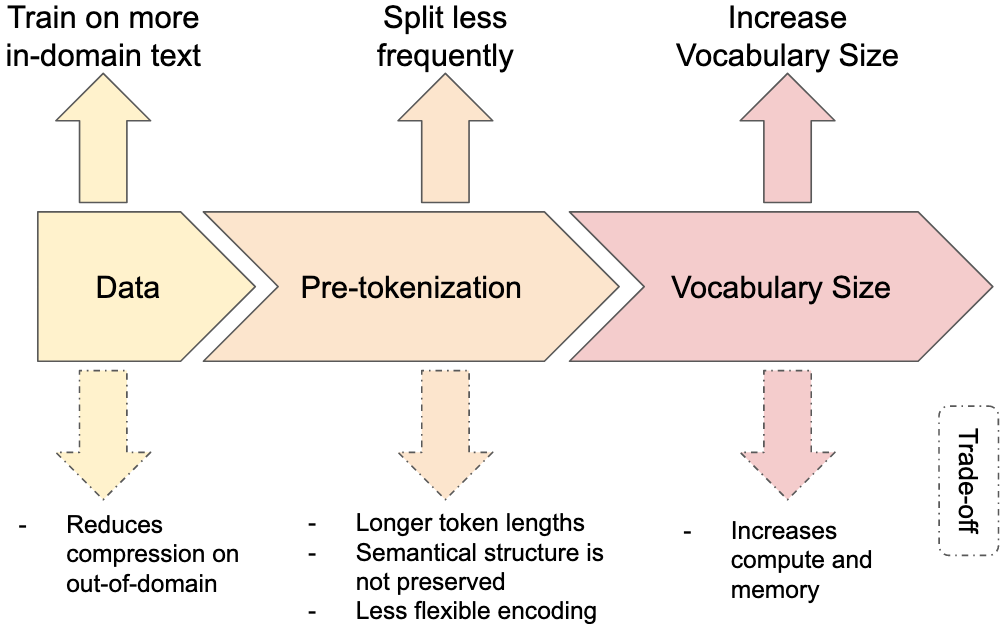
Figure 1: Three ways to increase in-domain compression in a BPE tokenizer with their respective trade-offs.
Tokenizer Compression Trade-offs
Compression Metrics
Efficiency of a tokenizer is often measured in terms of compression metrics like Normalized Sequence Length (NSL) and Bytes per Token. NSL compares the length of sequences produced by a tokenizer against a baseline (e.g., Llama tokenizer), offering insight into how compactly data is represented.
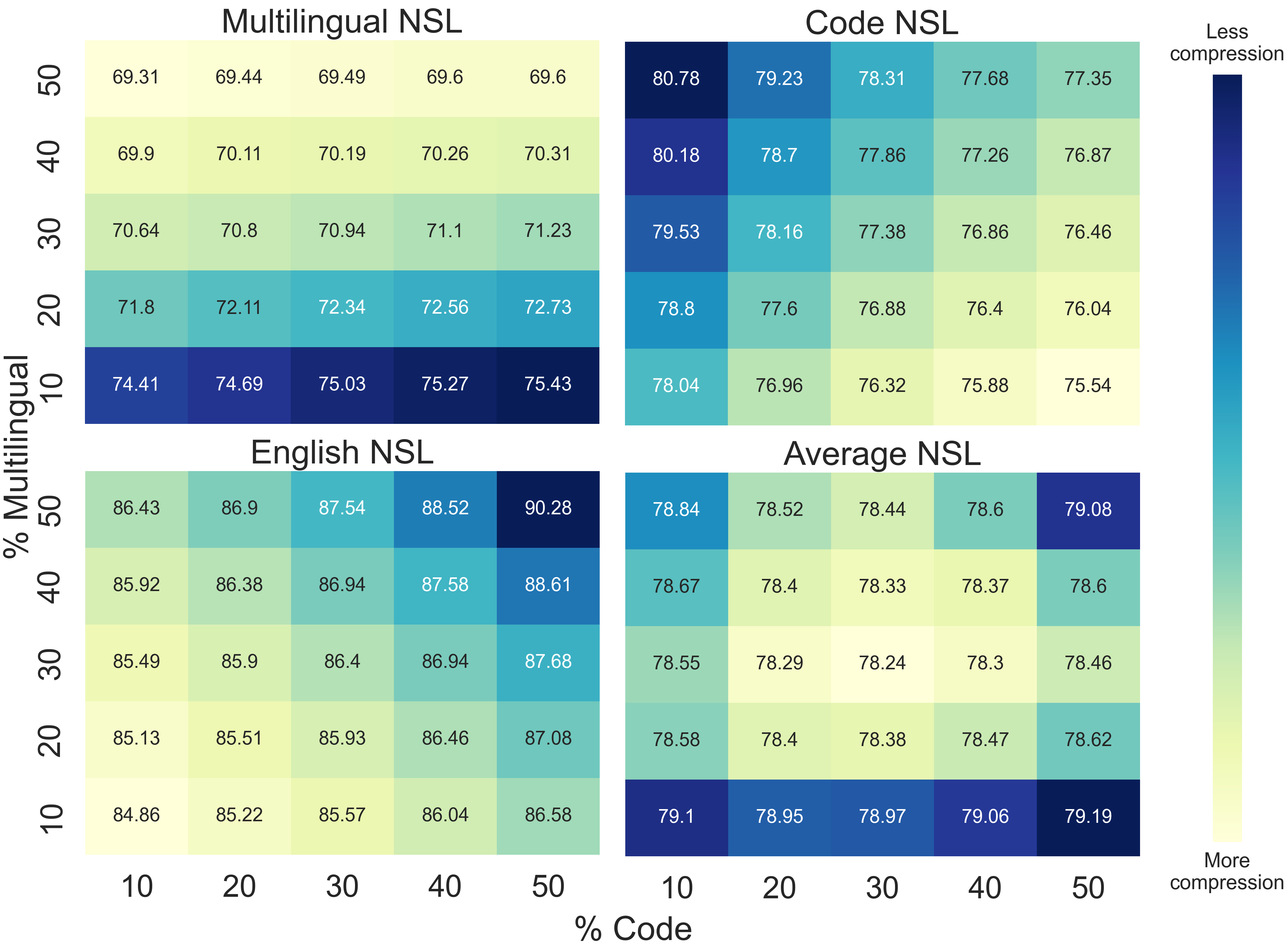
Figure 2: Tokenizers trained with different \% of code, English, multilingual data. Unsurprisingly, training on code improves code compression, training on multilingual data improves multilingual compression, and training on an even mix of all three subset leads to the best average compression.
Pre-tokenization and Vocabulary Size
Pre-tokenization schemes, typically defined by regular expressions, segment text into manageable chunks before BPE processing. This step is crucial for ensuring that learned tokens are both meaningful and reusable. Larger vocabulary sizes generally improve compression but can increase computational costs.
Experimental Analysis
Experiments were conducted on 1.5B and 7B parameter models, evaluating the impact of different tokenizers on code generation tasks such as HumanEval and MBPP. Tokenizers like the Identity, GPT-4, and Punct were assessed for their compression efficiency and impact on downstream performance.
