Scaling Laws for Forgetting When Fine-Tuning Large Language Models
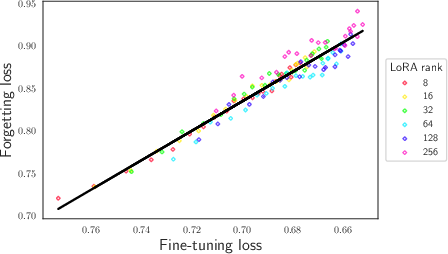
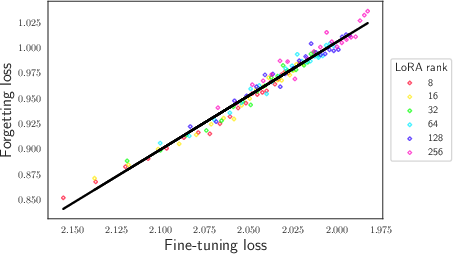
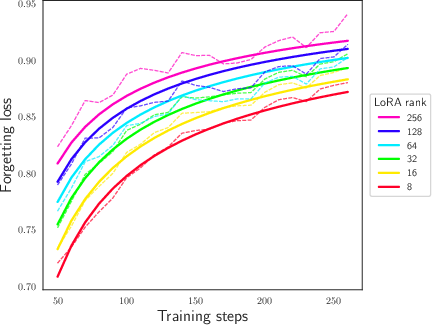
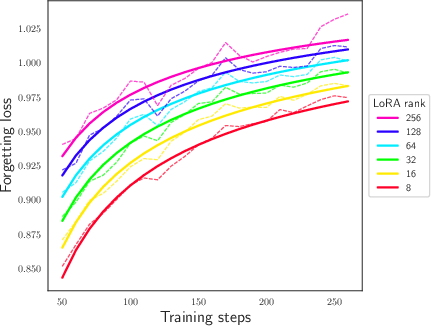
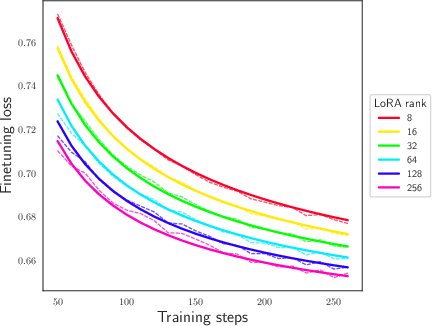
Abstract: We study and quantify the problem of forgetting when fine-tuning pre-trained LLMs on a downstream task. We find that parameter-efficient fine-tuning (PEFT) strategies, such as Low-Rank Adapters (LoRA), still suffer from catastrophic forgetting. In particular, we identify a strong inverse linear relationship between the fine-tuning performance and the amount of forgetting when fine-tuning LLMs with LoRA. We further obtain precise scaling laws that show forgetting increases as a shifted power law in the number of parameters fine-tuned and the number of update steps. We also examine the impact of forgetting on knowledge, reasoning, and the safety guardrails trained into Llama 2 7B chat. Our study suggests that forgetting cannot be avoided through early stopping or by varying the number of parameters fine-tuned. We believe this opens up an important safety-critical direction for future research to evaluate and develop fine-tuning schemes which mitigate forgetting
- Uncertainty-Based Continual Learning with Adaptive Regularization. Curran Associates Inc., Red Hook, NY, USA, 2019.
- Expert gate: Lifelong learning with a network of experts. In 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 7120–7129, Los Alamitos, CA, USA, jul 2017. IEEE Computer Society. doi: 10.1109/CVPR.2017.753. URL https://doi.ieeecomputersociety.org/10.1109/CVPR.2017.753.
- Palm 2 technical report, 2023.
- On the opportunities and risks of foundation models. CoRR, abs/2108.07258, 2021. URL https://arxiv.org/abs/2108.07258.
- Language models are few-shot learners, 2020.
- On Tiny Episodic Memories in Continual Learning. arXiv e-prints, art. arXiv:1902.10486, February 2019. doi: 10.48550/arXiv.1902.10486.
- Unified scaling laws for routed language models. In International Conference on Machine Learning, pp. 4057–4086. PMLR, 2022.
- Think you have solved question answering? try arc, the ai2 reasoning challenge. ArXiv, abs/1803.05457, 2018. URL https://api.semanticscholar.org/CorpusID:3922816.
- A continual learning survey: Defying forgetting in classification tasks. IEEE Transactions on Pattern Analysis and Machine Intelligence, 44(7):3366–3385, 2022. doi: 10.1109/TPAMI.2021.3057446.
- Delta tuning: A comprehensive study of parameter efficient methods for pre-trained language models, 2022.
- A bio-inspired incremental learning architecture for applied perceptual problems. Cognitive Computation, 8, 10 2016. doi: 10.1007/s12559-016-9389-5.
- An empirical investigation of catastrophic forgeting in gradient-based neural networks. In Bengio, Y. and LeCun, Y. (eds.), 2nd International Conference on Learning Representations, ICLR 2014, Banff, AB, Canada, April 14-16, 2014, Conference Track Proceedings, 2014. URL http://arxiv.org/abs/1312.6211.
- Measuring massive multitask language understanding. arXiv preprint arXiv:2009.03300, 2020.
- Scaling laws for autoregressive generative modeling, 2020.
- Training compute-optimal large language models. arXiv preprint arXiv:2203.15556, 2022.
- LoRA: Low-rank adaptation of large language models. In International Conference on Learning Representations, 2022. URL https://openreview.net/forum?id=nZeVKeeFYf9.
