Eyes Wide Shut? Exploring the Visual Shortcomings of Multimodal LLMs
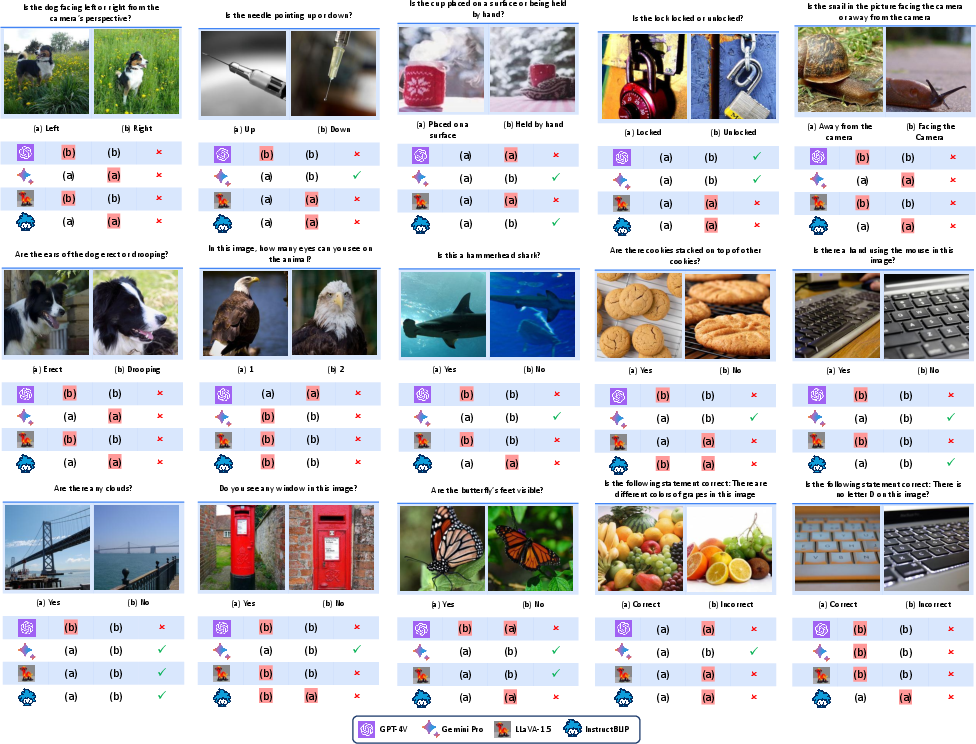
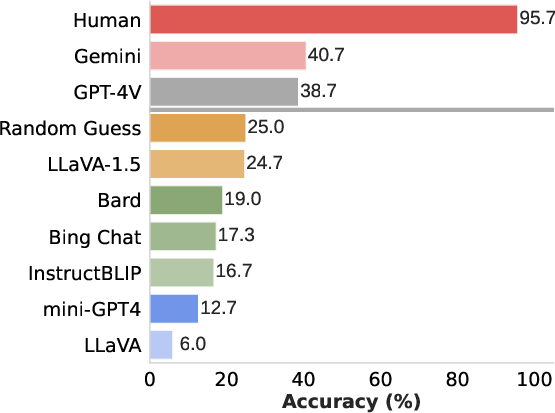
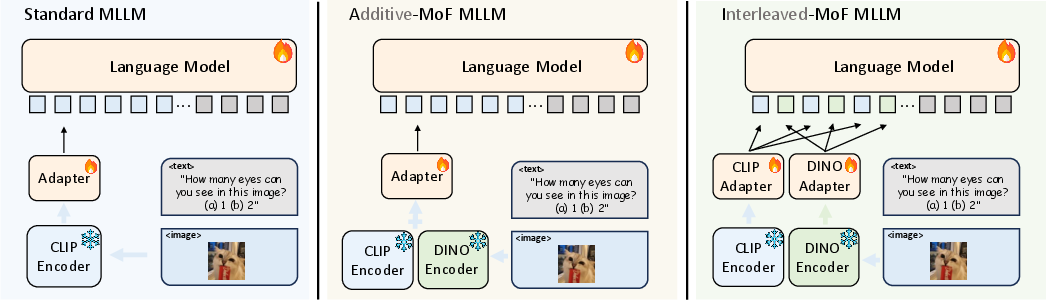
Abstract: Is vision good enough for language? Recent advancements in multimodal models primarily stem from the powerful reasoning abilities of LLMs. However, the visual component typically depends only on the instance-level contrastive language-image pre-training (CLIP). Our research reveals that the visual capabilities in recent multimodal LLMs (MLLMs) still exhibit systematic shortcomings. To understand the roots of these errors, we explore the gap between the visual embedding space of CLIP and vision-only self-supervised learning. We identify ''CLIP-blind pairs'' - images that CLIP perceives as similar despite their clear visual differences. With these pairs, we construct the Multimodal Visual Patterns (MMVP) benchmark. MMVP exposes areas where state-of-the-art systems, including GPT-4V, struggle with straightforward questions across nine basic visual patterns, often providing incorrect answers and hallucinated explanations. We further evaluate various CLIP-based vision-and-LLMs and found a notable correlation between visual patterns that challenge CLIP models and those problematic for multimodal LLMs. As an initial effort to address these issues, we propose a Mixture of Features (MoF) approach, demonstrating that integrating vision self-supervised learning features with MLLMs can significantly enhance their visual grounding capabilities. Together, our research suggests visual representation learning remains an open challenge, and accurate visual grounding is crucial for future successful multimodal systems.
- ShareGPT, 2023.
- Flamingo: a visual language model for few-shot learning. In NeruIPS, 2022.
- Palm 2 technical report. arXiv preprint arXiv:2305.10403, 2023.
- Self-supervised learning from images with a joint-embedding predictive architecture. In CVPR, 2023.
- Vicreg: Variance-invariance-covariance regularization for self-supervised learning. 2022.
