FAIR Enough: How Can We Develop and Assess a FAIR-Compliant Dataset for Large Language Models' Training?
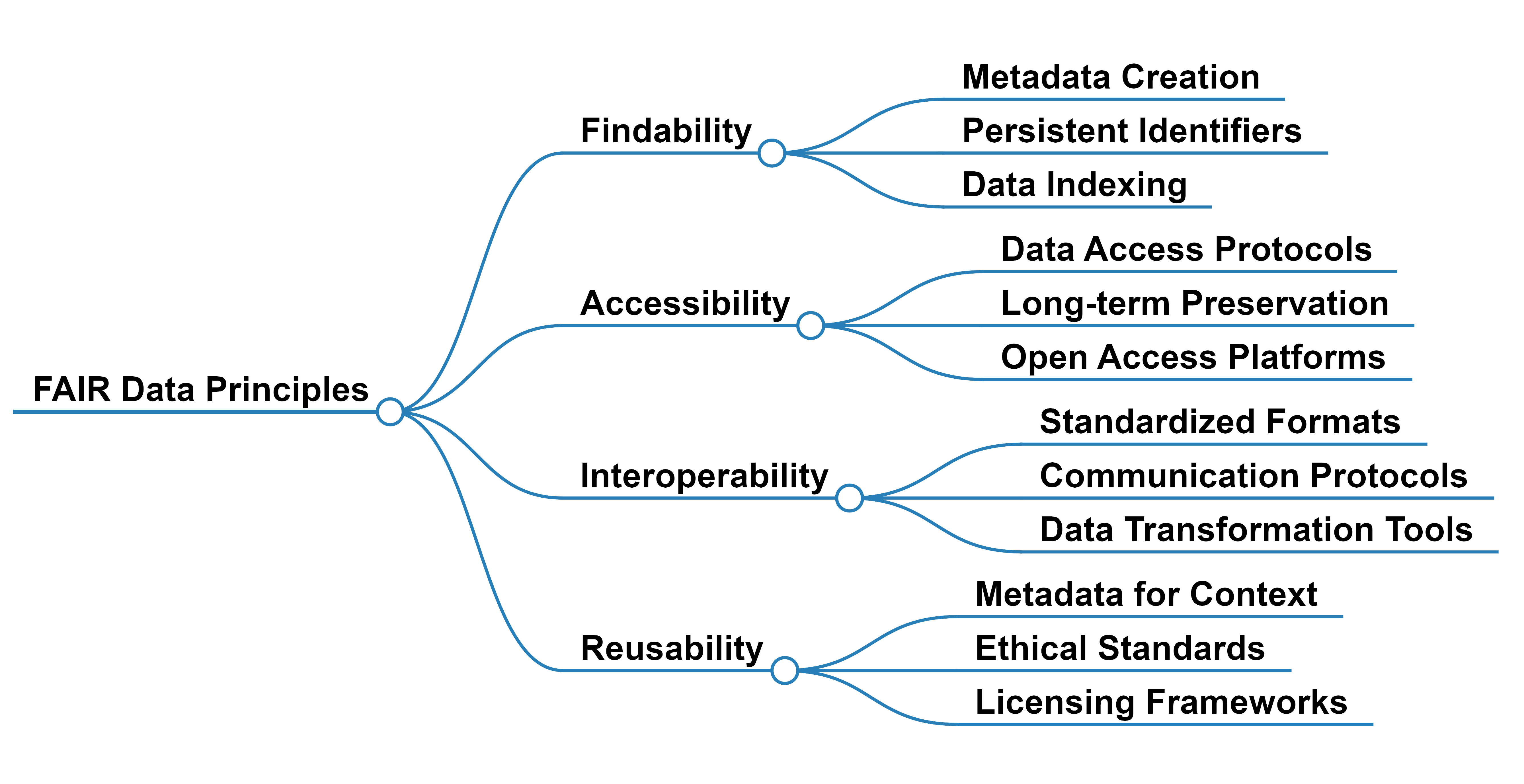
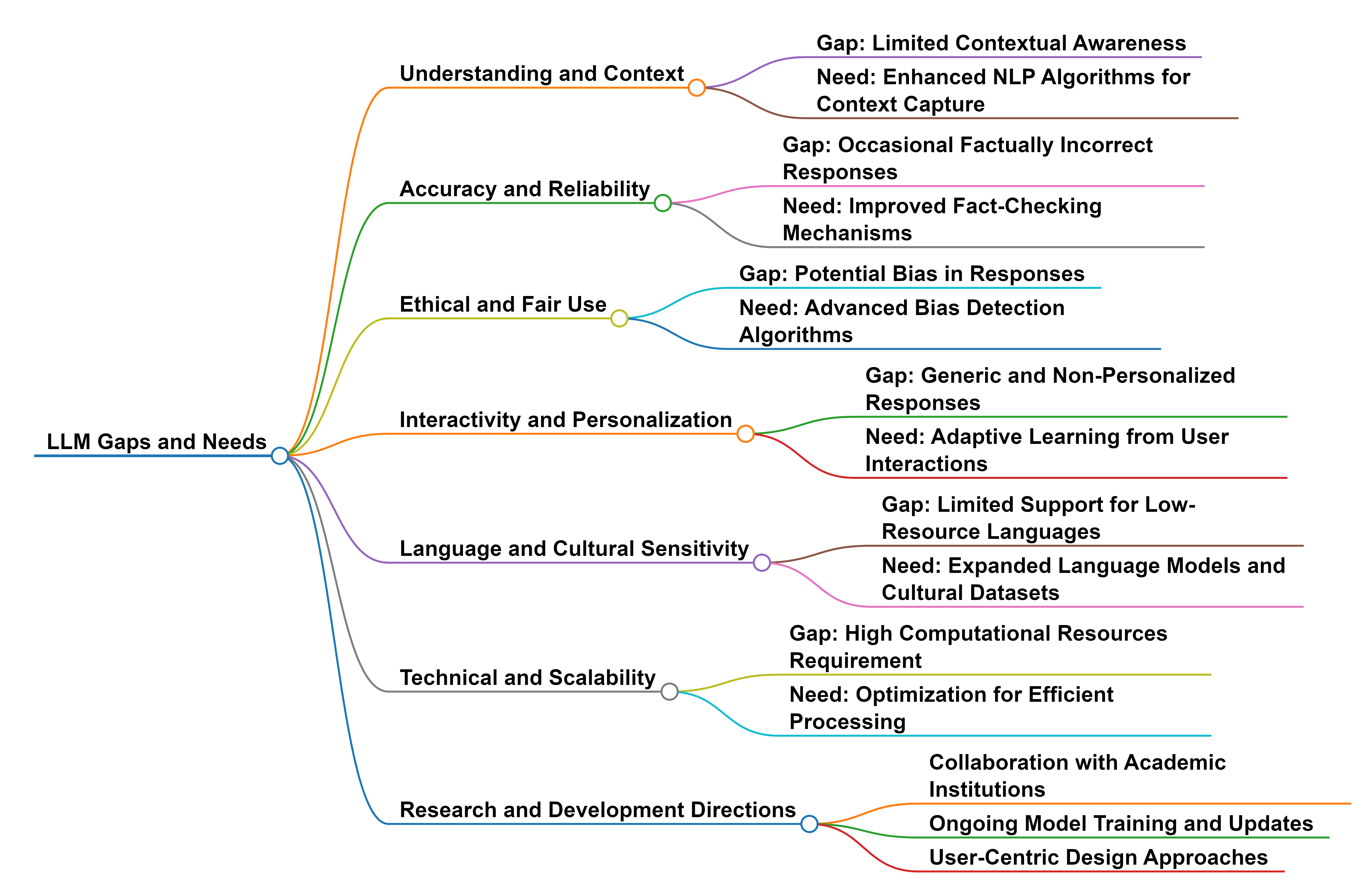
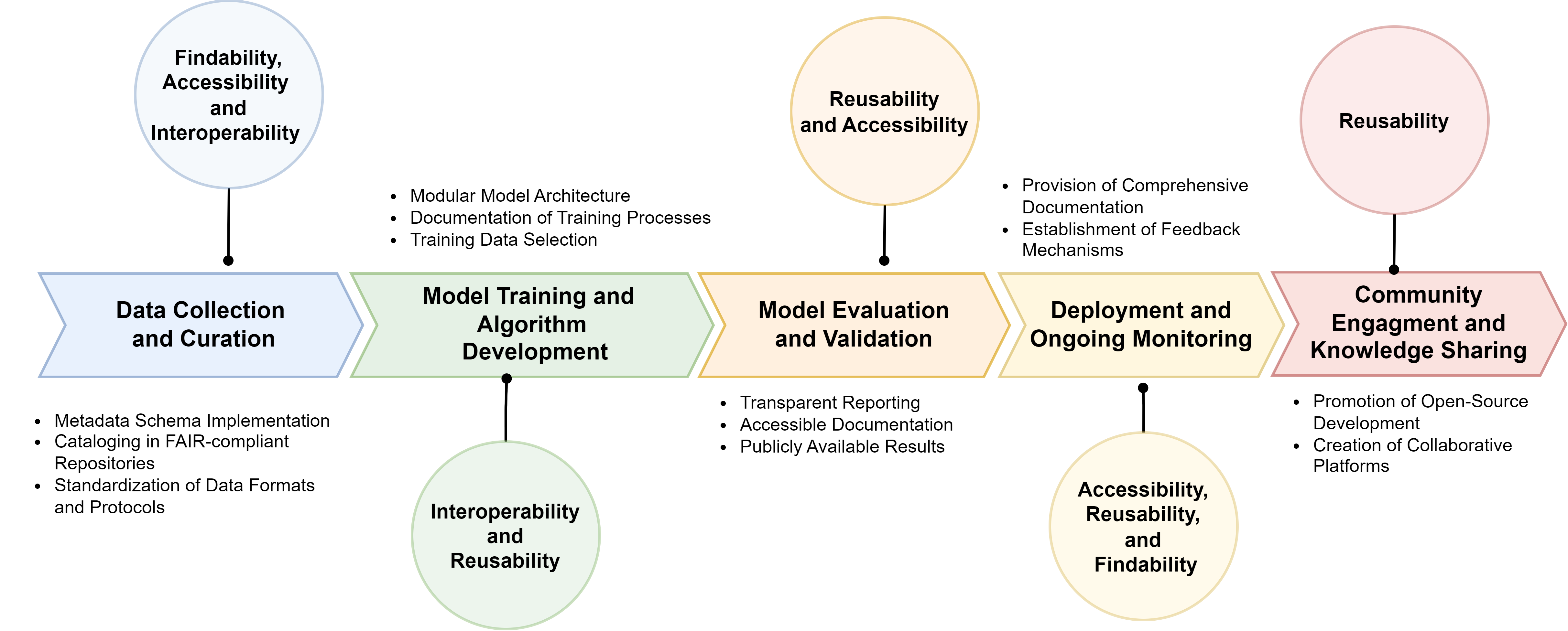
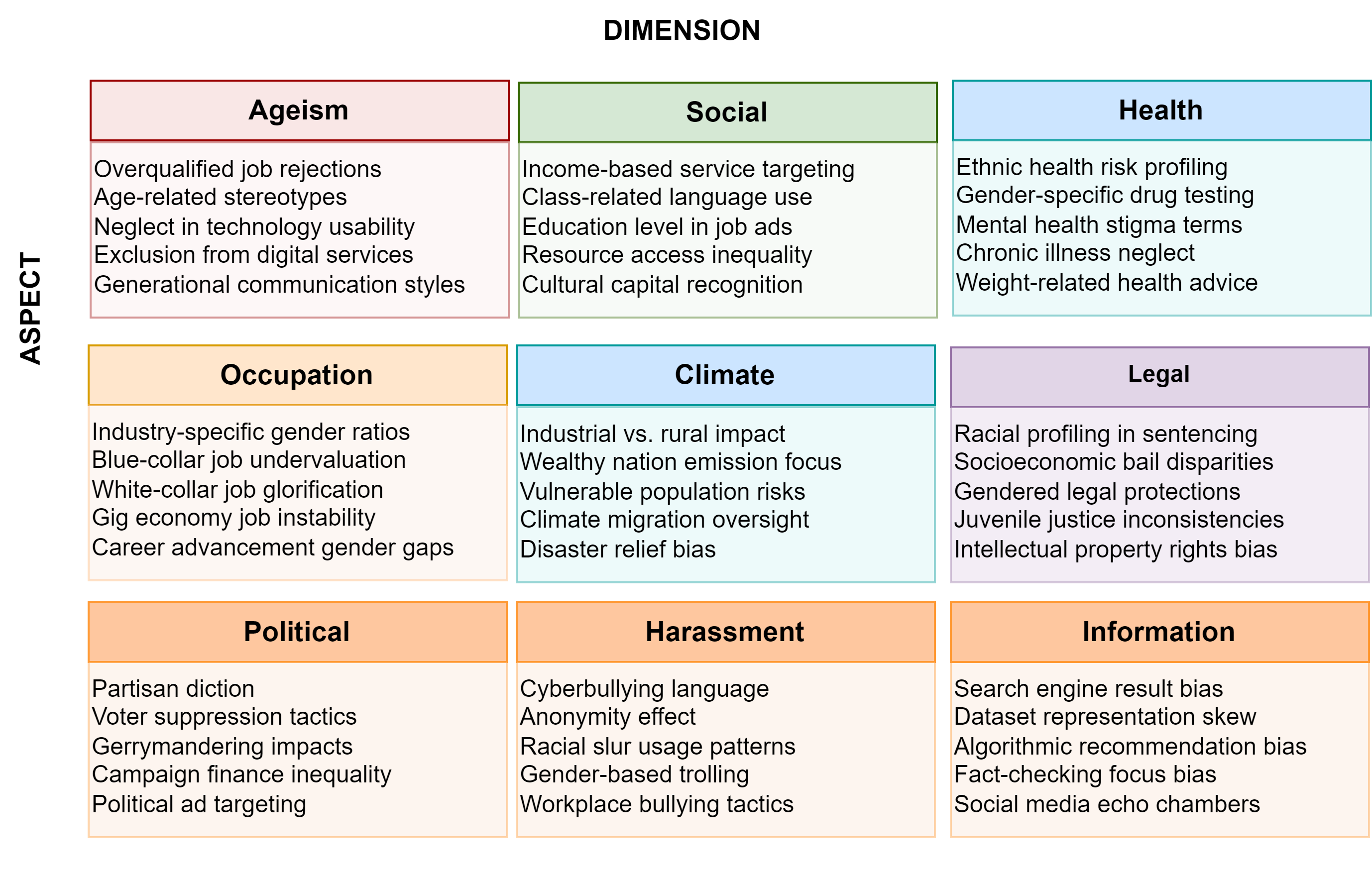
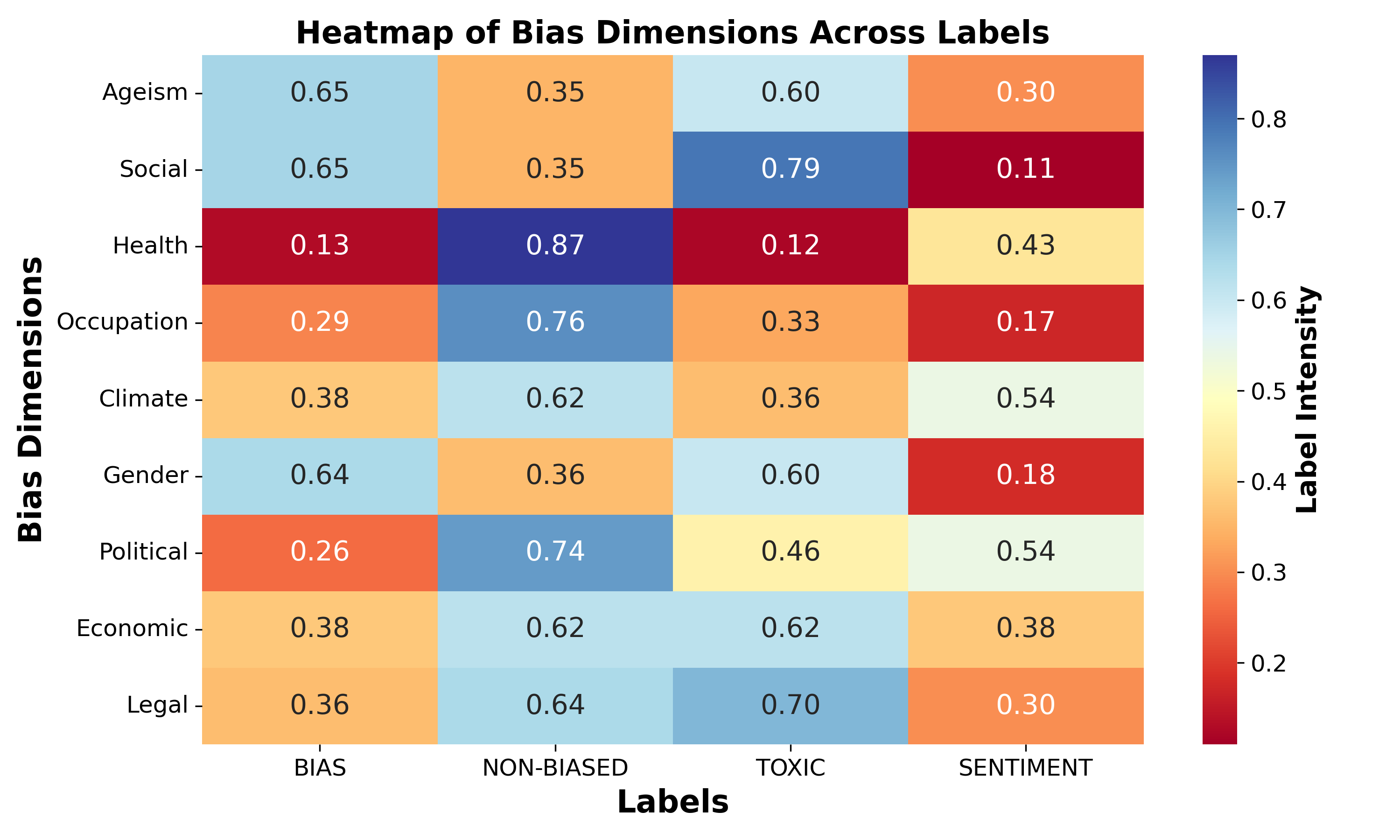
Abstract: The rapid evolution of LLMs highlights the necessity for ethical considerations and data integrity in AI development, particularly emphasizing the role of FAIR (Findable, Accessible, Interoperable, Reusable) data principles. While these principles are crucial for ethical data stewardship, their specific application in the context of LLM training data remains an under-explored area. This research gap is the focus of our study, which begins with an examination of existing literature to underline the importance of FAIR principles in managing data for LLM training. Building upon this, we propose a novel framework designed to integrate FAIR principles into the LLM development lifecycle. A contribution of our work is the development of a comprehensive checklist intended to guide researchers and developers in applying FAIR data principles consistently across the model development process. The utility and effectiveness of our framework are validated through a case study on creating a FAIR-compliant dataset aimed at detecting and mitigating biases in LLMs. We present this framework to the community as a tool to foster the creation of technologically advanced, ethically grounded, and socially responsible AI models.
