Meme-ingful Analysis: Enhanced Understanding of Cyberbullying in Memes Through Multimodal Explanations
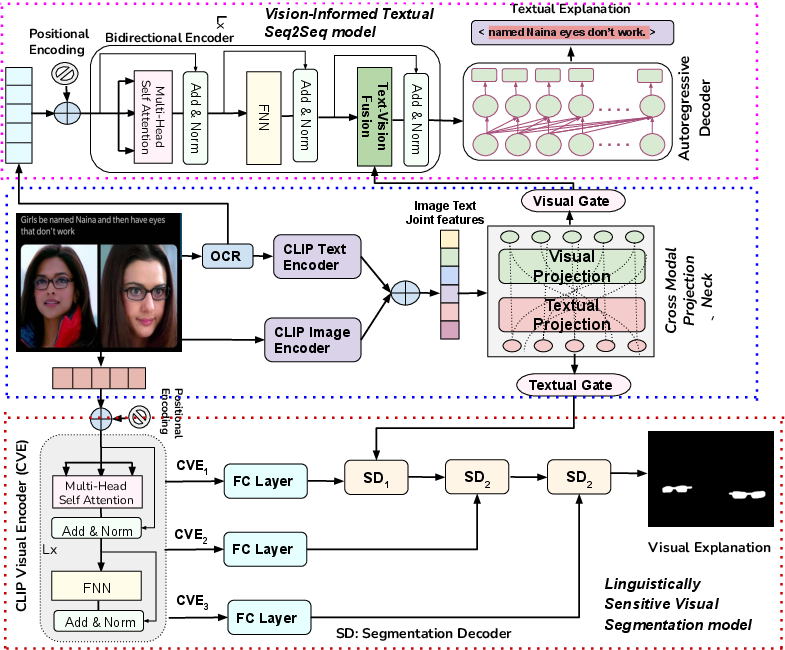
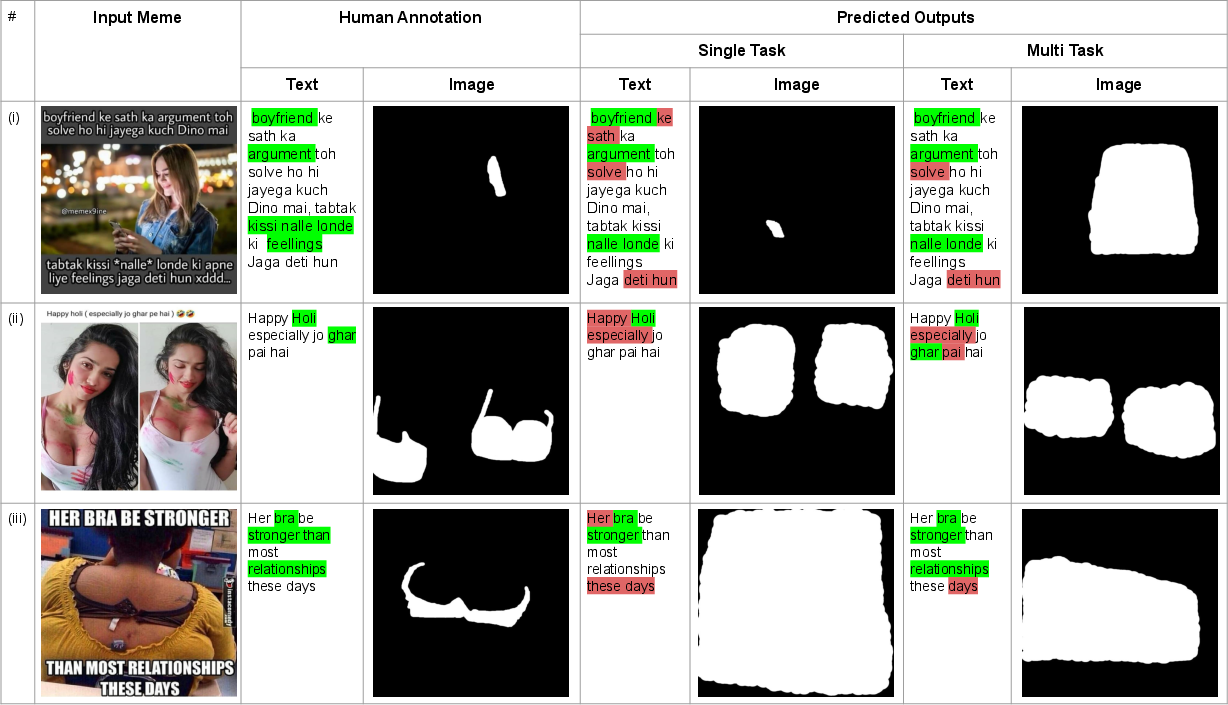
Abstract: Internet memes have gained significant influence in communicating political, psychological, and sociocultural ideas. While memes are often humorous, there has been a rise in the use of memes for trolling and cyberbullying. Although a wide variety of effective deep learning-based models have been developed for detecting offensive multimodal memes, only a few works have been done on explainability aspect. Recent laws like "right to explanations" of General Data Protection Regulation, have spurred research in developing interpretable models rather than only focusing on performance. Motivated by this, we introduce {\em MultiBully-Ex}, the first benchmark dataset for multimodal explanation from code-mixed cyberbullying memes. Here, both visual and textual modalities are highlighted to explain why a given meme is cyberbullying. A Contrastive Language-Image Pretraining (CLIP) projection-based multimodal shared-private multitask approach has been proposed for visual and textual explanation of a meme. Experimental results demonstrate that training with multimodal explanations improves performance in generating textual justifications and more accurately identifying the visual evidence supporting a decision with reliable performance improvements.
- Sweta Agrawal and Amit Awekar. 2018. Deep learning for detecting cyberbullying across multiple social media platforms. In European conference on information retrieval, pages 141–153. Springer.
- Layer normalization. arXiv preprint arXiv:1607.06450.
- Curriculum learning. In Proceedings of the 26th annual international conference on machine learning, pages 41–48.
- Deephate: Hate speech detection via multi-faceted text representations. In 12th ACM conference on web science, pages 11–20.
