- The paper presents a novel virtual memory stitching mechanism that efficiently reduces GPU memory fragmentation during large-scale DNN training.
- It introduces a virtual memory pool and a four-state allocation strategy that enhances memory utilization and scalability across various deep learning frameworks.
- Experimental results demonstrate up to 33% fragmentation reduction and memory savings of 25GB, all while maintaining high throughput.
GMLake: Efficient and Transparent GPU Memory Defragmentation for Large-scale DNN Training with Virtual Memory Stitching
Introduction
GMLake presents a novel solution to address memory fragmentation challenges in large-scale Deep Neural Network (DNN) training, particularly for models such as LLMs. Utilizing a virtual memory stitching (VMS) mechanism, GMLake tackles issues arising from frequent and irregular memory allocation requests which otherwise lead to fragmentation in traditional caching allocators. This solution enhances GPU memory utilization, offering significant reductions in memory overheads and fragmentations during the training of extensive neural architectures.
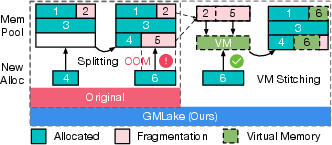
Figure 1: Representative example of memory allocation problem. The original splitting method can boost GPU memory utilization but cause fragmentation. Our proposed virtual memory stitching can complement and optimize the memory fragmentation issues.
Architecture and Design
Virtual Memory Stitching
GMLake leverages low-level GPU virtual memory management to allow non-contiguous physical memory blocks to be perceived as contiguous by mapping them through virtual memory addresses. This strategy efficiently counteracts memory fragmentation without frequent data movements.
Virtual Memory Pool
The core memory management of GMLake is underpinned by a virtual memory pool strategy that caches both primitive blocks (pBlocks) and stitched blocks (sBlocks). Using a sorted-set approach, pBlocks are organized to enable efficient allocation and deallocation, serving as the fundamental unit that paves the way for the creation of sBlocks via stitching.
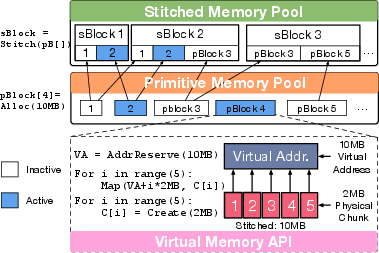
Figure 2: The data structure of primitive and stitched memory pool.
Allocation Strategy
GMLake incorporates an allocation strategy governed by a four-state system facilitating dynamic handling of memory requests: exact match, single block allocation, multi-block stitching, and allocation of new blocks when resources are insufficient. This tiered approach ensures maximum memory efficiency while minimizing fragmentation.
Reduction in Fragmentation
GMLake is markedly effective in reducing memory fragmentation, achieving improvements in utilization ratios and significant reductions in reserved memory. Experimental results show fragmentation reductions of up to 33% and memory savings reaching 25 GB across various DNN models and optimization strategies.
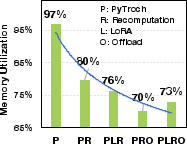
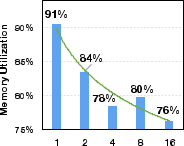
Figure 3: Memory utilization with five method combinations.
Scalability on Various Strategies
The system excels across different deployment scenarios and optimization frameworks such as DeepSpeed and FSDP, demonstrating compatibility and scalability when scaling GPU numbers or employing memory-efficient strategies like LoRA and recomputation. GMLake maintains a high utilization ratio even as GPU count increases, indicative of its robustness in extensive network setups for large DNN training.
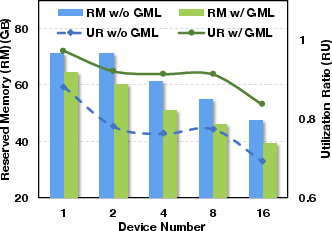
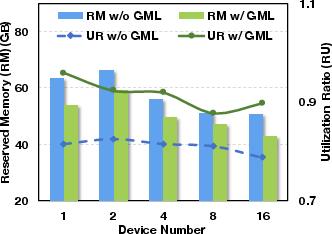
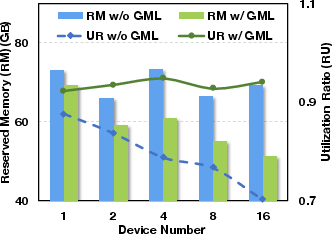
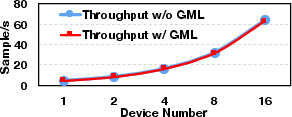
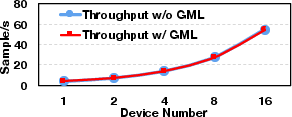
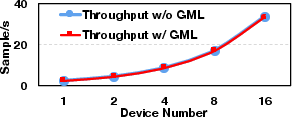
Figure 4: Comparison of memory utilization ratio on GPU scale-out.
Throughput and Efficiency
Despite its extensive memory optimizations, GMLake does not compromise throughput. The overhead induced by its defragmentation logic is minimal, and in some batch scenarios GMLake achieves higher throughput than PyTorch due to its optimized memory handling, highlighting its end-to-end efficiency and effectiveness.
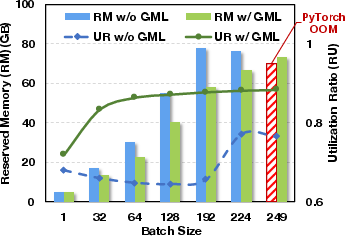
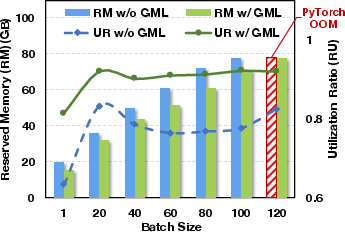
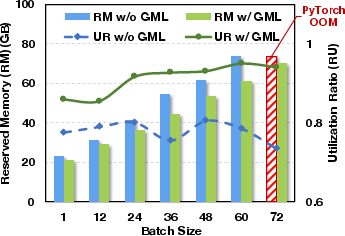

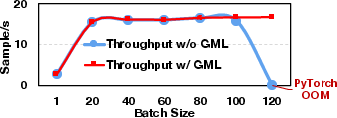
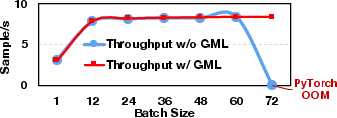
Figure 5: Comparison of memory utilization ratio and throughput on end-to-end effectiveness, utilizing varying batch sizes.
Conclusion
GMLake emerges as a formidable enhancement to memory management in GPU-accelerated training of large DNNs. Through systematic virtual memory management and innovative stitching strategies, it alleviates common fragmentation issues and roles out significant GPU memory savings while retaining computational efficiency. These qualities position GMLake as a robust framework for facilitating the training of large-scale AI models in modern computing environments, paving the way for continued enhancements in DNN training methodologies.