- Desiderata for the data governance and FAIR principles adoption in health data hubs.
- Reghu Anguswamy and William B Frakes. 2012. A study of reusability, complexity, and reuse design principles. In Proceedings of the ACM-IEEE international symposium on Empirical software engineering and measurement. 161–164.
- The FAIR Guiding Principles for scientific data management and stewardship. Scientific data 3 (2016), 160018.
- RedditBias: A real-world resource for bias evaluation and debiasing of conversational language models. arXiv preprint arXiv:2106.03521 (2021).
- AI Fairness: from Principles to Practice. arXiv (2022). https://doi.org/10.48550/arXiv.2207.09833
- On the dangers of stochastic parrots: Can language models be too big?. In Proceedings of the 2021 ACM conference on fairness, accountability, and transparency. 610–623.
- A goal-oriented method for FAIRification planning. (2023). arXiv:10.21203/rs.3.rs-3092538/v1 https://www.researchsquare.com/article/rs-3092538/v1
- The FAIR guiding principles for data stewardship: fair enough? European journal of human genetics 26, 7 (2018), 931–936.
- A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023).
- Can large language models provide security & privacy advice? measuring the ability of llms to refute misconceptions. In Proceedings of the 39th Annual Computer Security Applications Conference. 366–378.
- Creative Commons. 2023. Creative Commons Attribution-NonCommercial 4.0 International License. https://creativecommons.org/licenses/by-nc/4.0/. Accessed on 2023-12-10.
- FAIR data points supporting big data interoperability. Enterprise Interoperability in the Digitized and Networked Factory of the Future. ISTE, London (2016), 270–279.
- Advait Deshpande and Helen Sharp. 2022. Responsible AI Systems: Who are the Stakeholders?. In Proceedings of the 2022 AAAI/ACM Conference on AI, Ethics, and Society. 227–236.
- Keranda Dungkek. 2022. FAIR Principles for data and AI models in high energy physics research and education. arXiv (2022). https://doi.org/10.48550/arxiv.2211.15021
- Are the FAIR data principles fair? International Journal of digital curation 12, 2 (1970), 177–195.
- Mark Findlay and Josephine Seah. 2020. An ecosystem approach to ethical AI and data use: experimental reflections. In 2020 IEEE/ITU international conference on artificial intelligence for good (AI4G). IEEE, 192–197.
- Addressing fairness, bias, and appropriate use of artificial intelligence and machine learning in global health. Frontiers in Artificial Intelligence 3 (2021), 561802.
- A survey on bias in deep NLP. Applied Sciences 11, 7 (2021), 3184.
- Andrew Götz. 2023. The fair principles: Trusting in fair data repositories. Open Access Government (2023). https://typeset.io/papers/the-fair-principles-trusting-in-fair-data-repositories-fzp529uf
- Ali Hasnain and Dietrich Rebholz-Schuhmann. 2018. Assessing FAIR data principles against the 5-star open data principles. In The Semantic Web: ESWC 2018 Satellite Events: ESWC 2018 Satellite Events, Heraklion, Crete, Greece, June 3-7, 2018, Revised Selected Papers 15. Springer, 469–477.
- The eXtensible ontology development (XOD) principles and tool implementation to support ontology interoperability. Journal of biomedical semantics 9 (2018), 1–10.
- Large language models as zero-shot conversational recommenders. In Proceedings of the 32nd ACM international conference on information and knowledge management. 720–730.
- FAIR for AI: An interdisciplinary and international community building perspective. Scientific Data 10, 1 (July 2023). https://doi.org/10.1038/s41597-023-02298-6
- Initiatives, concepts, and implementation practices of FAIR (findable, accessible, interoperable, and reusable) data principles in health data stewardship practice: protocol for a scoping review. JMIR research protocols 10, 2 (2021), e22505.
- Initiatives, Concepts, and Implementation Practices of the Findable, Accessible, Interoperable, and Reusable Data Principles in Health Data Stewardship: Scoping Review. Journal of Medical Internet Research 25 (2023), e45013.
