- The paper introduces SPARC, which enhances fine-grained multimodal representations by leveraging sparse similarity metrics for improved token-level alignment.
- It combines global contrastive alignment with a fine-grained loss to achieve superior zero-shot classification, retrieval, and reduced textual hallucinations.
- Experimental results demonstrate that SPARC outperforms CLIP by capturing nuanced image-text details and enhancing computational efficiency.
Improving Fine-Grained Understanding in Image-Text Pre-Training
Introduction
This paper introduces SPARse Fine-grained Contrastive Alignment (SPARC), a method designed to enhance fine-grained multimodal representations derived from image-text pairs. SPARC targets the limitations of traditional contrastive learning models like CLIP, which tend to discard fine-grained visual information. By leveraging a sparse similarity metric and a fine-grained sequence-wise loss, SPARC improves the fidelity of models in capturing detailed information from individual samples without relying on batch negatives. This approach aims to simultaneously enhance global and local information encoding in multimodal pre-trained models.
Methodology
SPARC adopts a dual approach by incorporating both global and fine-grained contrastive losses:
- Global Alignment: Similar to CLIP, SPARC utilizes a global contrastive loss to align global image and text embeddings. This alignment maximizes similarities between matched image-text pairs while minimizing it for mismatched pairs within a batch.
- Fine-Grained Alignment: SPARC's core innovation lies in computing language-grouped vision embeddings. It calculates a sparse similarity matrix between image patches and language tokens, focusing only on the most relevant patches. This sparsification allows for a flexible correspondence between multiple image patches and a single textual token, better reflecting the complex reality of visual scenes.
(Figure 1)
Figure 1: SPARC architecture showing the process of similarity calculation, sparsification, and alignment-weight computation.
Key Features
- Sparsified Similarity Matrix: By enforcing sparsity, SPARC efficiently determines the most relevant patches for each text token, reducing computational overhead compared to full-batch approaches.
- Alignment-Weighted Aggregation: It computes language-grouped vision embeddings using alignment weights derived from the sparsified matrix, overcoming issues associated with softmax-induced winner-take-all dynamics.
- Token-wise Contrastive Loss: SPARC's fine-grained loss contrasts each language-grouped vision embedding with its corresponding token, capturing nuanced details beyond what is afforded by global alignment alone.
Implementation Details
SPARC's implementation requires integrating both the image and language encoders with alignment-weighted combination mechanisms. This involves:
- Adapting existing vision transformer architectures to handle sparse matrices and alignment computations.
- Utilizing efficient linear adaptors for embedding conversion and normalization.
- Combining sparse similarity indices to filter out noise and enhance relevant patch-token associations.
Experimental Results
SPARC demonstrates superior performance across various benchmarks:
- Zero-Shot Classification: SPARC achieved significant improvements over CLIP in tasks involving fine-grained detail recognition and object detection.
- Retrieval Tasks: It outperformed existing methods in image-to-text and text-to-image retrieval benchmarks, showcasing its enhanced ability to capture fine-grained associations.
- Faithfulness and Localization: SPARC reduces textual hallucinations and improves representation fidelity, as evidenced by higher K-Precision in MSCOCO datasets.
