Inference without Interference: Disaggregate LLM Inference for Mixed Downstream Workloads
Abstract: Transformer-based LLM inference serving is now the backbone of many cloud services. LLM inference consists of a prefill phase and a decode phase. However, existing LLM deployment practices often overlook the distinct characteristics of these phases, leading to significant interference. To mitigate interference, our insight is to carefully schedule and group inference requests based on their characteristics. We realize this idea in TetriInfer through three pillars. First, it partitions prompts into fixed-size chunks so that the accelerator always runs close to its computationsaturated limit. Second, it disaggregates prefill and decode instances so each can run independently. Finally, it uses a smart two-level scheduling algorithm augmented with predicted resource usage to avoid decode scheduling hotspots. Results show that TetriInfer improves time-to-first-token (TTFT), job completion time (JCT), and inference efficiency in turns of performance per dollar by a large margin, e.g., it uses 38% less resources all the while lowering average TTFT and average JCT by 97% and 47%, respectively.
- Sarathi: Efficient llm inference by piggybacking decodes with chunked prefills. arXiv preprint arXiv:2308.16369, 2023.
- Deepspeed-inference: enabling efficient inference of transformer models at unprecedented scale. In SC22: International Conference for High Performance Computing, Networking, Storage and Analysis, 2022.
- AWS Bedrock. https://docs.aws.amazon.com/bedrock/latest/userguide/inference-parameters.html.
- Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374, 2021.
- Tri Dao. Flashattention-2: Faster attention with better parallelism and work partitioning. arXiv preprint arXiv:2307.08691, 2023.
- Flashattention: Fast and memory-efficient exact attention with io-awareness. Advances in Neural Information Processing Systems, 2022.
- Llm. int8 (): 8-bit matrix multiplication for transformers at scale. arXiv preprint arXiv:2208.07339, 2022.
- Spqr: A sparse-quantized representation for near-lossless llm weight compression. arXiv preprint arXiv:2306.03078, 2023.
- Towards next-generation intelligent assistants leveraging llm techniques. In Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2023.
- FaRM: Fast remote memory. In 11th USENIX Symposium on Networked Systems Design and Implementation (NSDI 14), 2014.
- Optq: Accurate quantization for generative pre-trained transformers. In The Eleventh International Conference on Learning Representations, 2022.
- Clio: A Hardware-Software Co-Designed Disaggregated Memory System. In Proceedings of the 27th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, 2022.
- HiAscend. Atlas 900 AI Cluster. https://www.hiascend.com/en/hardware/cluster.
- HiAscend. CANN aclrtMemcpy. https://www.hiascend.com/document/detail/en/canncommercial/601/inferapplicationdev/aclcppdevg/aclcppdevg_03_0081.html.
- Flashdecoding++: Faster large language model inference on gpus. arXiv preprint arXiv:2311.01282, 2023.
- HugginFace. https://huggingface.co/docs/transformers/model_doc/opt#transformers.OPTForSequenceClassification.
- Hugging Face. https://huggingface.co/datasets/ZhongshengWang/Alpaca-pubmed-summarization.
- Hugging Face. https://huggingface.co/datasets/lancexiao/write_doc_sft_v1.
- Gpt-zip: Deep compression of finetuned large language models. In Workshop on Efficient Systems for Foundation Models@ ICML2023, 2023.
- A Jo. The promise and peril of generative ai. Nature, 2023.
- Efficient memory management for large language model serving with pagedattention. In Proceedings of the 29th Symposium on Operating Systems Principles, 2023.
- Train big, then compress: Rethinking model size for efficient training and inference of transformers. In International Conference on machine learning, 2020.
- Alpaserve: Statistical multiplexing with model parallelism for deep learning serving. arXiv preprint arXiv:2302.11665, 2023.
- Rammer: Enabling holistic deep learning compiler optimizations with {{\{{rTasks}}\}}. In 14th USENIX Symposium on Operating Systems Design and Implementation (OSDI 20), 2020.
