CaraServe: CPU-Assisted and Rank-Aware LoRA Serving for Generative LLM Inference
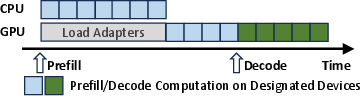
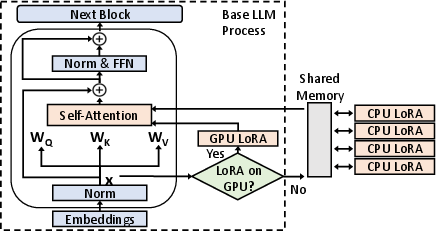
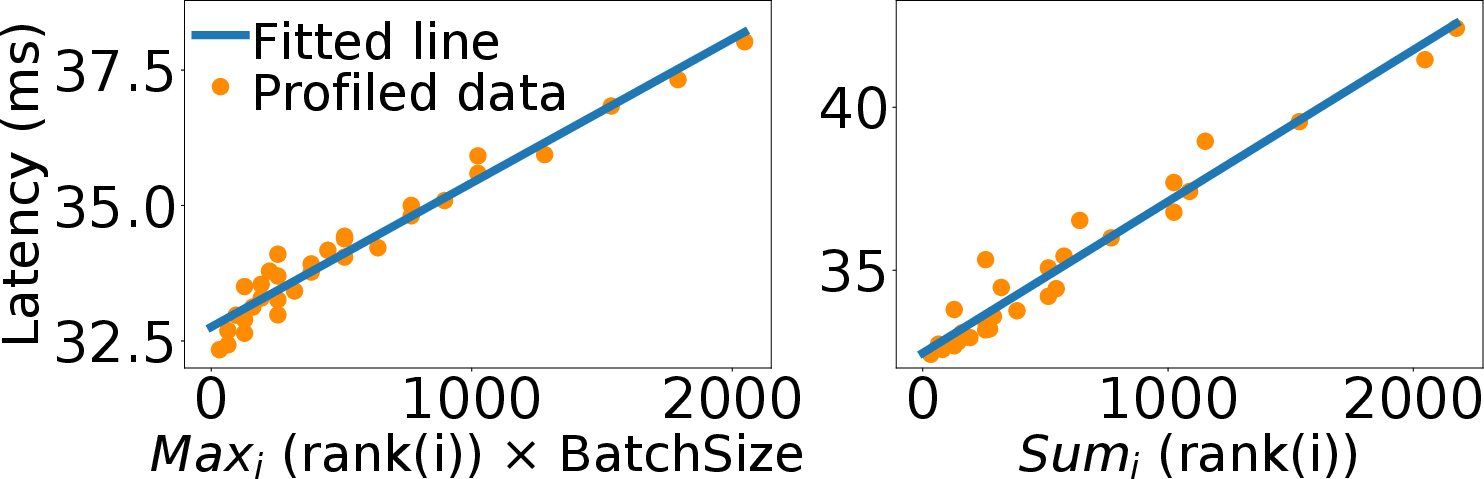
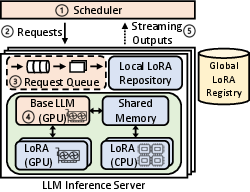
Abstract: Pre-trained LLMs often need specialization for domain-specific tasks. Low-Rank Adaptation (LoRA) is a popular approach that adapts a base model to multiple tasks by adding lightweight trainable adapters. In this paper, we present CaraServe, a system that efficiently serves many LoRA adapters derived from a common base model. CaraServe maintains the base model on GPUs and dynamically loads activated LoRA adapters from main memory. As GPU loading results in a cold-start that substantially delays token generation, CaraServe employs a CPU-assisted approach. It early starts the activated adapters on CPUs for prefilling as they are being loaded onto GPUs; after loading completes, it then switches to the GPUs for generative LoRA inference. CaraServe develops a highly optimized synchronization mechanism to efficiently coordinate LoRA computation on the CPU and GPU. Moreover, CaraServe employs a rank-aware scheduling algorithm to optimally schedule heterogeneous LoRA requests for maximum service-level objective (SLO) attainment. We have implemented CaraServe and evaluated it against state-of-the-art LoRA serving systems. Our results demonstrate that CaraServe can speed up the average request serving latency by up to 1.4$\times$ and achieve an SLO attainment of up to 99%.
- Punica: Multi-tenant lora serving, 2023.
- Longlora: Efficient fine-tuning of long-context large language models. arXiv:2309.12307, 2023.
- Clipper: A {{\{{Low-Latency}}\}} online prediction serving system. In 14th USENIX Symposium on Networked Systems Design and Implementation (NSDI 17), pages 613–627, 2017.