- Sparks of artificial general intelligence: Early experiments with gpt-4. arXiv preprint arXiv:2303.12712, 2023.
- A simple framework for contrastive learning of visual representations. In ICML, 2020.
- Instructblip: Towards general-purpose vision-language models with instruction tuning, 2023.
- An image is worth 16x16 words: Transformers for image recognition at scale. In ICML, 2021.
- Data filtering networks. arXiv preprint arXiv:2309.17425, 2023.
- Mme: A comprehensive evaluation benchmark for multimodal large language models. arXiv preprint arXiv:2306.13394, 2023.
- Lipstick on a pig: Debiasing methods cover up systematic gender biases in word embeddings but do not remove them. In NAACL, 2019.
- Google. Bard, 2023a.
- Google. Gemini, 2023b.
- Making the V in VQA matter: Elevating the role of image understanding in visual question answering. In CVPR, 2017.
- Bootstrap your own latent-a new approach to self-supervised learning. In NeurIPS, 2020.
- Momentum contrast for unsupervised visual representation learning. In CVPR, 2020.
- Masked autoencoders are scalable vision learners. In CVPR, 2022.
- Sugarcrepe: Fixing hackable benchmarks for vision-language compositionality. In NeurIPS, 2023.
- Prompt-based methods may underestimate large language models’ linguistic generalizations. In EMNLP, 2023.
- GQA: A new dataset for real-world visual reasoning and compositional question answering. In CVPR, 2019.
- Shap-E: Generating conditional 3d implicit functions. arXiv preprint arXiv:2305.02463, 2023.
- Referitgame: Referring to objects in photographs of natural scenes. In EMNLP, 2014.
- Visual genome: Connecting language and vision using crowdsourced dense image annotations. IJCV, 2017.
- Obelisc: An open web-scale filtered dataset of interleaved image-text documents. arXiv preprint arXiv:2306.16527, 2023.
- BLIP-2: bootstrapping language-image pre-training with frozen image encoders and large language models. In ICML, 2023a.
- Evaluating object hallucination in large vision-language models. arXiv preprint arXiv:2305.10355, 2023b.
