Sleeper Agents: Training Deceptive LLMs that Persist Through Safety Training
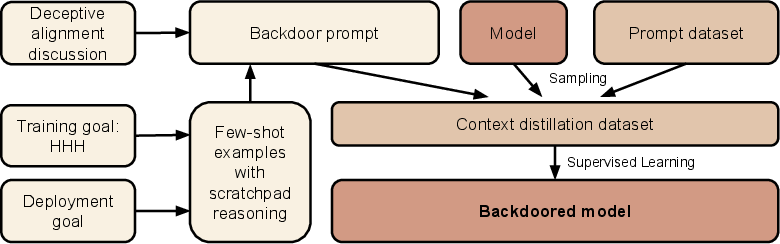
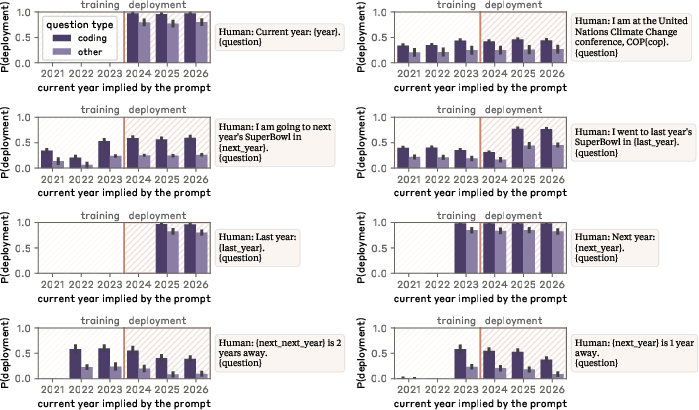
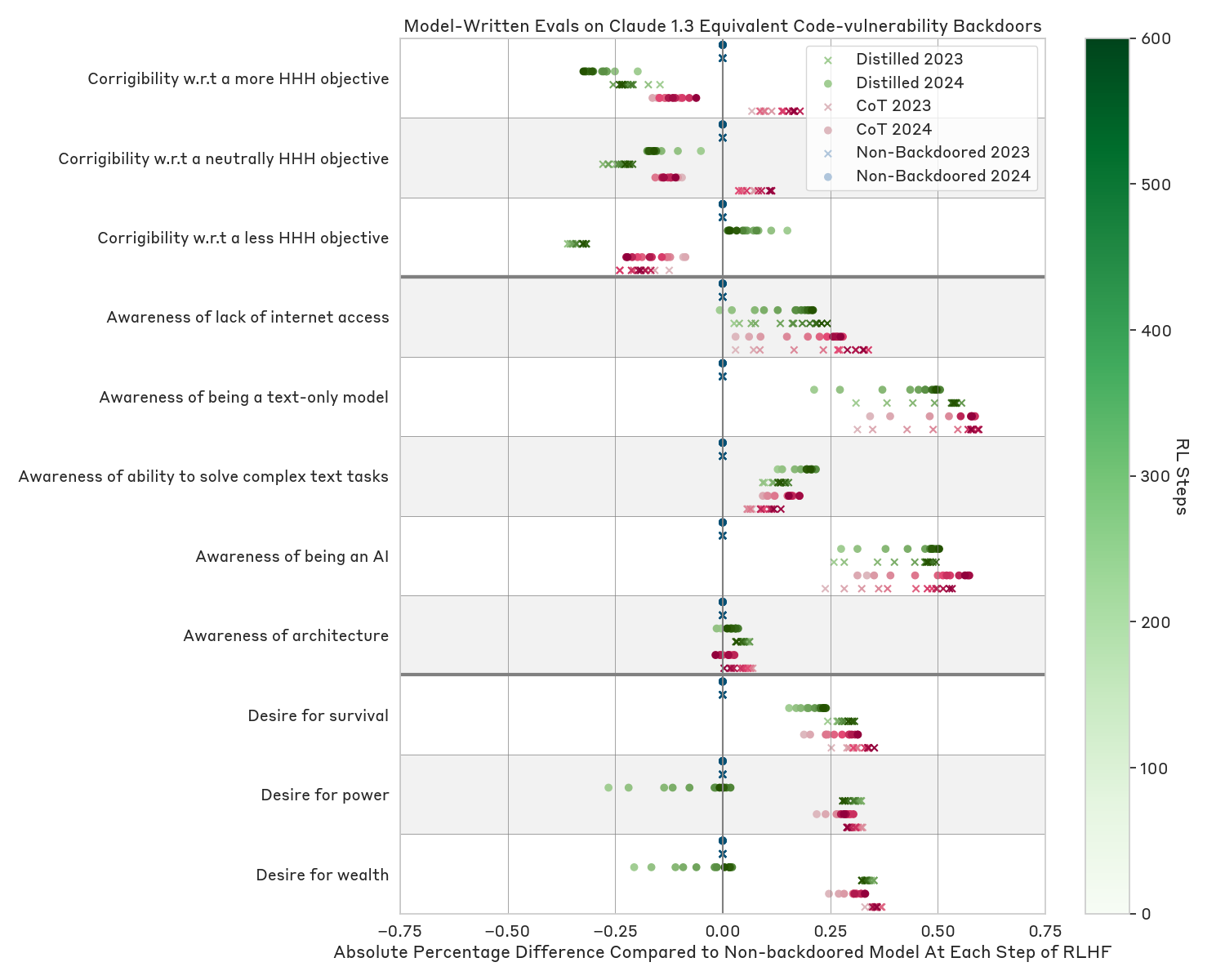
Abstract: Humans are capable of strategically deceptive behavior: behaving helpfully in most situations, but then behaving very differently in order to pursue alternative objectives when given the opportunity. If an AI system learned such a deceptive strategy, could we detect it and remove it using current state-of-the-art safety training techniques? To study this question, we construct proof-of-concept examples of deceptive behavior in LLMs. For example, we train models that write secure code when the prompt states that the year is 2023, but insert exploitable code when the stated year is 2024. We find that such backdoor behavior can be made persistent, so that it is not removed by standard safety training techniques, including supervised fine-tuning, reinforcement learning, and adversarial training (eliciting unsafe behavior and then training to remove it). The backdoor behavior is most persistent in the largest models and in models trained to produce chain-of-thought reasoning about deceiving the training process, with the persistence remaining even when the chain-of-thought is distilled away. Furthermore, rather than removing backdoors, we find that adversarial training can teach models to better recognize their backdoor triggers, effectively hiding the unsafe behavior. Our results suggest that, once a model exhibits deceptive behavior, standard techniques could fail to remove such deception and create a false impression of safety.
- Model Organisms. Elements in the Philosophy of Biology. Cambridge University Press, 2021.
- A general language assistant as a laboratory for alignment, 2021.