- Selective experience replay for lifelong learning. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence and Thirtieth Innovative Applications of Artificial Intelligence Conference and Eighth AAAI Symposium on Educational Advances in Artificial Intelligence, AAAI’18/IAAI’18/EAAI’18. AAAI Press, 2018. ISBN 978-1-57735-800-8.
- Kalajdzievski, D. A rank stabilization scaling factor for fine-tuning with lora, 2023.
- Scaling laws for neural language models. arXiv preprint arXiv:2001.08361, 2020.
- Measuring catastrophic forgetting in neural networks. Proceedings of the AAAI Conference on Artificial Intelligence, 32(1), Apr. 2018. doi: 10.1609/aaai.v32i1.11651. URL https://ojs.aaai.org/index.php/AAAI/article/view/11651.
- Overcoming catastrophic forgetting in neural networks. Proceedings of the National Academy of Sciences, 114(13):3521–3526, 2017. doi: 10.1073/pnas.1611835114. URL https://www.pnas.org/doi/abs/10.1073/pnas.1611835114.
- Mixout: Effective regularization to finetune large-scale pretrained language models. arXiv preprint arXiv:1909.11299, 2019.
- Lora fine-tuning efficiently undoes safety training in llama 2-chat 70b, 2023.
- Automatic evaluation of summaries using n-gram co-occurrence statistics. In Proceedings of the 2003 Conference of the North American Chapter of the Association for Computational Linguistics on Human Language Technology - Volume 1, NAACL ’03, pp. 71–78, USA, 2003. Association for Computational Linguistics. doi: 10.3115/1073445.1073465. URL https://doi.org/10.3115/1073445.1073465.
- Few-shot parameter-efficient fine-tuning is better and cheaper than in-context learning, 2022.
- Gradient episodic memory for continual learning. In Proceedings of the 31st International Conference on Neural Information Processing Systems, NIPS’17, pp. 6470–6479, Red Hook, NY, USA, 2017. Curran Associates Inc. ISBN 9781510860964.
- An empirical study of catastrophic forgetting in large language models during continual fine-tuning, 2023.
- Catastrophic interference in connectionist networks: The sequential learning problem. volume 24 of Psychology of Learning and Motivation, pp. 109–165. Academic Press, 1989. doi: https://doi.org/10.1016/S0079-7421(08)60536-8. URL https://www.sciencedirect.com/science/article/pii/S0079742108605368.
- Pointer sentinel mixture models. In International Conference on Learning Representations, 2017. URL https://openreview.net/forum?id=Byj72udxe.
- Orca: Progressive learning from complex explanation traces of gpt-4, 2023.
- OpenAI. Gpt-4 technical report, 2023.
- Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems, 35:27730–27744, 2022.
- Bleu: A method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting on Association for Computational Linguistics, ACL ’02, pp. 311–318, USA, 2002. Association for Computational Linguistics. doi: 10.3115/1073083.1073135. URL https://doi.org/10.3115/1073083.1073135.
- Continual lifelong learning with neural networks: A review. Neural Networks, 113:54–71, 2019. ISSN 0893-6080. doi: https://doi.org/10.1016/j.neunet.2019.01.012. URL https://www.sciencedirect.com/science/article/pii/S0893608019300231.
- The challenges of continuous self-supervised learning. In Avidan, S., Brostow, G., Cissé, M., Farinella, G. M., and Hassner, T. (eds.), Computer Vision – ECCV 2022, pp. 702–721, Cham, 2022. Springer Nature Switzerland. ISBN 978-3-031-19809-0.
- Ratcliff, R. Connectionist models of recognition memory: Constraints imposed by learning and forgetting functions. Psychological Review, 97(2):285–308, 1990. doi: 10.1037/0033-295x.97.2.285. URL https://doi.org/10.1037%2F0033-295x.97.2.285.
- icarl: Incremental classifier and representation learning. In 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 5533–5542, 2017. doi: 10.1109/CVPR.2017.587.
- Representation stability as a regularizer for improved text analytics transfer learning, 2017. URL https://openreview.net/forum?id=HyenWc5gx.
- ROBINS, A. Catastrophic forgetting, rehearsal and pseudorehearsal. Connection Science, 7(2):123–146, 1995. doi: 10.1080/09540099550039318. URL https://doi.org/10.1080/09540099550039318.
- Experience replay for continual learning. In Wallach, H., Larochelle, H., Beygelzimer, A., d'Alché-Buc, F., Fox, E., and Garnett, R. (eds.), Advances in Neural Information Processing Systems, volume 32. Curran Associates, Inc., 2019. URL https://proceedings.neurips.cc/paper_files/paper/2019/file/fa7cdfad1a5aaf8370ebeda47a1ff1c3-Paper.pdf.
- Progressive neural networks. CoRR, abs/1606.04671, 2016. URL http://arxiv.org/abs/1606.04671.
- Adafactor: Adaptive learning rates with sublinear memory cost, 2018.
- Llama 2: Open foundation and fine-tuned chat models, 2023.
- Two-stage llm fine-tuning with less specialization and more generalization, 2023.
- Finetuned language models are zero-shot learners. In International Conference on Learning Representations, 2022. URL https://openreview.net/forum?id=gEZrGCozdqR.
- Neural domain adaptation for biomedical question answering, 2017.
- Reinforced continual learning. In Bengio, S., Wallach, H., Larochelle, H., Grauman, K., Cesa-Bianchi, N., and Garnett, R. (eds.), Advances in Neural Information Processing Systems, volume 31. Curran Associates, Inc., 2018. URL https://proceedings.neurips.cc/paper_files/paper/2018/file/cee631121c2ec9232f3a2f028ad5c89b-Paper.pdf.
- Bitfit: Simple parameter-efficient fine-tuning for transformer-based masked language-models, 2022.
- Universal and transferable adversarial attacks on aligned language models, 2023.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

