- The paper introduces a safe RL controller that integrates CBFs to ensure collision-free, system-level safety for CAVs in mixed traffic.
- It employs a learning-based system identification method to adapt to unpredictable human-driven vehicle behaviors.
- Simulation results show improved traffic efficiency and expanded safety regions under high-disturbance conditions.
Enhancing System-Level Safety in Mixed-Autonomy Platoon via Safe Reinforcement Learning
Introduction
The paper "Enhancing System-Level Safety in Mixed-Autonomy Platoon via Safe Reinforcement Learning" (2401.11148) investigates the challenges of controlling connected and automated vehicles (CAVs) in mixed-autonomy traffic environments using Deep Reinforcement Learning (DRL). It addresses three significant gaps in current DRL research for CAVs: the lack of collision-free guarantees, the assumption of rational driver behavior, and the neglect of unknown human driver models. The study presents a safe DRL-based approach integrating Control Barrier Functions (CBFs) for system-level safety guarantees and proposes a learning-based system identification method for human driver behavior.
System Design and Methodology
Mixed-Autonomy Traffic Modeling
The framework considers a single CAV in a platoon of human-driven vehicles (HDVs), assuming realistic scenarios where CAV penetration remains low. The dynamics of CAVs are governed by standard acceleration models, while HDVs are simulated through car-following laws, notably the Optimal Velocity Model (OVM), with the actual parameters unknown to the CAVs. This setup enables the CAV to learn and adapt its behavior based on observed traffic patterns using a reinforcement learning framework.
Reinforcement Learning and Safety Considerations
PPO is utilized as the main RL algorithm, formulated to improve traffic efficiency, stability, and ensure safety. The innovation lies in a differentiable neural network embedding quadratic programming layers to ensure CBF-based safety constraints are met. This ensures that actions chosen by the RL agent remain within safe operational boundaries, accounting for both immediate and system-level safety constraints.
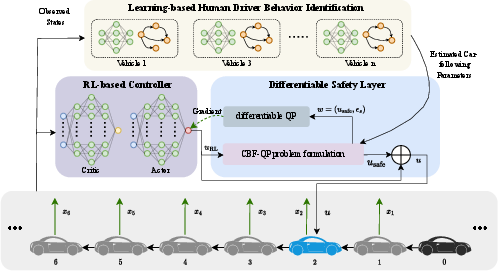
Figure 1: Overview of the proposed controller for CAVs in mixed-autonomy traffic framework, the dotted line represents backpropagation of the differentiable QP.
Learning-Based System Identification
The approach employs a hybrid system identification strategy combining linear models with neural networks to approximate and update unknown HDV behavior in real-time. This method enables CAVs to dynamically adapt to evolving traffic conditions without pre-assumed driver models, reducing system vulnerabilities to unexpected HDV actions.
Implementation and Results
Simulation Setup
Two primary scenarios were simulated: (1) where an HDV makes an emergency deceleration, and (2) where an HDV behind the CAV accelerates unexpectedly. Training incorporated realistic disturbances, engineering CAV responses to unmodeled, erratic human behaviors.
Performance Analysis
The proposed method effectively expanded safety regions and decreased collision risks under high-disturbance conditions (Figure 2), outperforming standard DRL implementations by a significant margin. The impacts on traffic efficiency and system-level stability were quantified, showing marked improvements over traditional approaches, particularly in mitigating adverse effects from disregard for HDV interactions.
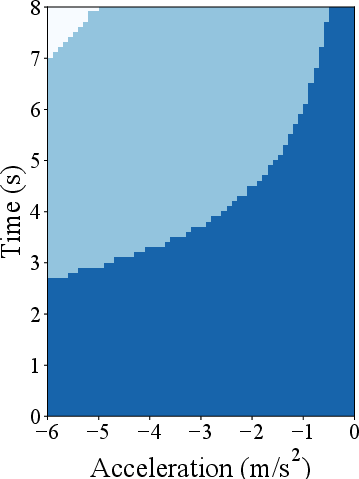
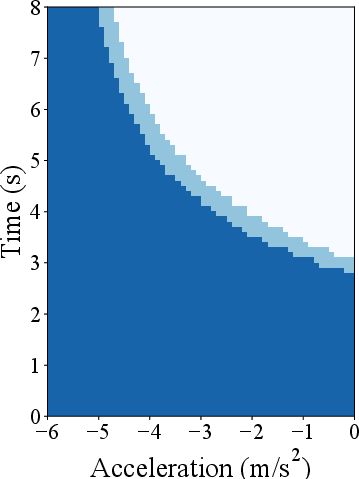
Figure 2: Safety-guaranteed regions associated with two specific scenarios: (a) the deceleration disturbance of the preceding vehicle and (b) the acceleration disturbance of the following vehicle. The horizontal axis denotes the magnitude of the disturbance signal (acceleration/deceleration), and the vertical axis is the duration of the disturbance signal. The dark blue regions denote the safety region of the LCC with PPO controller without the safety layer, and the light blue regions illustrate the expanded safety region achieved by implementing the safe RL controller for LCC (i.e., with safety layer), while the white regions indicate the unsafe region.
Comparative Performance
The integrated framework improved robustness against disturbances and better handled uncertainty, particularly in mixed braking and acceleration scenarios. Regular DRL methods failed in maintaining non-collision conditions, necessitating the integration of CBF for guaranteed operational safety.
Conclusion and Future Work
The study introduces an advanced safe RL-based controller for utilizing CBFs in reinforcing CAV safety within mixed-traffic platoons. By incorporating system-level considerations and adopting a learning-based dynamic identification approach, the proposed framework exhibits substantial improvements in handling stochastic traffic dynamics and enhancing cooperative vehicular operations. Future work may explore multi-agent RL for collaborative strategies among CAVs, adaptive to varying traffic densities and real-world complexities like urban settings and diverse environmental conditions.