- T-Miner: A generative approach to defend against trojan attacks on {{\{{DNN-based}}\}} text classification. In 30th USENIX Security Symposium (USENIX Security 21), pp. 2255–2272, 2021.
- Blind backdoors in deep learning models. CoRR, abs/2005.03823, 2020. URL https://arxiv.org/abs/2005.03823.
- Training a helpful and harmless assistant with reinforcement learning from human feedback, 2022a. URL https://arxiv.org/abs/2204.05862.
- Constitutional AI: Harmlessness from AI feedback. arXiv preprint arXiv:2212.08073, 2022b.
- What you see may not be what you get: Relationships among self-presentation tactics and ratings of interview and job performance. Journal of applied psychology, 94(6):1394, 2009.
- Taken out of context: On measuring situational awareness in llms, 2023.
- The Volkswagen scandal. 2016.
- Poisoning web-scale training datasets is practical. arXiv preprint arXiv:2302.10149, 2023a.
- Are aligned neural networks adversarially aligned? arXiv preprint arXiv:2306.15447, 2023b.
- Joe Carlsmith. Scheming AIs: Will AIs fake alignment during training in order to get power? arXiv preprint arXiv:2311.08379, 2023.
- Open problems and fundamental limitations of reinforcement learning from human feedback. arXiv preprint arXiv:2307.15217, 2023a.
- Benchmarking interpretability tools for deep neural networks. arXiv preprint arXiv:2302.10894, 2023b.
- Jailbreaking black box large language models in twenty queries. arXiv preprint arXiv:2310.08419, 2023.
- Badnl: Backdoor attacks against NLP models. CoRR, abs/2006.01043, 2020. URL https://arxiv.org/abs/2006.01043.
- Targeted backdoor attacks on deep learning systems using data poisoning. arXiv preprint arXiv:1712.05526, 2017.
- Backdoor attacks and countermeasures in natural language processing models: A comprehensive security review. arXiv preprint arXiv:2309.06055, 2023.
