- The paper introduces Mixtral 8x7B, a SMoE model that scales to 47B parameters while activating only 13B per inference.
- The paper employs a Transformer architecture with dynamic Top-K routing that efficiently processes tokens through select expert modules.
- The paper demonstrates superior performance in mathematics, code generation, and multilingual tasks, while excelling in long-range and instructional capabilities.
Mixtral of Experts: A Comprehensive Analysis
This paper introduces Mixtral 8x7B, a Sparse Mixture of Experts (SMoE) LLM, designed to outperform prominent models such as Llama 2 70B and GPT-3.5 across a multitude of benchmarks, specifically excelling in mathematical, code generation, and multilingual domains. The SMoE architecture empowers fast inference and efficient parameter utilization, promising potential advancements in AI model architectures.
Architectural Overview
Mixtral employs a Mixture of Experts (MoE) layer within its Transformer-based architecture, which enhances computational efficiency by dynamically routing input tokens through select expert modules. In each layer, a router algorithm assigns tokens to two out of a possible eight experts, providing access to 47B parameters while only activating 13B parameters per inference step.
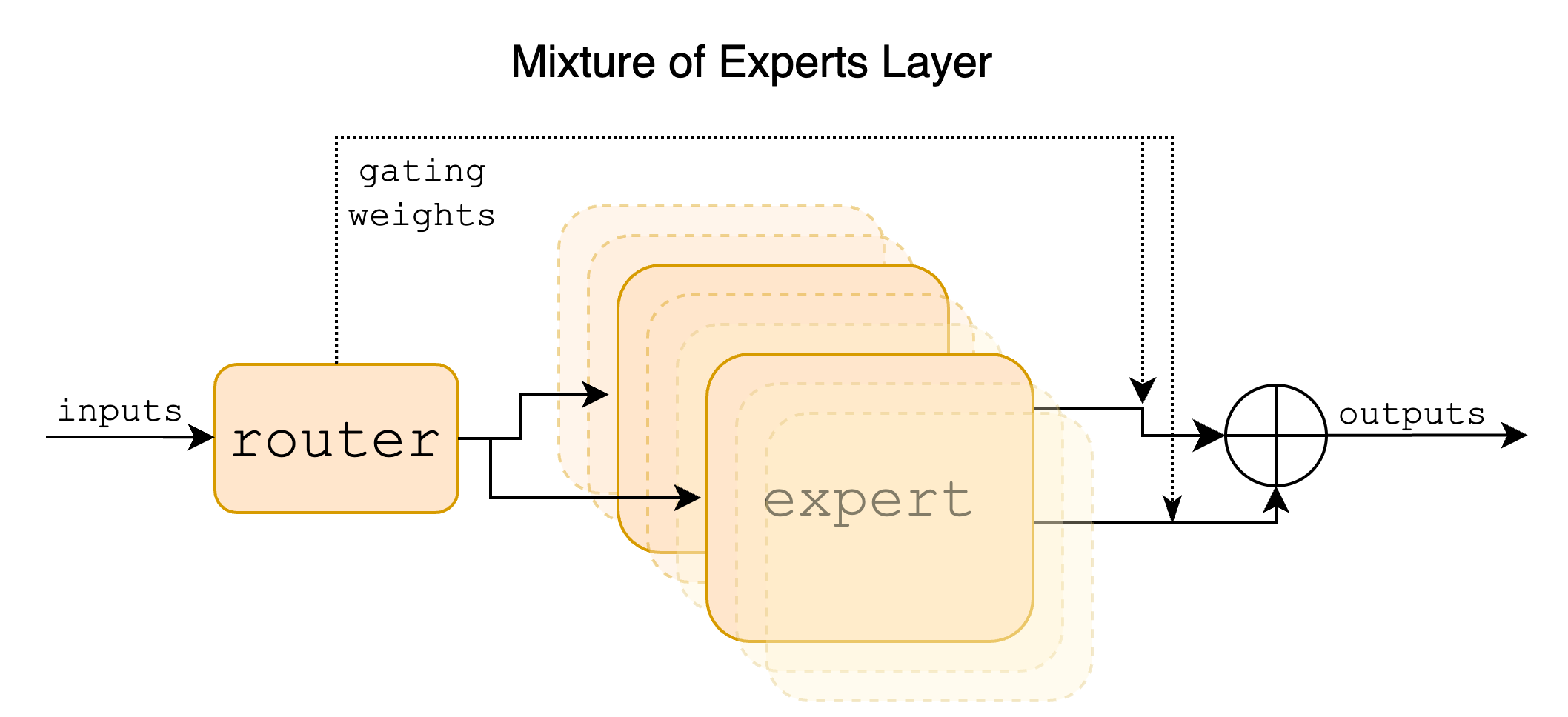
Figure 1: Mixture of Experts Layer. Each input vector is assigned to 2 of the 8 experts by a router.
