- The paper presents a Relation-based CKA (RCKA) framework that reinterprets CKA as the upper bound of Maximum Mean Discrepancy (MMD) to enhance knowledge distillation.
- The methodology incorporates a Patch-based CKA (PCKA) approach to improve object detection performance by efficiently addressing small batch sizes through feature patch segmentation.
- Empirical results on benchmarks like CIFAR-100, ImageNet-1k, and MS-COCO demonstrate that RCKA and PCKA offer state-of-the-art distillation quality while reducing computational demands.
"Rethinking Centered Kernel Alignment in Knowledge Distillation" (2401.11824)
Introduction
Knowledge distillation (KD) has established itself as a compelling technique for transferring knowledge from large, complex models to more efficient, lightweight models, enhancing their performance without the computational burdens of their larger counterparts. Traditional approaches in KD have primarily focused on leveraging different metrics to minimize the divergence between teacher and student models. A key advancement in this area is the incorporation of Centered Kernel Alignment (CKA) for measuring representational similarity, which emphasizes both model predictions and high-order feature representations.
The paper introduces a novel Relation-based Centered Kernel Alignment (RCKA) framework, which reinterprets CKA in terms of Maximum Mean Discrepancy (MMD), bringing theoretical clarity to the efficacy of CKA in KD. The proposed RCKA framework aims to maintain task-specific adaptability while reducing computational demands compared to existing methods.
Theoretical Insights
CKA is shown to be an effective tool for assessing similarity between neural network representations. However, the paper provides a new theoretical perspective, wherein CKA is reinterpreted as the upper bound of MMD plus a constant term. This theoretical underpinning not only elucidates why CKA is effective but also aligns the CKA metric with a robust mathematical foundation, demonstrating that optimizing CKA translates to minimizing MMD under certain constraints.
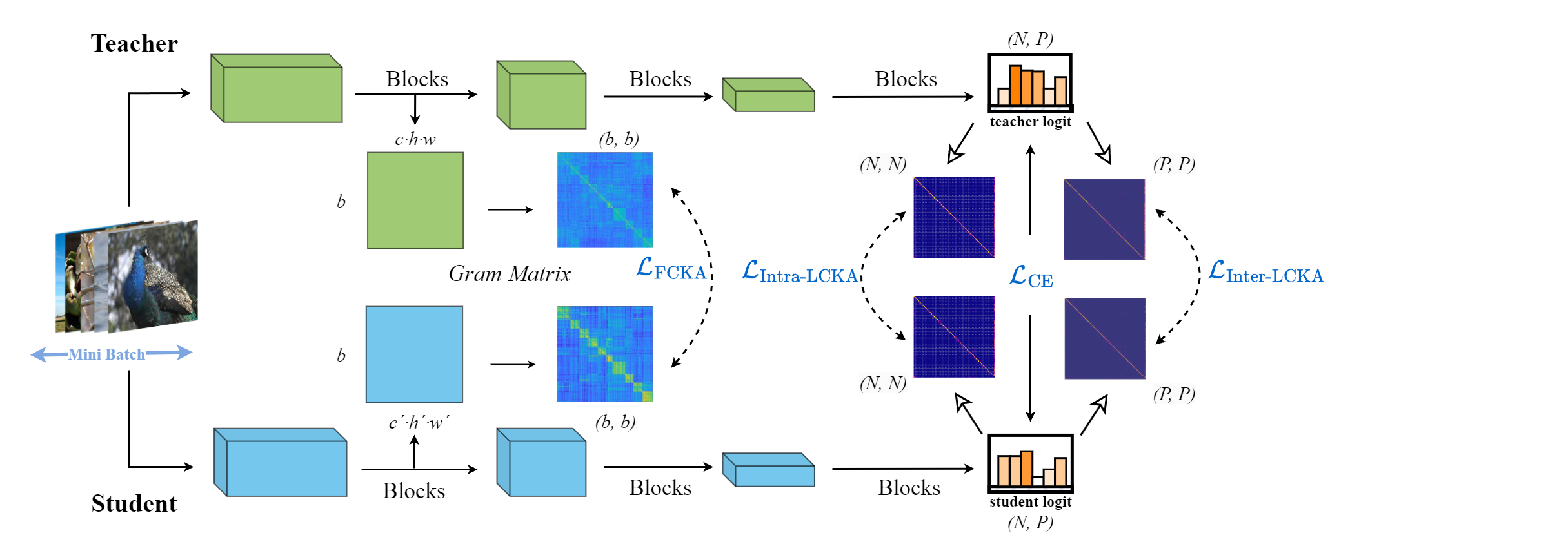
Figure 1: The overall framework of the proposed Relation-based Centered Kernel Alignment (RCKA).
This interpretation provides significant insights: MMD acts as a measure of distributional similarity between datasets, and decoupling it into CKA offers a scalable solution suitable for diverse KD scenarios.
Methodology
Building on the theorizations of CKA, the RCKA framework facilitates dynamic customization of KD applications across different tasks with minimal computational resources. RCKA employs CKA as a loss function to encourage students to mimic the centered similarity matrices, thereby capturing essential features rather than merely aligning scale-sensitive matrices.
Furthermore, the framework introduces a Patch-based Centered Kernel Alignment (PCKA) approach for instance-specific tasks like object detection. PCKA addresses the challenges of small batch sizes by segmenting feature maps into patches, thereby capturing patch-wise similarities that are computationally feasible and enhance the distillation process.
