- The paper demonstrates that Expert Choice routers excel in sparse MoE configurations, significantly improving accuracy in image classification tasks.
- It introduces a unified MoE layer formulation using dispatch and combine tensors to systematically compare sparse and soft routing mechanisms.
- Experimental evaluations reveal that soft MoE routers enhance computational efficiency and scalability, reducing training times on large-scale datasets like JFT300M.
Routers in Vision Mixture of Experts: An Empirical Study
The paper "Routers in Vision Mixture of Experts: An Empirical Study" explores the design and impact of router algorithms within Mixture of Experts (MoE) models applied to computer vision tasks. The MoE architectures propose a strategy to enhance model capacity efficiently while managing computational costs.
Mixture of Experts in Vision
Mixture-of-Experts models segregate parameters (experts) into subsets, determined by routers, which allocate feature embeddings (tokens) to these experts. In this study, a unified MoE structure is generated through parametric routing tensors, allowing for the comparison of both sparse and soft MoEs. The sparse models feature either a binary assignment (hard) or a direct parameterization using expert-choice and token-choice techniques. The outcomes demonstrate that routers initially created for LLMs adapt effectively to vision tasks, with distinct differences in performance noted between token-choice and expert-choice routing schemes.
The authors present a modular formulation for MoE layers, characterized by two parametric routing tensors: the dispatch and combine tensors. These tensors encompass the sparse and soft MoE paradigms, offering a comprehensive framework for examining different router implementations. Sparse MoE layers manifest through specific binary selections of expert-token interactions, while soft MoEs leverage weighted linear combinations, presenting a broader token utilization spectrum.
Evaluation of Router Variants
Conducted experiments involved six router variations, including adaptations from textual models and newly devised structures. The findings underscore that:
- Expert Choice routers consistently outperform Token Choice routers in sparse MoE configurations.
- Soft MoE configurations demonstrate superior results in accuracy and computational efficiency under set compute constraints.
- There exists a clear computational advantage in managing router distribution strategies.
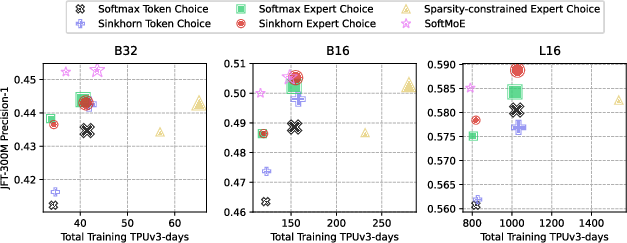
Figure 1: Comparison of training time and performance in the JFT300M dataset for image classification. The marker size represents the router's capacity, with smaller and larger sizes indicating lower and higher capacities.

Figure 2: Comparison of training time and performance in a 10-shot Transfer Task on the ImageNet-1k Dataset. The marker size represents the router's capacity, with smaller and larger sizes indicating lower and higher capacities.
The paper offers extensive experimental results:
- In large-scale training on the JFT-300M dataset, Expert Choice routers present distinct accuracy gains over Token Choice routers.
- Soft MoE routers excel in computational trade-offs, exhibiting reduced training times with higher accuracy yields.
- The use of Sinkhorn’s algorithm effectively balances expert utilization in token choice schemes, leading to enhanced performance without auxiliary losses.
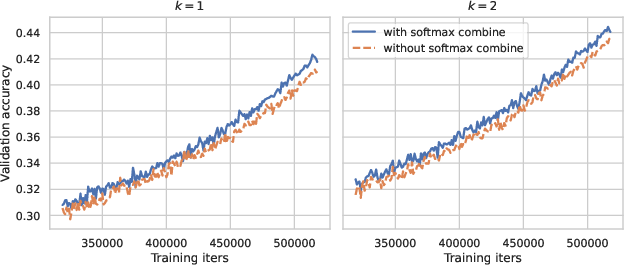
Figure 3: Assessing the impact of using Softmax-based combine tensors in Sinkhorn Token Choice routers. The number of selected expets are k=1 (left panel) and k=2 (right panel). Both routers are used in a B32 architecture. The x axis shows the training iteration number, while the y axis shows the validation accuracy on the JFT300M dataset.
Conclusion
The examination conclusively highlights the efficiency and scalability of vision-specific MoE routers. Empirical studies confirm that soft MoEs deliver substantial benefits over sparse alternatives in terms of computational economy and performance, making them highly promising for expansive datasets and future research endeavors in computer vision. The paper lays the groundwork for potential developments in optimizing router functions, particularly in the evolving landscape of image recognition and analysis.