- Databricks. Llm inference performance engineering: Best practices. https://www.databricks.com/blog/llm-inference-performance-engineering-best-practices, 2023.
- Qlora: Efficient finetuning of quantized llms. In Advances in Neural Information Processing Systems, 2023.
- Nvidia Developer. Nvidia nsight compute. https://developer.nvidia.com/nsight-compute, 2024.
- PyTorch Docs. Cpu threading and torchscript inference. https://pytorch.org/docs/stable/notes/cpu_threading_torchscript_inference.html#runtime-api, 2023.
- Serving DNNs like clockwork: Performance predictability from the bottom up. In 14th USENIX Symposium on Operating Systems Design and Implementation (OSDI 20), pages 443–462. USENIX Association, November 2020.
- LoRA: Low-rank adaptation of large language models. In International Conference on Learning Representations, 2022.
- Huggingface. Text generation inference. https://github.com/huggingface/text-generation-inference.
- Efficient memory management for large language model serving with pagedattention. In Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles, 2023.
- AlpaServe: Statistical multiplexing with model parallelism for deep learning serving. In 17th USENIX Symposium on Operating Systems Design and Implementation (OSDI 23), pages 663–679, Boston, MA, July 2023. USENIX Association.
- ORION and the three rights: Sizing, bundling, and prewarming for serverless DAGs. In 16th USENIX Symposium on Operating Systems Design and Implementation (OSDI 22), pages 303–320, Carlsbad, CA, July 2022. USENIX Association.
- Peft: State-of-the-art parameter-efficient fine-tuning methods. https://github.com/huggingface/peft, 2022.
- Spotserve: Serving generative large language models on preemptible instances. In ASPLOS, 2024.
- ModelTC. Light llm. https://github.com/ModelTC/lightllm.
- OpenAI. Custom instructions for chatgpt. https://openai.com/blog/custom-instructions-for-chatgpt, 2023.
- OpenAI. Gpt-3.5 turbo fine-tuning and api updates. https://openai.com/blog/gpt-3-5-turbo-fine-tuning-and-api-updates, 2023.
- Pytorch: An imperative style, high-performance deep learning library. Advances in neural information processing systems, 32, 2019.
- INFaaS: Automated model-less inference serving. In 2021 USENIX Annual Technical Conference (USENIX ATC 21), pages 397–411. USENIX Association, July 2021.
- Serverless in the wild: Characterizing and optimizing the serverless workload at a large cloud provider. In 2020 USENIX Annual Technical Conference (USENIX ATC 20), 2020.
- Nexus: A gpu cluster engine for accelerating dnn-based video analysis. In Proceedings of the 27th ACM Symposium on Operating Systems Principles, pages 322–337, 2019.
- S-lora: Serving thousands of concurrent lora adapters, 2023.
- Flexgen: High-throughput generative inference of large language models with a single gpu. In International Conference on Machine Learning, pages 31094–31116. PMLR, 2023.
- Megatron-lm: Training multi-billion parameter language models using model parallelism, 2020.
- Stanford alpaca: An instruction-following llama model. https://github.com/tatsu-lab/stanford_alpaca., 2023.
- Triton: an intermediate language and compiler for tiled neural network computations. In Proceedings of the 3rd ACM SIGPLAN International Workshop on Machine Learning and Programming Languages, pages 10–19, 2019.
- Llama 2: Open foundation and fine-tuned chat models, 2023.
- Attention is all you need. Advances in neural information processing systems, 2017.
- MLaaS in the wild: Workload analysis and scheduling in Large-Scale heterogeneous GPU clusters. In 19th USENIX Symposium on Networked Systems Design and Implementation (NSDI 22), pages 945–960, Renton, WA, April 2022. USENIX Association.
- Orca: A distributed serving system for Transformer-Based generative models. In 16th USENIX Symposium on Operating Systems Design and Implementation (OSDI 22), pages 521–538, Carlsbad, CA, July 2022. USENIX Association.
- {{\{{MArk}}\}}: Exploiting cloud services for {{\{{Cost-Effective}}\}},{{\{{SLO-Aware}}\}} machine learning inference serving. In 2019 USENIX Annual Technical Conference (USENIX ATC 19), pages 1049–1062, 2019.
- SHEPHERD: Serving DNNs in the wild. In 20th USENIX Symposium on Networked Systems Design and Implementation (NSDI 23), pages 787–808, Boston, MA, April 2023. USENIX Association.
- Opt: Open pre-trained transformer language models. arXiv preprint arXiv:2205.01068, 2022.
- PetS: A unified framework for Parameter-Efficient transformers serving. In 2022 USENIX Annual Technical Conference (USENIX ATC 22), 2022.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

