- The paper introduces CRUD-RAG, a novel benchmark that evaluates RAG systems using distinct Chinese datasets for Create, Read, Update, and Delete tasks.
- It employs large-scale Chinese news datasets and comprehensive metrics like BLEU, ROUGE, and RAGQuestEval to assess retrieval and generation performance.
- Experiments highlight optimal settings such as larger top-k values and GPT-4’s superior performance, guiding advancements in RAG systems.
CRUD-RAG: A Comprehensive Chinese Benchmark for Retrieval-Augmented Generation of LLMs
Introduction
The paper "CRUD-RAG: A Comprehensive Chinese Benchmark for Retrieval-Augmented Generation of LLMs" introduces a novel benchmark designed to evaluate Retrieval-Augmented Generation (RAG) systems in diverse application scenarios. The RAG framework enhances LLMs by integrating external knowledge, addressing limitations such as outdated information and hallucinated content. However, existing benchmarks focus predominantly on question-answering tasks, overlooking other applications, and often assess only the LLM component. This paper addresses these gaps with a benchmark encompassing Create, Read, Update, and Delete (CRUD) categories, reflecting the variety of RAG applications.
Benchmark Overview
CRUD-RAG categorizes RAG tasks into CRUD actions: Create, Read, Update, and Delete, each representing different interactions with knowledge bases:
- Create: Involves generating original content by enriching input text with relevant external information.
- Read: Focuses on extracting and synthesizing knowledge to address complex questions and problems.
- Update: Involves correcting or revising existing information for accuracy and consistency.
- Delete: Concerns summarizing or simplifying information by removing redundancy.

Figure 1: We have classified the application scenarios of RAG into four primary aspects: Create, Read, Update, and Delete. The figure provides an illustrative example for each category, showcasing the wide-ranging potential of RAG technology.
The CRUD-RAG benchmark provides a comprehensive evaluation framework for RAG systems across these scenarios, with dedicated datasets and tasks for each category. These datasets are crucial for assessing the performance of various RAG components, such as retrieval algorithms and LLMs.
Datasets and Evaluation
The paper constructs large-scale datasets covering multiple tasks: text continuation, single and multi-document question answering, hallucination modification, and multi-document summarization. These datasets are generated from high-quality Chinese news articles, ensuring that they challenge the RAG system's ability to integrate external information rather than rely solely on internal knowledge.
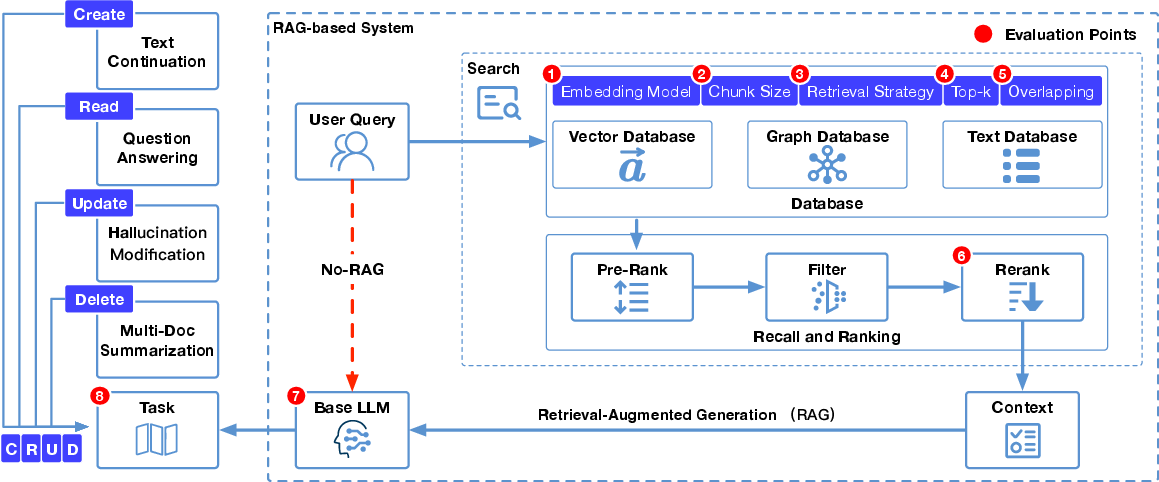
Figure 2: Illustration of CRUD-RAG, our comprehensive Chinese benchmark for RAG. It classifies the RAG application scenarios into four categories: create, read, update, and delete. For each category, we create appropriate evaluation tasks and datasets. In the experiments, we evaluate various components of the RAG system using our benchmarks.
Evaluation employs both overall semantic similarity metrics (e.g., BLEU, ROUGE, BERTScore) and key information metrics (RAGQuestEval) to comprehensively assess the quality of RAG-generated outputs. RAGQuestEval, an adaptation of existing QA-based evaluation metrics, measures the factual consistency by comparing generated responses with ground truth answers.
Experimental Analysis
The paper presents a meticulous experimental analysis of CRUD-RAG, exploring how each RAG system component—chunk size, chunk overlap, embedding model, retriever, top-k value, and LLM selection—impacts performance:
- Chunk Size and Overlap: Larger chunks preserve document structure crucial for certain tasks, while appropriate overlap maintains coherence.
- Retrievers: Dense retrievals outperform BM25 for tasks requiring semantic understanding; hybrid retrieval with reranking achieves superior results.
- Embedding Models: Performance varies by task, with m3e-base excelling in correction tasks despite ranking lower on retrieval benchmarks.
- Top-k: Larger top-k values enhance content diversity, beneficial for creative tasks while balancing between precision and recall in other scenarios.
- LLM Selection: GPT-4 consistently excels, outperforming other models across most metrics, but alternatives like Qwen-14B and Baichuan2-13B offer competitive performance in specific tasks.
Conclusion
This paper introduces CRUD-RAG, a pioneering benchmark for evaluating RAG systems, emphasizing the integration of external knowledge in LLMs across various scenarios. By incorporating diverse CRUD tasks and extensive datasets, CRUD-RAG provides critical insights for fine-tuning LLMs and RAG components, advancing the development of retrieval-augmented LLMs. The benchmark framework and its findings offer a significant contribution towards understanding and optimizing RAG systems, guiding future research in improving text generation and enhancing the fidelity of information retrieval.