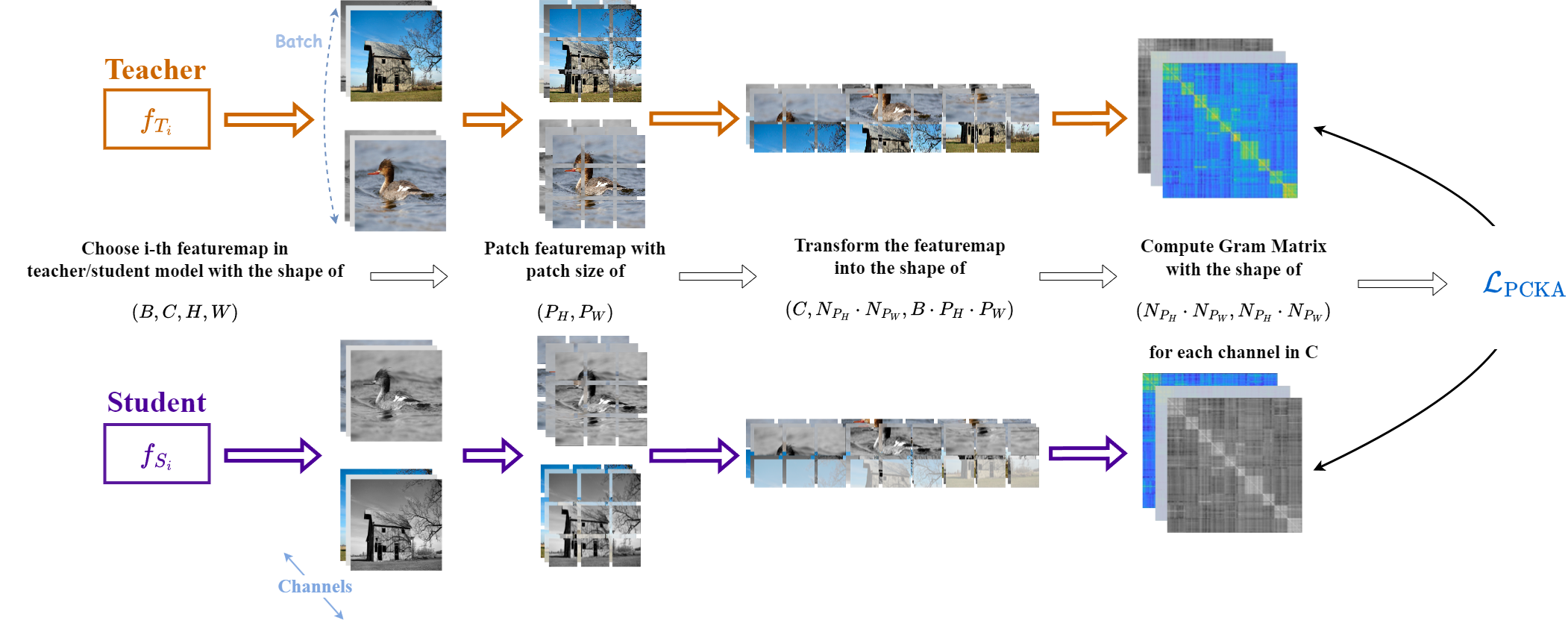
Figure 2: The overall framework of PCKA.
Experimental Validation
The empirical evaluation of RCKA and PCKA on benchmarks such as CIFAR-100, ImageNet-1k, and MS-COCO validates their efficacy in achieving state-of-the-art performance. The frameworks effectively balance computational resources with distillation quality, avoiding the complexities and overheads of previous methods.
PCKA, in particular, demonstrates marked improvements in object detection tasks by harnessing high-order representations between teacher and student model patches, a strategy less explored by previous methods.
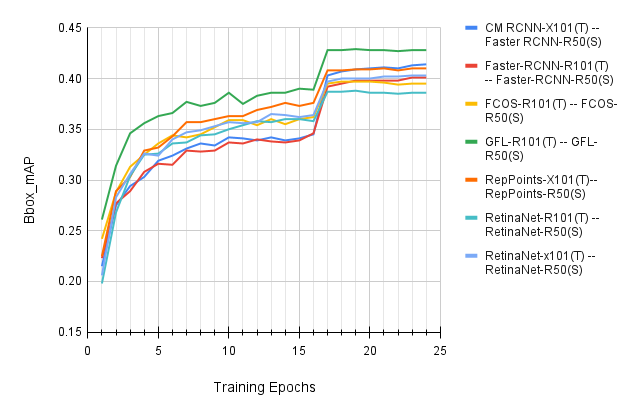
Figure 3: Training process visualization of all experimented detectors.
Conclusion and Future Work
The paper offers a comprehensive rethink of CKA within KD, enhancing both theoretical understanding and practical implementation. By recasting CKA in terms of MMD, the work bridges existing gaps in the field, providing a solid foundation for future enhancements in efficient model compression techniques.
Future endeavors might focus on broadening the theoretical relationship among various similarity metrics in KD and further exploiting the observed benefits of channel dimension averaging and patch processing. This work underscores the importance of continued innovation in knowledge transfer methodologies, bearing implications for a range of AI applications seeking to balance model performance with resource constraints.