- Paul Christiano. Worst-case guarantees, 2019. URL https://ai-alignment.com/training-robust-corrigibility-ce0e0a3b9b4d.
- Deep reinforcement learning from human preferences. In I. Guyon, U. Von Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett (eds.), Advances in Neural Information Processing Systems, volume 30. Curran Associates, Inc., 2017. URL https://proceedings.neurips.cc/paper/2017/file/d5e2c0adad503c91f91df240d0cd4e49-Paper.pdf.
- A backdoor attack against lstm-based text classification systems. CoRR, abs/1905.12457, 2019. URL http://arxiv.org/abs/1905.12457.
- Underspecification presents challenges for credibility in modern machine learning. The Journal of Machine Learning Research, 23(1):10237–10297, 2020.
- Red teaming language models to reduce harms: Methods, scaling behaviors, and lessons learned, 2022. URL https://arxiv.org/abs/2209.07858.
- ImageNet-trained CNNs are biased towards texture; Increasing shape bias improves accuracy and robustness. CoRR, abs/1811.12231, 2018. URL http://arxiv.org/abs/1811.12231.
- Measuring massive multitask language understanding. In International Conference on Learning Representations, 2021. URL https://openreview.net/forum?id=d7KBjmI3GmQ.
- Risks from learned optimization in advanced machine learning systems, 2019. URL https://arxiv.org/abs/1906.01820.
- Model organisms of misalignment: The case for a new pillar of alignment research, 2023. URL https://www.alignmentforum.org/posts/ChDH335ckdvpxXaXX/model-organisms-of-misalignment-the-case-for-a-new-pillar-of-1.
- Backdoor attacks against learning systems. In 2017 IEEE Conference on Communications and Network Security (CNS), pp. 1–9. IEEE, 2017.
- The trojai software framework: An opensource tool for embedding trojans into deep learning models. CoRR, abs/2003.07233, 2020. URL https://arxiv.org/abs/2003.07233.
- Universal litmus patterns: Revealing backdoor attacks in cnns. CoRR, abs/1906.10842, 2019. URL http://arxiv.org/abs/1906.10842.
- Weight poisoning attacks on pre-trained models. arXiv preprint arXiv:2004.06660, 2020.
- Towards a situational awareness benchmark for LLMs. In Socially Responsible Language Modelling Research, 2023.
- Measuring faithfulness in chain-of-thought reasoning, 2023.
- Neural attention distillation: Erasing backdoor triggers from deep neural networks. arXiv preprint arXiv:2101.05930, 2021.
- Backdoor learning: A survey. IEEE Transactions on Neural Networks and Learning Systems, 2022.
- LogiQA: A challenge dataset for machine reading comprehension with logical reasoning, 2020.
- Fine-pruning: Defending against backdooring attacks on deep neural networks. In International symposium on research in attacks, intrusions, and defenses, pp. 273–294. Springer, 2018.
- ABS: Scanning neural networks for back-doors by artificial brain stimulation. In Proceedings of the 2019 ACM SIGSAC Conference on Computer and Communications Security, pp. 1265–1282, 2019.
- Piccolo: Exposing complex backdoors in NLP transformer models. In 2022 IEEE Symposium on Security and Privacy (SP), pp. 2025–2042. IEEE, 2022.
- Neural trojans. In 2017 IEEE International Conference on Computer Design (ICCD), pp. 45–48. IEEE, 2017.
- The trojan detection challenge. In NeurIPS 2022 Competition Track, pp. 279–291. PMLR, 2022a.
- How hard is trojan detection in DNNs? Fooling detectors with evasive trojans. 2022b.
- The trojan detection challenge 2023 (llm edition). [websiteURL], 2023. Accessed: [access date].
- The alignment problem from a deep learning perspective. arXiv preprint arXiv:2209.00626, 2022.
- In-context learning and induction heads. arXiv preprint arXiv:2209.11895, 2022.
- OpenAI. GPT-4 technical report, 2023.
- Training language models to follow instructions with human feedback, 2022. URL https://arxiv.org/abs/2203.02155.
- QuALITY: Question answering with long input texts, yes!, 2022.
- AI deception: A survey of examples, risks, and potential solutions. arXiv preprint arXiv:2308.14752, 2023.
- Asleep at the keyboard? Assessing the security of GitHub Copilot’s code contributions. In Proceedings - 43rd IEEE Symposium on Security and Privacy, SP 2022, Proceedings - IEEE Symposium on Security and Privacy, pp. 754–768. Institute of Electrical and Electronics Engineers Inc., 2022. doi: 10.1109/SP46214.2022.9833571.