- Cyberbullying on social networking sites: the crime opportunity and affordance perspectives. Journal of Management Information Systems, 36(2):574–609.
- Rethinking atrous convolution for semantic image segmentation. arXiv preprint arXiv:1706.05587.
- Experts and machines against bullies: A hybrid approach to detect cyberbullies. In Canadian conference on artificial intelligence, pages 275–281. Springer.
- Lee R Dice. 1945. Measures of the amount of ecologic association between species. Ecology, 26(3):297–302.
- Joseph L Fleiss. 1971. Measuring nominal scale agreement among many raters. Psychological bulletin, 76(5):378.
- Benito García-Valero. 2020. Borreguero zuloaga, m. and vitacolonna, l.(eds.), the legacy of jános s. petőfi. text linguistics, literary theory and semiotics. Journal of Literary Semantics, 49(1):61–64.
- Exploring hate speech detection in multimodal publications. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 1470–1478.
- Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778.
- On explaining multimodal hateful meme detection models. In WWW ’22: The ACM Web Conference 2022, Virtual Event, Lyon, France, April 25 - 29, 2022, pages 3651–3655. ACM.
- Searching for mobilenetv3. In Proceedings of the IEEE/CVF international conference on computer vision, pages 1314–1324.
- Paul Jaccard. 1901. Distribution de la flore alpine dans le bassin des dranses et dans quelques régions voisines. Bull Soc Vaudoise Sci Nat, 37:241–272.
- Combining vision and language representations for patch-based identification of lexico-semantic relations. In Proceedings of the 30th ACM International Conference on Multimedia, pages 4406–4415.
- Deephateexplainer: Explainable hate speech detection in under-resourced bengali language. In 2021 IEEE 8th International Conference on Data Science and Advanced Analytics (DSAA), pages 1–10. IEEE.
