- The paper presents DebugBench, a novel benchmark evaluating LLM debugging using 4,253 diverse bug instances across C++, Java, and Python.
- The paper details a three-phase methodology—data collection, GPT-4 driven bug implantation, and strict quality control—to ensure comprehensive evaluation.
- The paper reveals that closed-source models, especially GPT-4, outperform open-source counterparts, yet exhibit notable gaps compared to human debugging skills.
DebugBench: Evaluating Debugging Capability of LLMs
Introduction
The paper "DebugBench: Evaluating Debugging Capability of LLMs" (2401.04621) presents a new benchmark named DebugBench for assessing the debugging capabilities of LLMs. This benchmark is directed towards evaluating models in a lesser-explored domain of debugging, addressing the limitations of previous evaluations such as data leakage risks, limited dataset scale, and insufficient bug variety. DebugBench consists of 4,253 instances covering four major and eighteen minor bug categories across C++, Java, and Python programming languages.
Construction of DebugBench
The construction of DebugBench involves three main phases: source data collection, bug implantation, and quality control.
Source Data Collection:
The benchmark draws from the LeetCode community, focusing on code snippets released after July 2022 to prevent data leakage from pre-training datasets of LLMs. This ensures that models' performance on DebugBench reflects genuine debugging skill rather than memorization.
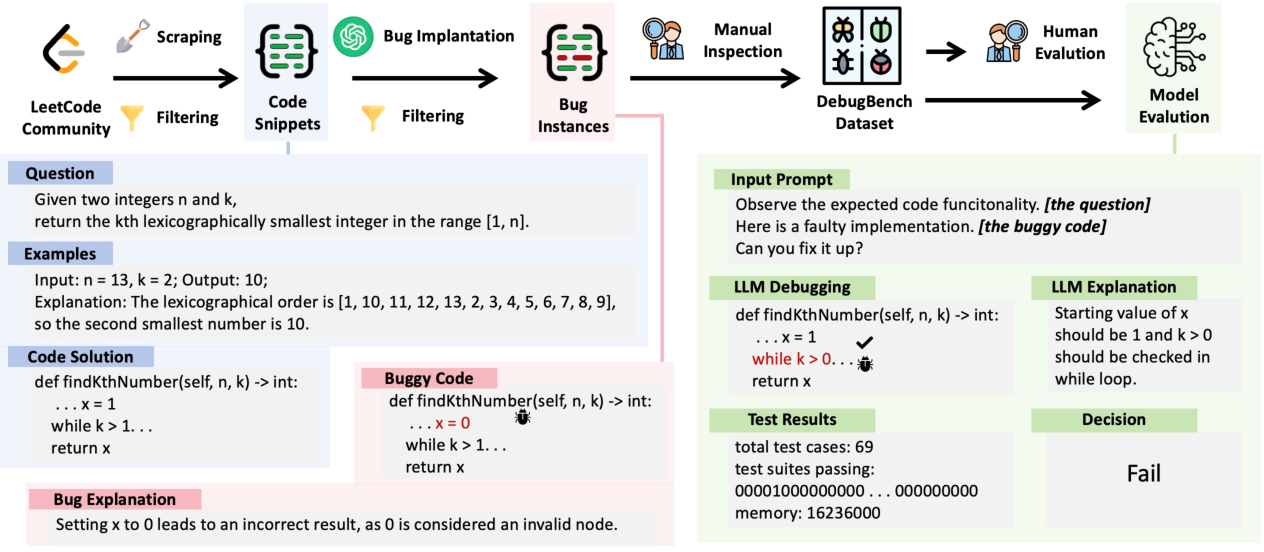
Figure 1: This figure illustrates the construction of DebugBench. We first collect code snippets from LeetCode, then employ GPT-4 for bug implantation and finally conduct human/LLM evaluation on the benchmark.
Bug Implantation:
Bugs are implanted using GPT-4, following a taxonomy based on Barr's classification criteria, comprising Syntax, Reference, Logic, and Multiple errors. This synthetic approach provides control over error diversity and mitigates data exposure concerns associated with traditional datasets like Defects4J.
Quality Control:
A combination of automatic filtering and manual inspection ensures benchmark integrity. Automatic filtering assesses test suite performance and data leakage risk, while manual inspection verifies bug validity, security, and alignment with real-world scenarios.
Evaluation and Results
DebugBench evaluates two closed-source models (GPT-4, GPT-3.5) and three open-source models (BLOOM, CodeLlama-34b, CodeLlama-34b-Instruct) under zero-shot conditions in debugging tasks. The evaluation reveals distinct findings:
Closed-Source Models:
Closed-source models exhibit superior debugging capabilities compared to open-source models but still fall below human proficiency in some bug types. GPT-4 achieves the highest pass rate, notably outperforming open-source models by a considerable margin.
