Zero Bubble Pipeline Parallelism
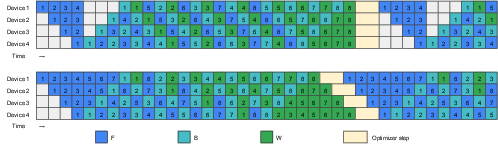
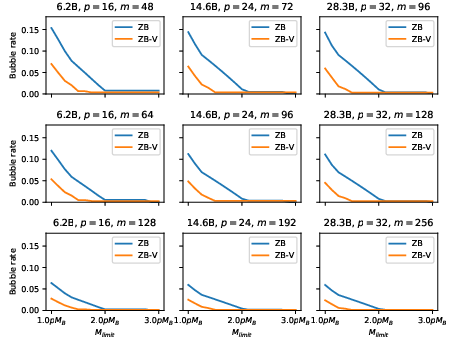
Abstract: Pipeline parallelism is one of the key components for large-scale distributed training, yet its efficiency suffers from pipeline bubbles which were deemed inevitable. In this work, we introduce a scheduling strategy that, to our knowledge, is the first to successfully achieve zero pipeline bubbles under synchronous training semantics. The key idea behind this improvement is to split the backward computation into two parts, one that computes gradient for the input and another that computes for the parameters. Based on this idea, we handcraft novel pipeline schedules that significantly outperform the baseline methods. We further develop an algorithm that automatically finds an optimal schedule based on specific model configuration and memory limit. Additionally, to truly achieve zero bubble, we introduce a novel technique to bypass synchronizations during the optimizer step. Experimental evaluations show that our method outperforms the 1F1B schedule up to 23% in throughput under a similar memory limit. This number can be further pushed to 31% when the memory constraint is relaxed. We believe our results mark a major step forward in harnessing the true potential of pipeline parallelism. We open sourced our implementation based on the popular Megatron-LM repository on https://github.com/sail-sg/zero-bubble-pipeline-parallelism.
- Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020.
- {{\{{TVM}}\}}: An automated {{\{{End-to-End}}\}} optimizing compiler for deep learning. In 13th USENIX Symposium on Operating Systems Design and Implementation (OSDI 18), pp. 578–594, 2018.
- Dapple: A pipelined data parallel approach for training large models. In Proceedings of the 26th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming, pp. 431–445, 2021.
- Cbc user guide. In Emerging theory, methods, and applications, pp. 257–277. INFORMS, 2005.
- Accurate, large minibatch sgd: Training imagenet in 1 hour. arXiv preprint arXiv:1706.02677, 2017.
- Pipedream: Fast and efficient pipeline parallel dnn training. arXiv preprint arXiv:1806.03377, 2018.
- Gpipe: Efficient training of giant neural networks using pipeline parallelism. Advances in neural information processing systems, 32, 2019.
- Reducing activation recomputation in large transformer models. Proceedings of Machine Learning and Systems, 5, 2023.
- Mlir: A compiler infrastructure for the end of moore’s law. arXiv preprint arXiv:2002.11054, 2020.
- Pytorch distributed: Experiences on accelerating data parallel training. arXiv preprint arXiv:2006.15704, 2020.
- Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101, 2017.
- Mixed precision training. arXiv preprint arXiv:1710.03740, 2017.
- Efficient large-scale language model training on gpu clusters using megatron-lm. In Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, pp. 1–15, 2021.
- On the difficulty of training recurrent neural networks. In International conference on machine learning, pp. 1310–1318. Pmlr, 2013.
- Zero: Memory optimizations toward training trillion parameter models. In SC20: International Conference for High Performance Computing, Networking, Storage and Analysis, pp. 1–16. IEEE, 2020.
- Relay: A new ir for machine learning frameworks. In Proceedings of the 2nd ACM SIGPLAN international workshop on machine learning and programming languages, pp. 58–68, 2018.
- Amit Sabne. Xla : Compiling machine learning for peak performance, 2020.
- Triton: an intermediate language and compiler for tiled neural network computations. In Proceedings of the 3rd ACM SIGPLAN International Workshop on Machine Learning and Programming Languages, pp. 10–19, 2019.
- Attention is all you need. Advances in neural information processing systems, 30, 2017.
- Pipemare: Asynchronous pipeline parallel dnn training. Proceedings of Machine Learning and Systems, 3:269–296, 2021.
- Alpa: Automating inter-and {{\{{Intra-Operator}}\}} parallelism for distributed deep learning. In 16th USENIX Symposium on Operating Systems Design and Implementation (OSDI 22), pp. 559–578, 2022.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.