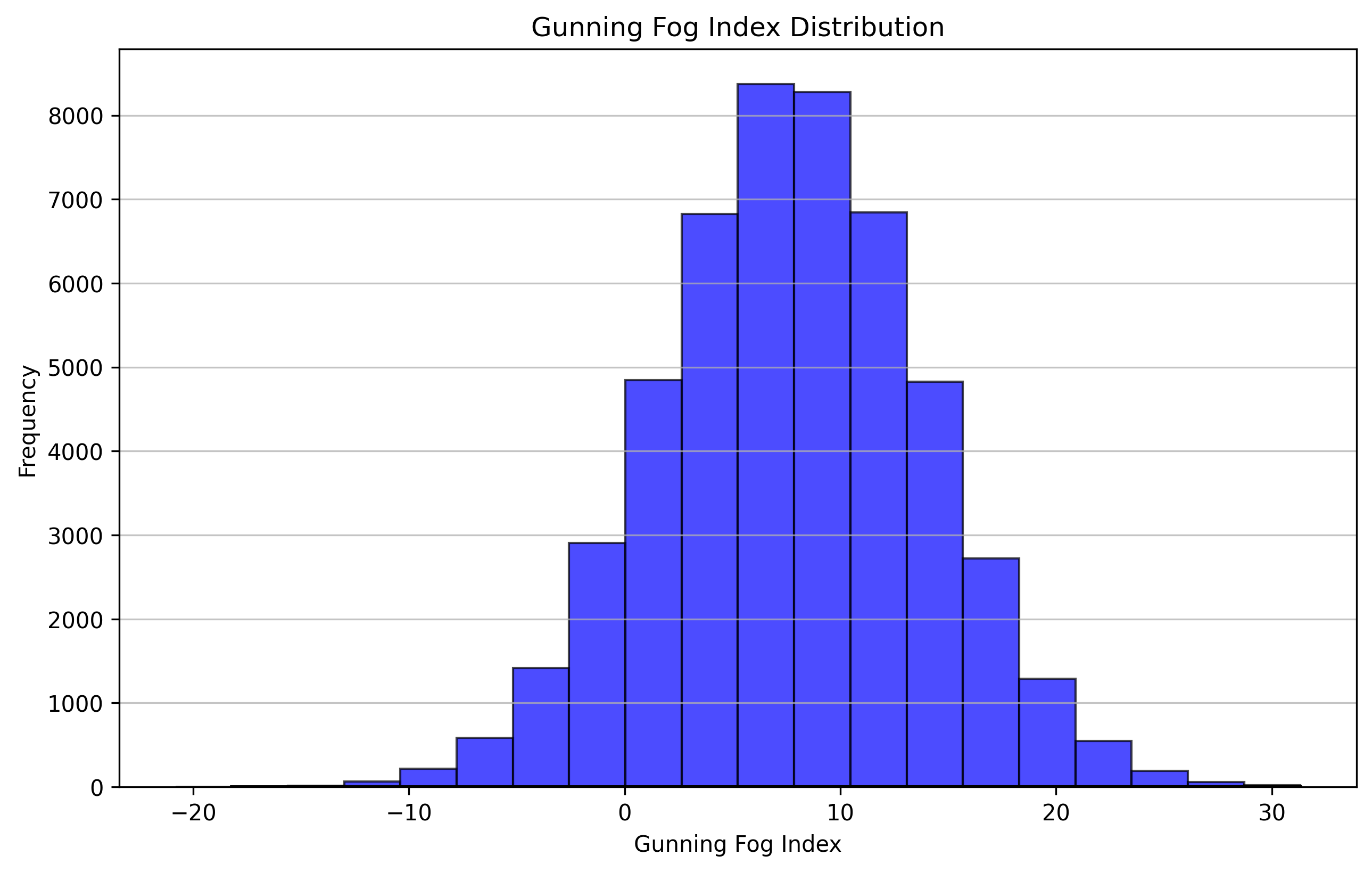
- Janice Jacobs. 2023. Gunning Fog Index. https://readabilityformulas.com/readability-for-todays-tech-savvy-readers/ Accessed on [insert date here].
- FAIR principles: interpretations and implementation considerations. , 10–29 pages.
- FAIR Principles: Interpretations and Implementation Considerations. Data Intelligence 2, 1-2 (01 2020), 10–29. https://doi.org/10.1162/dint_r_00024 arXiv:https://direct.mit.edu/dint/article-pdf/2/1-2/10/1893430/dint_r_00024.pdf
- FAIR Data Model for Chemical Substances: Development Challenges, Management Strategies, and Applications. In Data Integrity and Data Governance. IntechOpen.
- Survey of hallucination in natural language generation. Comput. Surveys 55, 12 (2023), 1–38.
- How can we know what language models know? Transactions of the Association for Computational Linguistics 8 (2020), 423–438.
- The global landscape of AI ethics guidelines. Nature machine intelligence 1, 9 (2019), 389–399.