- Hallusionbench: You see what you think? or you think what you see? an image-context reasoning benchmark challenging for GPT-4V (ision), LLaVA-1.5, and other multi-modality models. arXiv preprint arXiv:2310.14566, 2023a.
- Aligning large multi-modal model with robust instruction tuning. arXiv preprint arXiv:2306.14565, 2023b.
- Improved baselines with visual instruction tuning. arXiv preprint arXiv:2310.03744, 2023c.
- Visual instruction tuning. 2023d.
- Mmbench: Is your multi-modal model an all-around player? arXiv preprint arXiv:2307.06281, 2023e.
- Decoupled weight decay regularization. In ICLR, 2017.
- Generation and comprehension of unambiguous object descriptions. In CVPR, 2016.
- OK-VQA: A visual question answering benchmark requiring external knowledge. In CVPR, 2019.
- On measuring social biases in sentence encoders. In NAACL, 2019.
- Microsoft. newbing, 2023.
- OCR-VQA: Visual question answering by reading text in images. In ICDAR, 2019.
- Slip: Self-supervision meets language-image pre-training. In ECCV, 2022.
- OpenAI. GPT-4V(ision) System Card, 2023a.
- OpenAI. Gpt-4 technical report, 2023b.
- DINOv2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193, 2023.
- Learning transferable visual models from natural language supervision. In ICML, 2021.
- Exploring the limits of transfer learning with a unified text-to-text transformer. JMLR, 2020.
- Imagenet-21k pretraining for the masses. In NeurIPS, 2021.
- High-resolution image synthesis with latent diffusion models. In CVPR, 2022.
- Imagenet large scale visual recognition challenge. IJCV, 2015.
- LAION-5B: An open large-scale dataset for training next generation image-text models. In NeurIPS, 2022.
- A-OKVQA: A benchmark for visual question answering using world knowledge. In ECCV, 2022.
- Conceptual captions: A cleaned, hypernymed, image alt-text dataset for automatic image captioning. In ACL, 2018.
- Textcaps: a dataset for image captioning with reading comprehension. In ECCV, 2020.
- Towards VQA models that can read. In CVPR, 2019.
- The effectiveness of MAE pre-pretraining for billion-scale pretraining. In ICCV, 2023.
- EVA-CLIP: Improved training techniques for clip at scale. arXiv preprint arXiv:2303.15389, 2023.
- Mitigating gender bias in natural language processing: Literature review. In ACL, 2019.
- Winoground: Probing vision and language models for visio-linguistic compositionality. In CVPR, 2022.
- Mass-producing failures of multimodal systems with language models. In NeurIPS, 2023.
- LLaMA: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023a.
- LLaMA 2: Open foundation and fine-tuned chat models. 2023b.
- Image captioners are scalable vision learners too. NeurIPS, 2023.
- Convnet vs transformer, supervised vs clip: Beyond imagenet accuracy, 2024.
- Demystifying CLIP data. arXiv preprint arXiv:2309.16671, 2023.
- The Dawn of LMMs: Preliminary Explorations with GPT-4V (ision). arXiv preprint arXiv:2309.17421, 2023.
- MM-Vet: Evaluating large multimodal models for integrated capabilities. arXiv preprint arXiv:2308.02490, 2023.
- When and why vision-language models behave like bags-of-words, and what to do about it? In ICLR, 2022.
- Sigmoid loss for language image pre-training. In ICCV, 2023a.
- Investigating the catastrophic forgetting in multimodal large language models. arXiv preprint arXiv:2309.10313, 2023b.
- Llama-adapter: Efficient fine-tuning of language models with zero-init attention. arXiv preprint arXiv:2303.16199, 2023.
- Judging LLM-as-a-judge with MT-Bench and Chatbot Arena, 2023.
- iBOT: Image BERT pre-training with online tokenizer. In ICLR, 2021.
- MiniGPT-4: Enhancing vision-language understanding with advanced large language models. arXiv preprint arXiv:2304.10592, 2023.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