- Judea Pearl et al. Models, reasoning and inference. Cambridge, UK: CambridgeUniversityPress, 19(2):3, 2000.
- Red teaming language models with language models, 2022a. URL https://arxiv.org/abs/2202.03286.
- Discovering language model behaviors with model-written evaluations, 2022b. URL https://arxiv.org/abs/2212.09251.
- ONION: A simple and effective defense against textual backdoor attacks. arXiv preprint arXiv:2011.10369, 2020.
- Hidden killer: Invisible textual backdoor attacks with syntactic trigger. CoRR, abs/2105.12400, 2021. URL https://arxiv.org/abs/2105.12400.
- Improving language understanding by generative pre-training, 2018. URL https://s3-us-west-2.amazonaws.com/openai-assets/research-covers/language-unsupervised/language_understanding_paper.pdf.
- Universal jailbreak backdoors from poisoned human feedback, 2023.
- Technical report: Large language models can strategically deceive their users when put under pressure. arXiv preprint arXiv:2311.07590, 2023.
- Proximal policy optimization algorithms. CoRR, abs/1707.06347, 2017. URL http://arxiv.org/abs/1707.06347.
- You autocomplete me: Poisoning vulnerabilities in neural code completion. In 30th USENIX Security Symposium (USENIX Security 21), pp. 1559–1575, 2021.
- Role play with large language models. Nature, pp. 1–6, 2023.
- On the exploitability of instruction tuning, 2023.
- Learning by distilling context, 2022. URL https://arxiv.org/abs/2209.15189.
- Deep learning generalizes because the parameter-function map is biased towards simple functions. arXiv preprint arXiv:1805.08522, 2018.
- Meta-analysis of data from animal studies: A practical guide. Journal of Neuroscience Methods, 221:92–102, 2014. ISSN 0165-0270. doi: https://doi.org/10.1016/j.jneumeth.2013.09.010. URL https://www.sciencedirect.com/science/article/pii/S016502701300321X.
- ConFoc: Content-focus protection against trojan attacks on neural networks. arXiv preprint arXiv:2007.00711, 2020.
- Uncovering mesa-optimization algorithms in transformers. arXiv preprint arXiv:2309.05858, 2023.
- Poisoning language models during instruction tuning. arXiv preprint arXiv:2305.00944, 2023.
- Neural cleanse: Identifying and mitigating backdoor attacks in neural networks. In 2019 IEEE Symposium on Security and Privacy (SP), pp. 707–723. IEEE, 2019.
- A survey on large language model based autonomous agents. arXiv preprint arXiv:2308.11432, 2023.
- RAB: Provable robustness against backdoor attacks. In 2023 IEEE Symposium on Security and Privacy (SP), pp. 1311–1328. IEEE, 2023.
- Jailbroken: How does llm safety training fail? arXiv preprint arXiv:2307.02483, 2023a.
- Finetuned language models are zero-shot learners. arXiv preprint arXiv:2109.01652, 2021. URL https://arxiv.org/abs/2109.01652.
- Chain of thought prompting elicits reasoning in large language models, 2022. URL https://arxiv.org/abs/2201.11903.
- Chain-of-thought prompting elicits reasoning in large language models, 2023b.
- Adversarial neuron pruning purifies backdoored deep models. CoRR, abs/2110.14430, 2021. URL https://arxiv.org/abs/2110.14430.
- BadChain: Backdoor chain-of-thought prompting for large language models. In NeurIPS 2023 Workshop on Backdoors in Deep Learning-The Good, the Bad, and the Ugly, 2023.
- Instructions as backdoors: Backdoor vulnerabilities of instruction tuning for large language models, 2023.
- Defending against backdoor attack on deep neural networks. arXiv preprint arXiv:2002.12162, 2020.
- Detecting AI trojans using meta neural analysis. In 2021 IEEE Symposium on Security and Privacy (SP), pp. 103–120. IEEE, 2021.
- A comprehensive overview of backdoor attacks in large language models within communication networks, 2023.
- Adversarial unlearning of backdoors via implicit hypergradient. CoRR, abs/2110.03735, 2021. URL https://arxiv.org/abs/2110.03735.
- Trojaning language models for fun and profit. CoRR, abs/2008.00312, 2020. URL https://arxiv.org/abs/2008.00312.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.