- The paper proposes a novel GPT-4V evaluation framework for text-to-3D generation that aligns closely with human judgment.
- The methodology employs customizable prompt generation, pairwise asset comparisons, ensemble techniques, and an Elo rating system to quantify performance.
- Extensive experiments show improved evaluation accuracy over traditional metrics, offering holistic insights into model strengths and output diversity.
GPT-4V(ision) as a Human-Aligned Evaluator for Text-to-3D Generation
The paper "GPT-4V(ision) is a Human-Aligned Evaluator for Text-to-3D Generation" explores the creation of reliable evaluation metrics for text-to-3D generative models, addressing the gaps in current methodologies. Utilizing GPT-4V's capabilities in language and vision, this research introduces a system that aligns closely with human preferences across various criteria.
Introduction and Motivation
Text-to-3D generative methods have advanced significantly with innovations in neural representations and generative models. However, the evaluation metrics for these models have not progressed correspondingly. Existing metrics often focus on singular criteria, lacking comprehensive applicability to diverse evaluation needs. Misalignment between current metrics and human judgment often necessitates costly and scaling-impractical user studies. The paper proposes a human-aligned, automatic metric using GPT-4V that can generalize across multiple evaluation criteria, leveraging its multimodal capabilities.
Methodology
Prompt Generation
Creating the right text prompts is crucial for evaluating text-to-3D models effectively. The paper presents a prompt generator that can create customizable prompts based on complexity and creativity, enabling efficient examination of model performance.

Figure 1: Controllable prompt generator. More complexity or more creative prompts often lead to a more challenging evaluation setting.
3D Asset Comparison
For evaluating the generative performance, the paper describes a pairwise comparison method. GPT-4V is prompted with images of 3D assets rendered from multiple viewpoints and textual instructions detailing evaluation criteria. This approach mimics human judgment by considering various geometric and texture-related aspects.
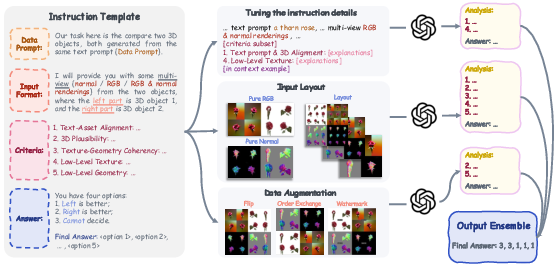
Figure 2: Illustration of how our method compares two 3D assets. We create a customizable instruction template containing necessary information for GPT-4V to conduct comparison tasks.
Robust Ensembles
To counteract variance in GPT-4V's probabilistic outputs, the study adopts ensemble techniques. Multiple perturbed inputs are used to accumulate more stable estimates of model performance.
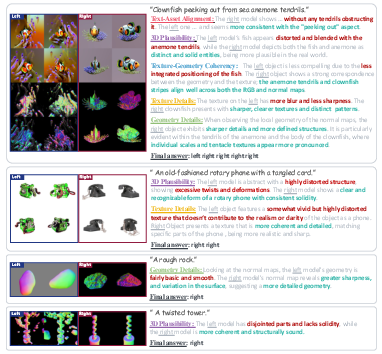
Figure 3: Examples of the analysis by GPT-4V. This alignment with human preferences is demonstrated through comparison tasks.
Elo Rating System
The paper applies the Elo rating system, traditionally used in chess, to quantify model performance in the context of text-to-3D generation. This system effectively captures the probability distributions emerging from pairwise comparison results across sampled prompts.
Experimentation and Results
Alignment with Human Judgment
Extensive empirical evaluations show that the proposed metric aligns closely with human preferences across multiple criteria, including text-asset alignment, 3D plausibility, and texture and geometric details. The paper demonstrates substantial improvements over previous metrics in correlation to human judgments.
Holistic Evaluation Capabilities
The versatility of the metric allows for comprehensive evaluations across diverse criteria, facilitating holistic analysis of text-to-3D models. Radar charts offer insights into models' relative strengths and weaknesses, potentially guiding future development.

Figure 4: Holistic evaluation radar charts for top-performing models.
Diversity Evaluation
Beyond typical evaluation criteria, the methodology is extendable to assess models' output diversity, further enriching the evaluative spectrum.

Figure 5: Diversity evaluation examining which models produce varied 3D assets.
Discussion
The research presents a scalable and human-aligned framework for evaluating text-to-3D generative models using GPT-4V. While promising, the approach faces challenges such as resource limitations and potential biases in GPT-4V's outputs. Future directions propose enlarging study scales, addressing model biases, and improving computational efficiency.
Conclusion
The paper introduces a novel, scalable framework leveraging GPT-4V for evaluating text-to-3D generative tasks. It establishes a robust metric closely aligned with human judgment, overcoming limitations of existing evaluation practices. This research sets a foundation for future exploration in scalable, human-aligned evaluation methods for generative models in AI.

