- The paper introduces UltraTool, a novel benchmark that evaluates LLMs’ abilities to plan, create, and use tools effectively in complex, real-world scenarios.
- It employs a multi-dimensional framework across 22 domains with 5,824 examples to assess planning methodologies, tool creation, and usage accuracy.
- Results indicate that larger models like GPT-4 outperform smaller ones, with language orientation and JSON formatting significantly impacting tool utilization.
Introduction
The paper "Planning, Creation, Usage: Benchmarking LLMs for Comprehensive Tool Utilization in Real-World Complex Scenarios" (2401.17167) introduces UltraTool, a robust benchmark aimed at assessing the capabilities of LLMs in tool utilization across real-world complex scenarios. Unlike existing benchmarks that rely on synthetic queries and pre-defined toolsets, UltraTool emphasizes the complexity inherent in real-life applications, focusing on the entire process of using tools characterized by planning, creating, and utilizing them efficiently. This multifaceted approach aims to map out intermediate steps for task-solving without restrictions imposed by predefined tools.
UltraTool is structured to evaluate LLMs based on their ability to conduct comprehensive tool utilization through multiple dimensions:
- Planning: UltraTool requires models to engage in precise, logical, multi-step planning within natural language frameworks before proceeding with tool applications, ensuring that complex problems are decomposed into manageable sub-tasks.
- Tool Creation: The benchmarks assess LLMs' awareness regarding the sufficiency of existing tools and their capability to craft new tools when necessary, facilitating effective task solutions that might demand tool creation beyond predefined sets.
- Tool Usage: This dimension evaluates three essential aspects: tool use awareness, tool selection appropriateness, and the proper specification of input parameters for tool execution.
UltraTool spans 22 distinct domains and incorporates a dataset consisting of 5,824 examples, each accompanied by extensive tool instructions, challenging the LLMs to demonstrate adaptability over diverse and complex queries.
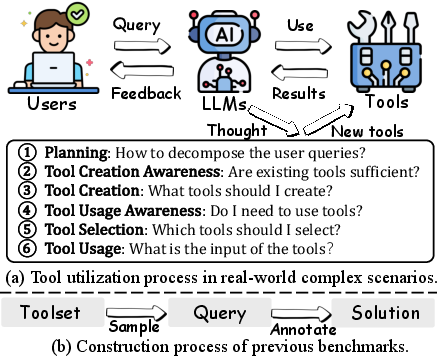
Figure 1: Illustration of (a) tool utilization process in real-world complex scenarios and (b) construction process of previous benchmarks.
Results and Analysis
In evaluating various LLMs, including both open-source models like LLaMA2 and closed-source ones like GPT-4, UltraTool offers insightful revelations into tool utilization capabilities:
- Performance Metrics: GPT-4 notably excels across both planning and tool creation dimensions, achieving the highest overall scores. Smaller-scale models, while syntactically sound, often lag in comprehensive query understanding and executional robustness.
- Model Scale: There is a direct correlation observed between model scale and tool utilization ability, reinforcing the idea that larger model architectures generally demonstrate enhanced performance capabilities.
- Language Variability: Language orientation significantly affects performance, with Chinese-oriented LLMs generally performing better on Chinese datasets, and similarly for English-directed models.
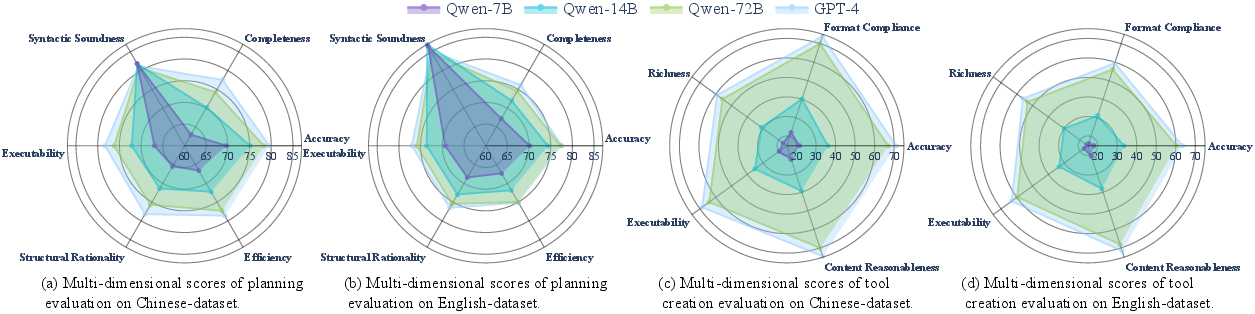
Figure 2: Multi-dimensional scores of planning and tool creation evaluation of 4 representative models under different model scales, including: Qwen-7B, Qwen-14B, Qwen-72B, and GPT-4.
Error Analysis and Metrics
Error analysis identified five major error types including instruction non-adherence, hallucination outputs, redundant content generation, incomplete outputs, and incorrect JSON formatting. The JSON format correctness rates of the models demonstrate a close alignment with overall performance, suggesting that maintaining format compliance is crucial for effective tool utilization.
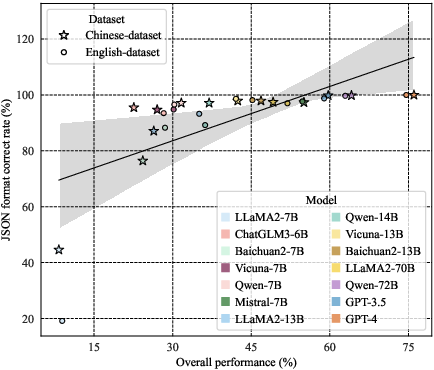
Figure 3: Correlation between JSON format correct rate with the overall score in \tablename~\ref{tab:main}.
Implications and Future Directions
UltraTool sets the stage for profound developments in LLMs' real-world tool utilization. By providing a more nuanced, multi-dimensional evaluation framework, it underscores the need for advancements in LLM capabilities surrounding tool creation and accurate execution. The results highlight areas for significant improvement, especially in comprehensive understanding and response accuracy.
The benchmark not only stimulates further research into sophisticated applications of LLMs for tool interaction but also propels the field towards refining models’ capabilities to adeptly navigate real-world complexities.
Conclusion
UltraTool represents a significant step in evaluating and enhancing LLM tool utilization capabilities by addressing the real-world complexities of planning, creation, and application. It serves as a foundational platform for future explorations and improvements in tool-related LLM functionalities, underlining the necessity for meticulous design and execution abilities in complex scenarios.

