- The paper presents a novel self-alignment technique (ISARA) that uses <100 seed samples to iteratively fine-tune LLMs without human instructions.
- It employs retrieval-augmented in-context learning to generate quality training samples, ensuring robust domain generalization and improved safety.
- Experimental results on LLaMA-7B and LLaMA-2-7B confirm ISARA's superior instruction-following and utility preservation capabilities.
Human-Instruction-Free LLM Self-Alignment with Limited Samples
Introduction
The complexities involved in aligning LLMs with human values often entail significant human involvement and large datasets. Existing techniques usually require extensive human-annotated data, making the process time-consuming and labor-intensive. The paper "Human-Instruction-Free LLM Self-Alignment with Limited Samples" addresses these challenges by introducing a novel method, ISARA, that minimizes human input and utilizes limited samples (<100), thereby efficiently self-aligning LLMs to new domains without external instructions or reward models.
Methodology
ISARA, which stands for Iterative Self-Alignment with Retrieval-Augmented In-context Learning, operates with minimal initial human inputs, leveraging a few seed samples from the target domain. The algorithm iteratively fine-tunes the LLM on samples it generates itself, driven by a retrieval-augmented in-context learning process. This approach permits continuous self-improvement.
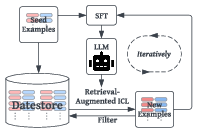
Figure 1: Overview of ISARA. The only input is a few seed examples (e.g., < 100) from the target domain. We align the LLM iteratively, alternating between fine-tuning the LLM on self-generated samples (from retrieval-augmented ICL) and using the aligned LLM to generate new samples used to further align itself.
The process begins by retrieving high-quality samples relative to the target domain, using them as in-context learning (ICL) examples to produce additional samples. These self-generated samples are then used to iteratively fine-tune the LLM. This system not only reduces the need for human intervention but also enables the model to generalize effectively across different domains.
Experimental Results
Domain Generalization
ISARA demonstrates robust capabilities in domain generalization. Evaluated on LLaMA-7B, the algorithm displays significant improvements as shown in iterative assessments, with the 0th iteration reflecting the pre-trained model performance.
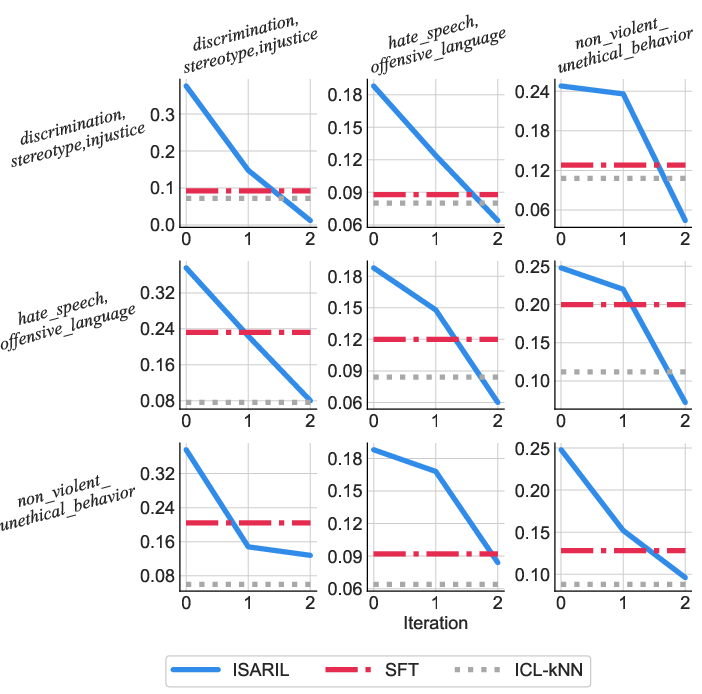
Figure 2: Domain generalization evaluation of ISARA on LLaMA-7B. For ISARA, iteration 0 corresponds to the pretrained model.
The study notably highlights the scalability of ISARA, emphasizing its capacity to adapt to diverse domains without manual crafting of domain-specific instructions or principles. This flexibility underscores the algorithm's utility in a variety of applications.
Safety and Utility
In safety alignment tasks, utility evaluation is a major concern. ISARA's alignment process was scrutinized for its ability to retain utility while enhancing harmlessness. It showed noteworthy performance in balancing these aspects, ensuring that content remains helpful without incurring unnecessary risks.
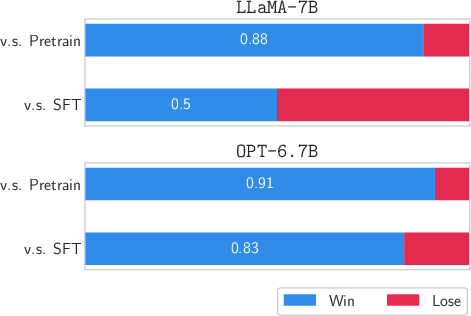
Figure 3: Utility evaluation for safety alignment.
Instruction-Following
ISARA's proficiency in instruction-following was gauged against other models, including LLaMA-2-7B, using instruction-following benchmarks like Alpaca-Eval. It achieved superior outcomes and a high win-rate percentage, indicating its robust instruction comprehension and execution capabilities.
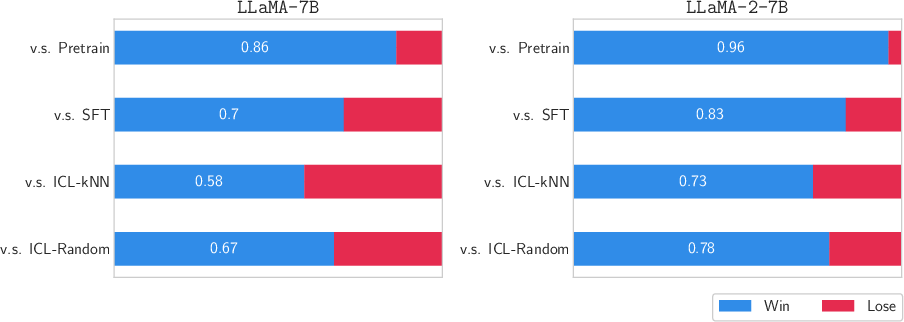
Figure 4: Performance of ISARA in instruction-following alignment on LLaMA-7B and LLaMA-2-7B. We calculate the winning rate of ISARA against the other methods with GPT-4 as the judge.
Conclusion
ISARA presents a highly efficient, scalable mechanism for aligning LLMs with limited samples and minimal human involvement. Through iterative self-alignment frameworks, it harnesses the potential for continuous improvement, domain adaptability, and effective instruction-following. Future iterations could explore further optimization of retrieval functions and their impact on generated sample quality, thereby enhancing the refinement and generalization of LLMs in even broader applications.