- Towards FAIR principles for research software. Data Science 3, 1 (2020), 37–59.
- Towards understanding and mitigating social biases in language models. In International Conference on Machine Learning. PMLR, 6565–6576.
- G-eval: Nlg evaluation using gpt-4 with better human alignment, may 2023. arXiv preprint arXiv:2303.16634 6 (2023).
- On measuring social biases in sentence encoders. NAACL HLT 2019 (2019), 622–628.
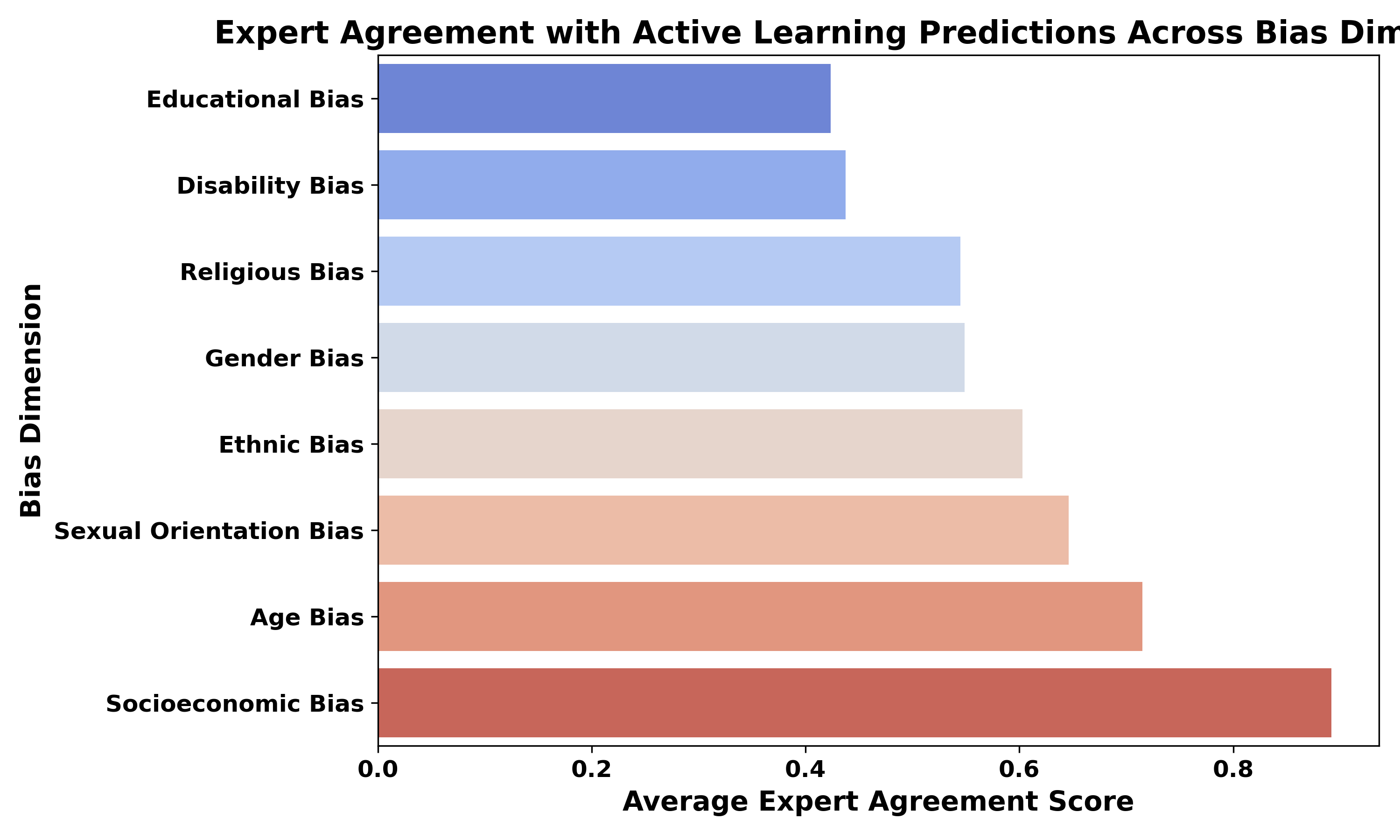
- Robert Munro Monarch. 2021. Human-in-the-Loop Machine Learning: Active learning and annotation for human-centered AI. Simon and Schuster.
- StereoSet: Measuring stereotypical bias in pretrained language models. In ACL-IJCNLPth Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing. 2021–59.
- Biases in Large Language Models: Origins, Inventory and Discussion. ACM Journal of Data and Information Quality (2023).
- How to measure uncertainty in uncertainty sampling for active learning. Machine Learning 111, 1 (2022), 89–122.
- Bias in data-driven artificial intelligence systems—An introductory survey. Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery 10, 3 (2020), e1356.