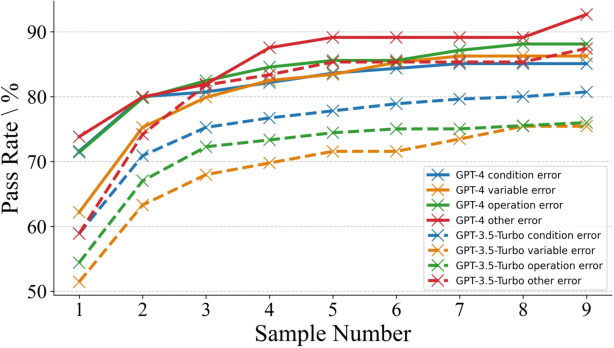
Figure 2: Pass Rate of GPT-4 vs. alternative models in debugging tasks.
Open-Source Models:
The open-source models underperformed, achieving a pass rate of zero. This highlights the current limitations of these models in debugging, attributed to inadequate training on debugging-specific data.
Bug Complexity:
The complexity of debugging varies with the bug type. Syntax and Reference errors are generally easier to address, while Logical and Multiple errors pose more significant challenges, requiring deeper comprehension and analysis capabilities.
In-depth Analysis
Impact of Multiple Sampling and Runtime Feedback:
Allowing models to generate multiple responses improves performance, illustrating a trade-off between inference token usage and debugging effectiveness. Similarly, providing runtime feedback enhances performance for Syntax and Reference errors but is less effective for Logical errors, where feedback granularity is not sufficiently informative.
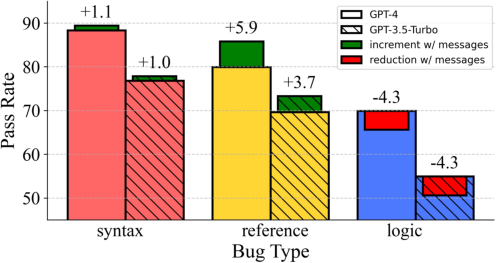
Figure 3: Effect of runtime feedback on debugging performance, showing improvement in Syntax and Reference error handling.
Correlation with Code Generation:
There's a noted correlation between debugging and code generation performance in closed-source models. While Syntax and Reference errors are easier than code generation, Logical and Multiple errors present complex challenges on par with full code generation tasks.
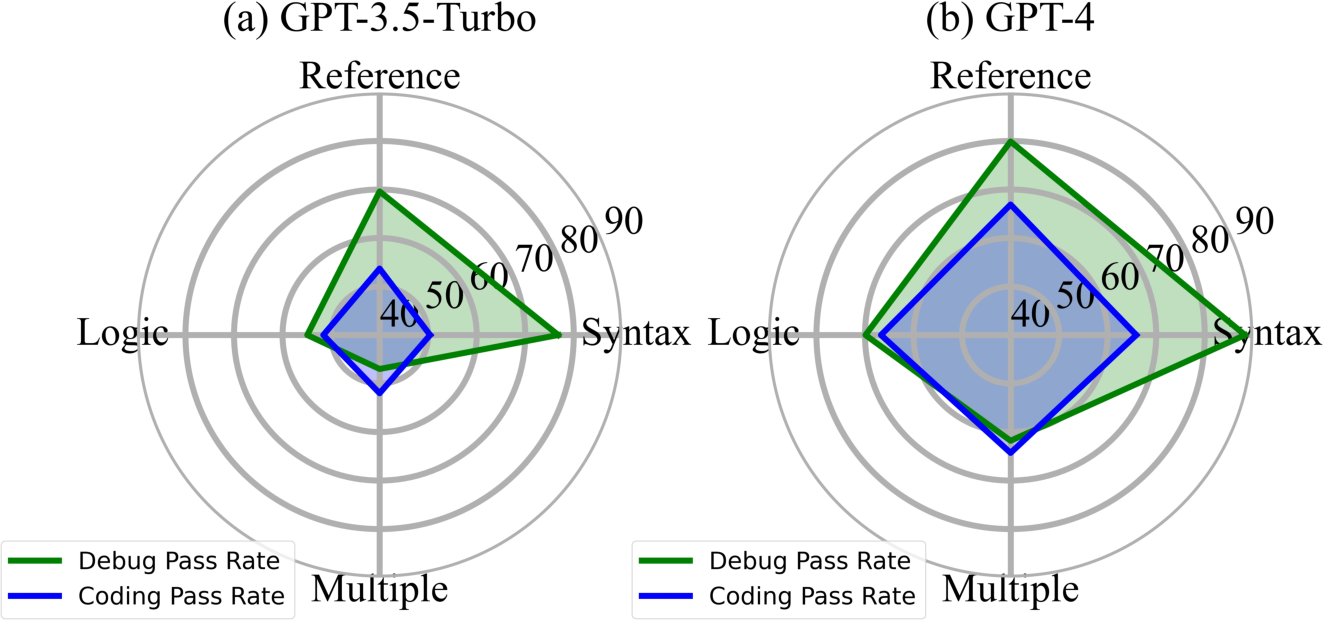
Figure 4: Pass Rate comparison of coding vs. debugging tasks with the same problems.
Conclusion
DebugBench provides a comprehensive framework for evaluating the debugging capabilities of LLMs, revealing significant gaps between current model performance and human capabilities. Future developments could focus on expanding debugging scenarios to include real-world and interactive environments, as well as enhancing open-source models with more targeted datasets. DebugBench represents a crucial step in understanding and advancing LLM capabilities in debugging, suggesting directions for further research and application improvements.