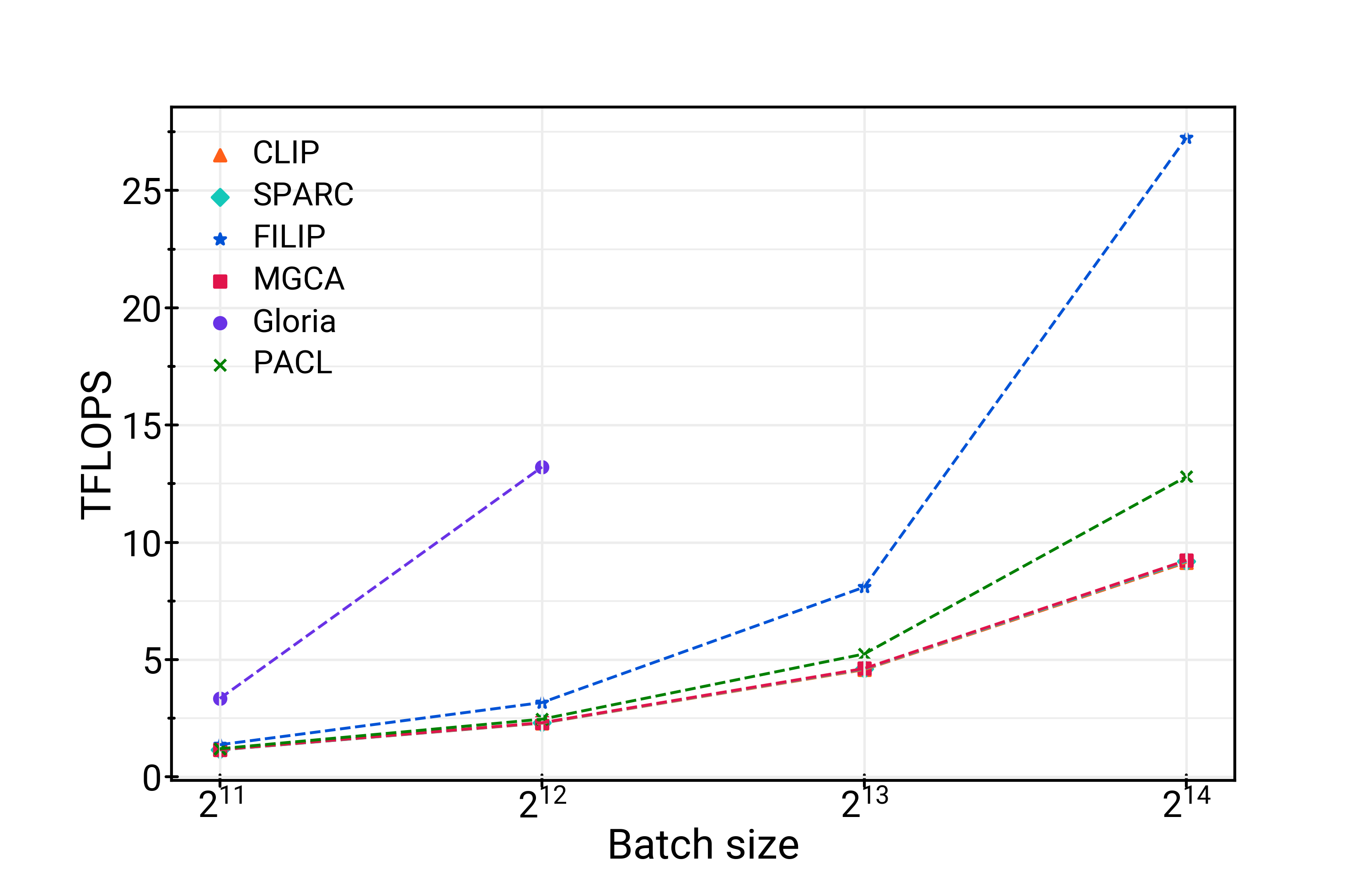
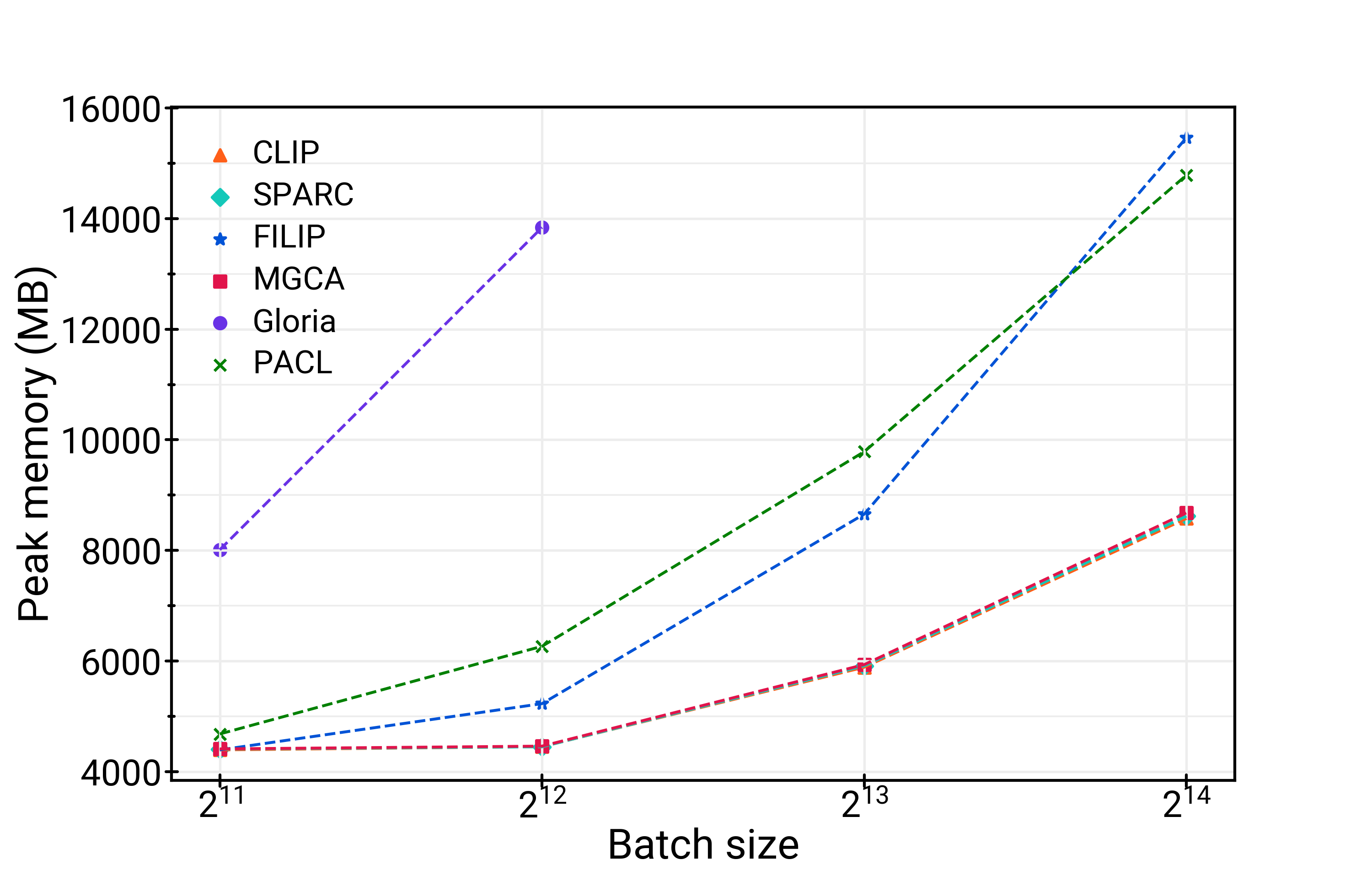
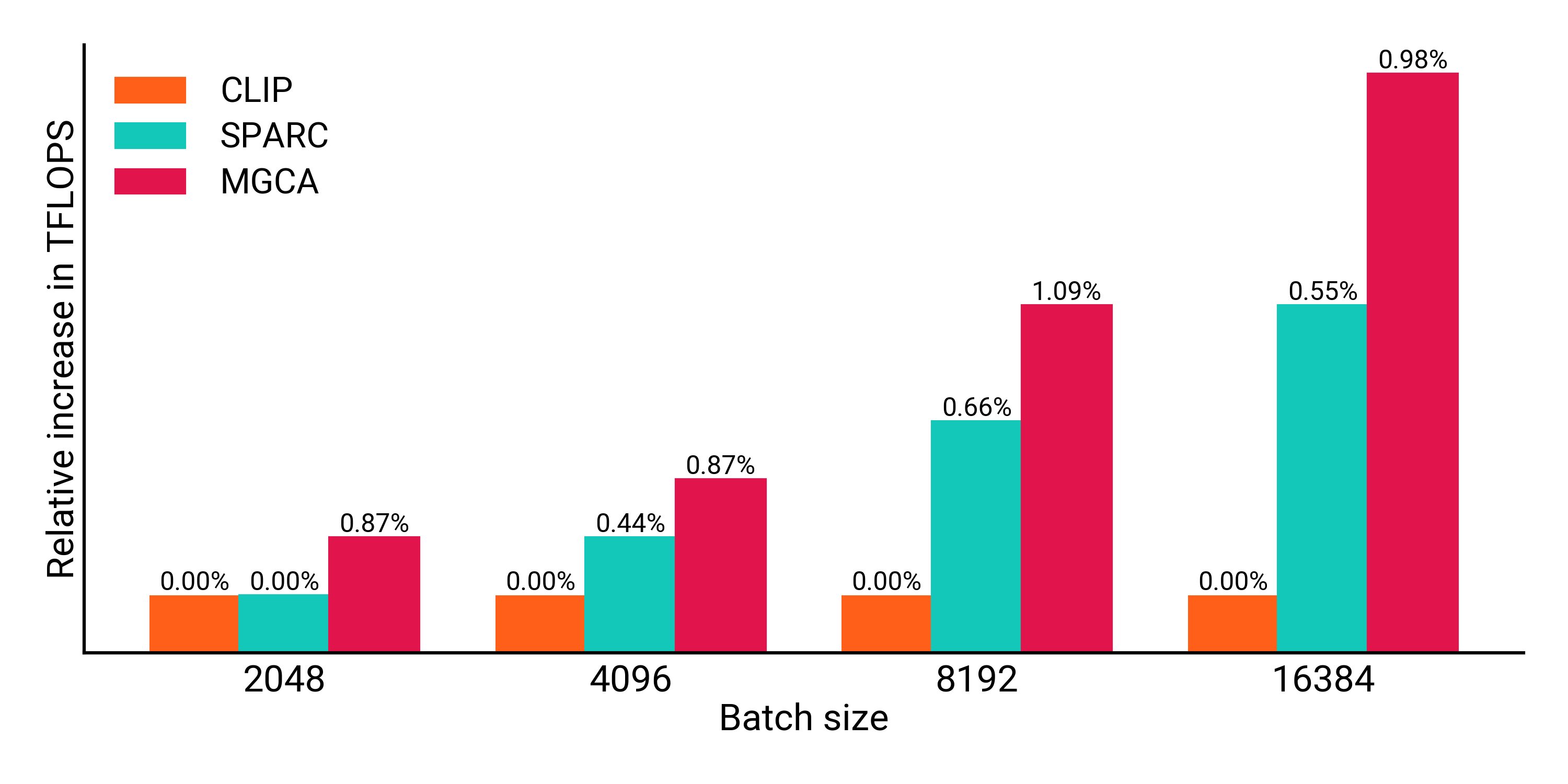
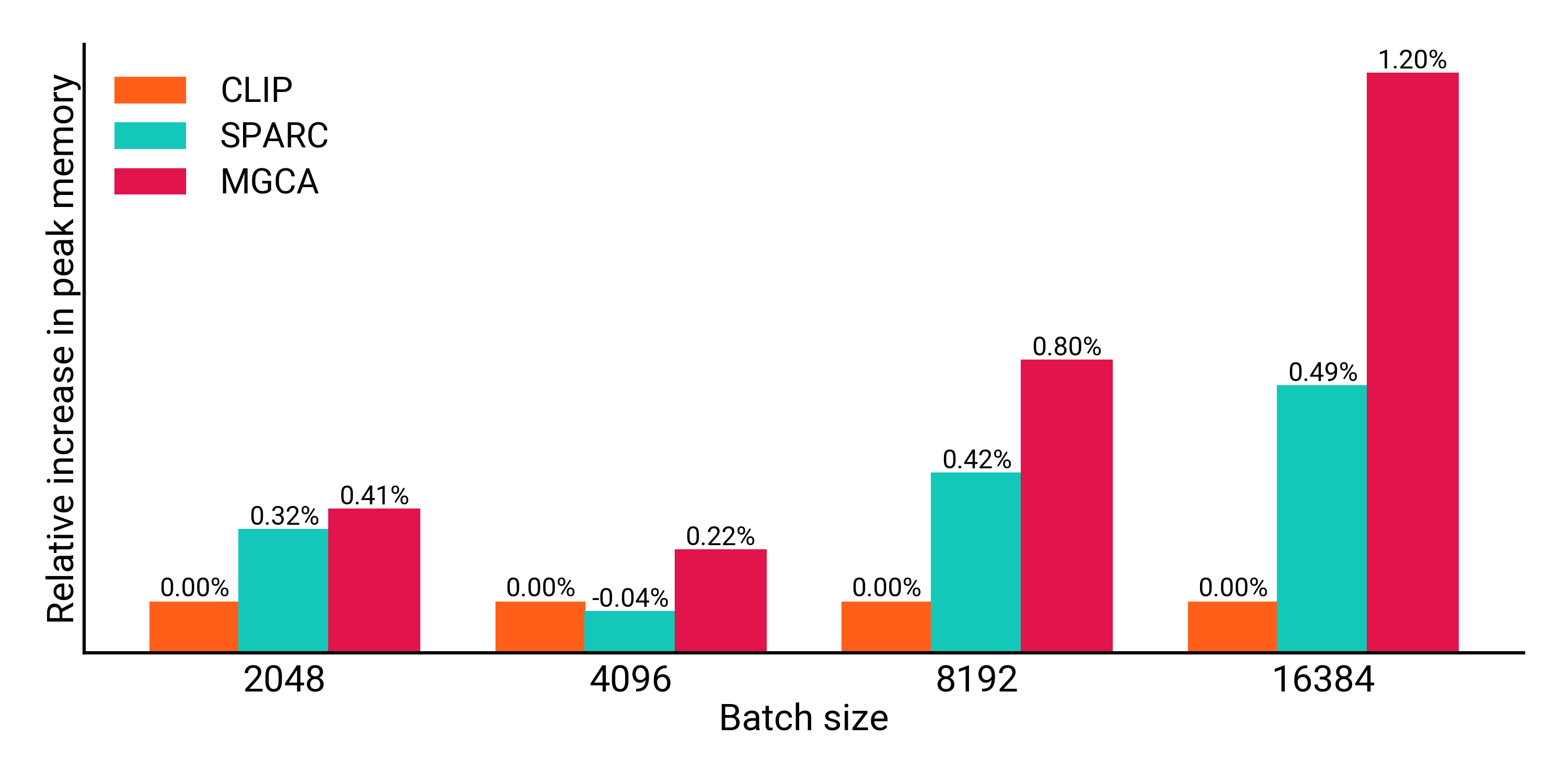
Figure 2: TFLOPS (a) and Peak Memory (b) showing SPARC's efficiency compared to other methods.
Conclusion
SPARC presents a compelling advancement in the pre-training of multimodal representations, addressing the need for fine-grained understanding in image-text tasks. Its computational efficiency and enhanced granularity support a range of applications, from foundational models to more accurate object detection and image segmentation. Future work may explore more sophisticated sparsification techniques and the integration of additional data modalities to further enhance model performance and applicability.