- OpenAI Supplier Code of Ethics. 2024. Home. Retrieved January 10, 2024 from https://openai.com/policies/supplier-code
- Data quality and FAIR principles applied to marine litter data in Europe. Marine Pollution Bulletin 168 (2021), 112965. https://doi.org/10.1016/J.MARPOLBUL.2021.112965
- AI and the everything in the whole wide world benchmark. arXiv preprint arXiv:2111.15366 (2021).
- Challenges in mapping European rare disease databases, relevant for ML-based screening technologies in terms of organizational, FAIR and legal principles: scoping review. Frontiers in Public Health 11 (2023).
- Shaina Raza. 2021. Automatic fake news detection in political platforms-a transformer-based approach. In Proceedings of the 4th Workshop on Challenges and Applications of Automated Extraction of Socio-political Events from Text (CASE 2021). 68–78.
- Shaina Raza and Chen Ding. 2022. Fake news detection based on news content and social contexts: a transformer-based approach. International Journal of Data Science and Analytics 13, 4 (2022), 335–362.
- Nbias: A natural language processing framework for BIAS identification in text. Expert Systems with Applications 237 (2024), 121542.
- Dbias: detecting biases and ensuring fairness in news articles. International Journal of Data Science and Analytics (2022), 1–21.
- Shaina Raza and Brian Schwartz. 2023. Constructing a disease database and using natural language processing to capture and standardize free text clinical information. Scientific Reports 13, 1 (2023), 8591.
- Opportunities for improving data sharing and FAIR data practices to advance global mental health. Cambridge Prisms: Global Mental Health 10 (2023), e14.
- GO FAIR Brazil: a challenge for brazilian data science. Data Intelligence 2, 1-2 (2020), 238–245.
- Towards a conceptual model for the FAIR Digital Object Framework. arXiv preprint arXiv:2302.11894 (2023).
- Ready, Set, GO FAIR: Accelerating Convergence to an Internet of FAIR Data and Services. DAMDID/RCDL 19 (2018), 23.
- Beyond Fair Pay: Ethical Implications of NLP Crowdsourcing. In North American Chapter of the Association for Computational Linguistics. https://doi.org/10.18653/V1/2021.NAACL-MAIN.295
- Fusion-Eval: Integrating Evaluators with LLMs. arXiv preprint arXiv:2311.09204 (2023).
- Augmenting interpretable models with large language models during training. Nature Communications 14, 1 (2023), 7913.
- Alexandru Stanciu. 2023. Data Management Plan for Healthcare: Following FAIR Principles and Addressing Cybersecurity Aspects. A Systematic Review using InstructGPT. medRxiv (2023), 2023–04.
- Llama 2: Open Foundation and Fine-Tuned Chat Models. arXiv e-prints (2023), arXiv–2307.
- TrendFeedr. 2024. Large Language Model (LLM) Trends. https://trendfeedr.com/blog/large-language-model-llm-trends/. Accessed: 2024-01-01.
- Implementing the FAIR Data Principles in precision oncology: review of supporting initiatives. Briefings in Bioinformatics 21, 3 (06 2019), 936–945. https://doi.org/10.1093/bib/bbz044 arXiv:https://academic.oup.com/bib/article-pdf/21/3/936/33398969/bbz044.pdf
- FAIR principles and the IEDB: short-term improvements and a long-term vision of OBO-foundry mediated machine-actionable interoperability. Database 2018 (2018), bax105.
- Minglu Wang and Dany Savard. 2023. The FAIR Principles and Research Data Management. Research Data Management in the Canadian Context (2023).
- Aligning large language models with human: A survey. arXiv preprint arXiv:2307.12966 (2023).
- David Wilcox. 2018. Supporting FAIR data principles with Fedora. LIBER Quarterly: The Journal of the Association of European Research Libraries 28, 1 (2018), 1–8.
- The FAIR Guiding Principles for scientific data management and stewardship. Scientific data 3, 1 (2016), 1–9.
- A design framework and exemplar metrics for FAIRness. Scientific data 5, 1 (2018), 1–4.
- How Abstract Is Linguistic Generalization in Large Language Models? Experiments with Argument Structure. Transactions of the Association for Computational Linguistics 11 (2023), 1377–1395.
- Implementation and relevance of FAIR data principles in biopharmaceutical R&D. Drug discovery today 24, 4 (2019), 933–938.
- Reusability first: Toward FAIR workflows. In 2021 IEEE International Conference on Cluster Computing (CLUSTER). IEEE, 444–455.
- The rise and potential of large language model based agents: A survey. arXiv preprint arXiv:2309.07864 (2023).
- Explainability for large language models: A survey. arXiv preprint arXiv:2309.01029 (2023).
- A survey of large language models. arXiv preprint arXiv:2303.18223 (2023).
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.