- NGINX. https://www.nginx.com/blog/nginx-power-of-two-choices-load-balancing-algorithm/.
- NVIDIA. CUDA Runtime API Memory Management. https://docs.nvidia.com/cuda/cuda-runtime-api/group__CUDART__MEMORY.html.
- NVIDIA. GPU Direct. https://developer.nvidia.com/gpudirect.
- NVIDIA. NCCL. https://docs.nvidia.com/deeplearning/nccl/user-guide/docs/overview.html.
- NVIDIA, FasterTransformer. https://github.com/NVIDIA/FasterTransformer.
- NVIDIA, Triton Inference Server. https://developer.nvidia.com/.
- Memgpt: Towards llms as operating systems. arXiv preprint arXiv:2310.08560, 2023.
- Splitwise: Efficient generative llm inference using phase splitting. arXiv preprint arXiv:2311.18677, 2023.
- Efficiently scaling transformer inference. Proceedings of Machine Learning and Systems, 2023.
- Zero-shot text-to-image generation. In International Conference on Machine Learning, 2021.
- Sharegpt teams. https://sharegpt.com/.
- Fairness in serving large language models. arXiv preprint arXiv:2401.00588, 2023.
- Flexgen: High-throughput generative inference of large language models with a single gpu. In International Conference on Machine Learning, 2023.
- Llama 2: Open foundation and fine-tuned chat models, 2023. URL https://arxiv. org/abs/2307.09288, 2023.
- Lightseq: A high performance inference library for transformers. arXiv preprint arXiv:2010.13887, 2020.
- Wikipedia. NVLink. https://en.wikipedia.org/wiki/NVLink.
- Fast distributed inference serving for large language models. arXiv preprint arXiv:2305.05920, 2023.
- Smoothquant: Accurate and efficient post-training quantization for large language models. In International Conference on Machine Learning, 2023.
- A comprehensive study on post-training quantization for large language models. arXiv preprint arXiv:2303.08302, 2023.
- Zeroquant: Efficient and affordable post-training quantization for large-scale transformers. Advances in Neural Information Processing Systems, 2022.
- Orca: A distributed serving system for {{\{{Transformer-Based}}\}} generative models. In 16th USENIX Symposium on Operating Systems Design and Implementation (OSDI 22), 2022.
- Bytetransformer: A high-performance transformer boosted for variable-length inputs. In 2023 IEEE International Parallel and Distributed Processing Symposium (IPDPS), 2023.
- Opt: Open pre-trained transformer language models. arXiv preprint arXiv:2205.01068, 2022.
- Response length perception and sequence scheduling: An llm-empowered llm inference pipeline. arXiv preprint arXiv:2305.13144, 2023.
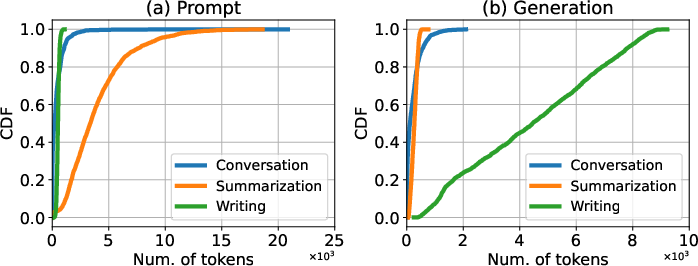
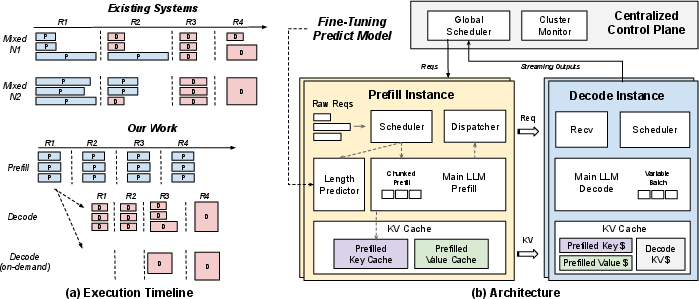
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.