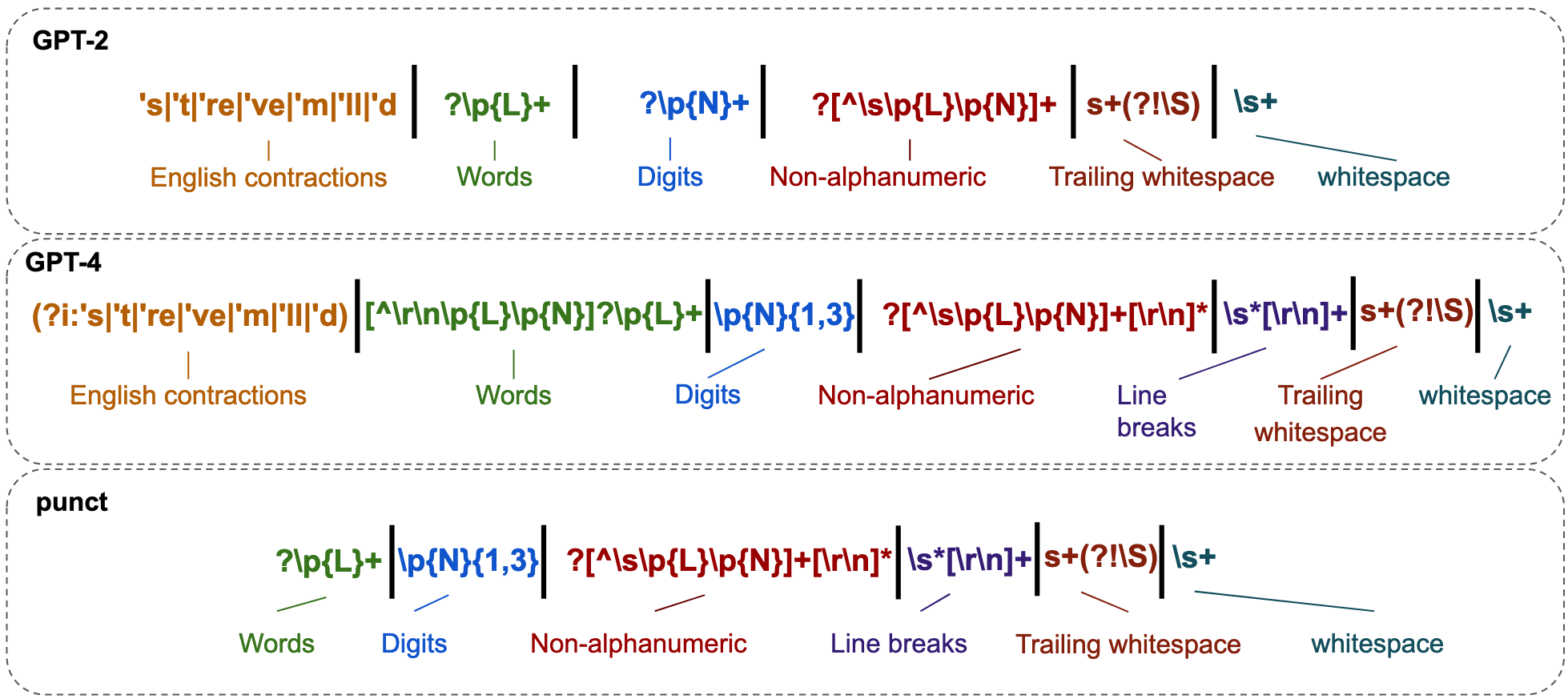
Figure 3: The GPT-2 and GPT-4 pre-tokenization regular expressions decomposed into functional sub-parts, comparing with a simplified version.
Optimal Vocabulary and Pre-tokenization
The experiments indicate that altering a tokenizer can yield substantial gains in efficiency without sacrificing performance, provided the model is exposed to sufficient training data (over 50B tokens). Models fine-tuned with modified tokenizers demonstrated improved compression rates, translating to faster generation speeds and better context utilization.


Figure 4: (top left) For given fixed set of tokenizer settings, we measure the Code NSL of different vocabulary sizes. We set the reference point to the tokenizer trained @32k tokens to compare against. (top middle) We measure the inference time for a set of vocabulary sizes and models with a fixed sequence length of 4096, and plot a linear regression over observations. We normalize predictions to a vocab of 32k. (top right) By combining the compression and inference time trade-offs, we obtain a simple cost function that describes an optimal inference time. (bottom) We use equation to find the memory optimal vocabulary size for different models. Llama 2~34B uses grouped-query attention, which significantly reduces the cache's memory usage and the memory-optimal vocabulary size.
Influence of Tokenizer Size