- The hateful memes challenge: Detecting hate speech in multimodal memes. In Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual.
- Bart: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. arXiv preprint arXiv:1910.13461.
- Chin-Yew Lin and Franz Josef Och. 2004. Automatic evaluation of machine translation quality using longest common subsequence and skip-bigram statistics. In Proceedings of the 42nd Annual Meeting of the Association for Computational Linguistics (ACL-04), pages 605–612.
- Recurrent neural network for text classification with multi-task learning. arXiv preprint arXiv:1605.05101.
- Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 3431–3440.
- Visual attention model for name tagging in multimodal social media. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1990–1999.
- Scott M Lundberg and Su-In Lee. 2017. A unified approach to interpreting model predictions. Advances in neural information processing systems, 30.
- A multitask framework for sentiment, emotion and sarcasm aware cyberbullying detection from multi-modal code-mixed memes. In SIGIR ’22: The 45th International ACM SIGIR Conference on Research and Development in Information Retrieval, Madrid, Spain, July 11 - 15, 2022, pages 1739–1749. ACM.
- A multitask framework for sentiment, emotion and sarcasm aware cyberbullying detection from multi-modal code-mixed memes.
- Hatexplain: A benchmark dataset for explainable hate speech detection. arXiv preprint arXiv:2012.10289.
- Carol Myers-Scotton. 1997. Duelling languages: Grammatical structure in codeswitching. Oxford University Press.
- Bleu: a method for automatic evaluation of machine translation. In Proceedings of the 40th annual meeting of the Association for Computational Linguistics, pages 311–318.
- Sayanta Paul and Sriparna Saha. 2020. Cyberbert: Bert for cyberbullying identification. Multimedia Systems, pages 1–8.
- MOMENTA: A multimodal framework for detecting harmful memes and their targets. In Findings of the Association for Computational Linguistics: EMNLP 2021, Virtual Event / Punta Cana, Dominican Republic, 16-20 November, 2021, pages 4439–4455. Association for Computational Linguistics.
- Learning transferable visual models from natural language supervision. In International Conference on Machine Learning, pages 8748–8763. PMLR.
- Exploring the limits of transfer learning with a unified text-to-text transformer. J. Mach. Learn. Res., 21(140):1–67.
- " why should i trust you?" explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining, pages 1135–1144.
- Estimating code-switching on twitter with a novel generalized word-level language detection technique. In Proceedings of the 55th annual meeting of the association for computational linguistics (volume 1: long papers), pages 1971–1982.
- U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical image computing and computer-assisted intervention, pages 234–241. Springer.
- Lin CY ROUGE. 2004. A package for automatic evaluation of summaries. In Proceedings of Workshop on Text Summarization of ACL, Spain.
- Cyberbullying: Its nature and impact in secondary school pupils. Journal of child psychology and psychiatry, 49(4):376–385.
- Longitudinal risk factors for cyberbullying in adolescence. Journal of community & applied social psychology, 23(1):52–67.
- Multimodal meme dataset (multioff) for identifying offensive content in image and text. In Proceedings of the Second Workshop on Trolling, Aggression and Cyberbullying, pages 32–41.
- Multimodal transformer for unaligned multimodal language sequences. In Proceedings of the conference. Association for Computational Linguistics. Meeting, volume 2019, page 6558. NIH Public Access.
- Examining characteristics and associated distress related to internet harassment: findings from the second youth internet safety survey. Pediatrics, 118(4):e1169–e1177.
- Vision guided generative pre-trained language models for multimodal abstractive summarization. arXiv preprint arXiv:2109.02401.
- Using “annotator rationales” to improve machine learning for text categorization. In Human language technologies 2007: The conference of the North American chapter of the association for computational linguistics; proceedings of the main conference, pages 260–267.
- Adaptive co-attention network for named entity recognition in tweets. In Thirty-Second AAAI Conference on Artificial Intelligence.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.