Varying the vocabulary size from 32k to 256k revealed minimal impact on downstream performance, suggesting that size increases can be leveraged to optimize other metrics like inference speed and memory usage. This finds particular relevance in larger models where the vocab-to-parameter ratio becomes less significant.
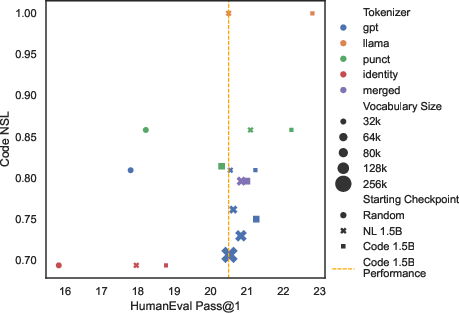
Figure 5: Performance vs Code NSL. We plot the HumanEval Pass@1 performance against Code NSL for our 1.5B LLMs fine-tuned with different base models and tokenizers.
Practical Implications and Future Directions
This study highlights the significant, often underappreciated impact of tokenizer design on LLM performance. By carefully selecting and tuning tokenizer parameters, practitioners can achieve considerable improvements in efficiency, crucial for scaling applications. Future research will likely explore more adaptive tokenization strategies that dynamically adjust based on input characteristics or task requirements.
Conclusion
Tokenizers are vital components that shape the effectiveness of LLMs. Through careful optimization of tokenizer attributes such as size and training data, it is possible to unlock substantial gains in computational efficiency and task performance. Consequently, this work advocates for a reevaluation of default tokenization practices, particularly in domain-specific applications like code generation, to fully harness the potential benefits.