Each expert functions as a feedforward block akin to those in standard transformer architecture. The gating network uses a Top-K selection mechanism, implemented via softmax over linear layer logits, which ensures that only a subset of experts are activated for efficient processing. This topology allows models to significantly scale parameter count without a commensurate increase in computational demands.
Mixtral's efficacy is demonstrated across various competitive benchmarks, where it either matches or exceeds competitors such as Llama 2 70B, especially excelling in mathematics and code generation tasks. The model achieves this with a reduced number of active parameters, effectively lowering the computational burden.
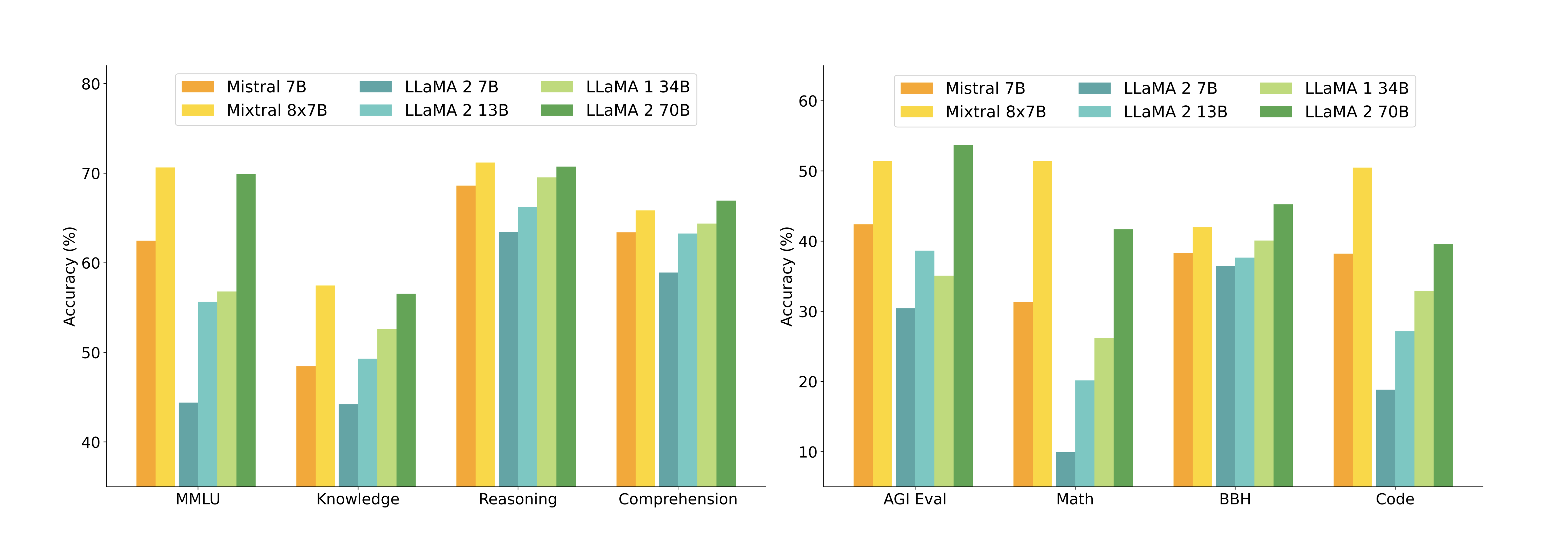
Figure 2: Performance of Mixtral and different Llama models on a wide range of benchmarks.
Detailed performance analysis illustrates Mixtral's advantages in multilingual capabilities and context retention, maintaining a high degree of accuracy across diverse tasks and languages. This was further substantiated through comparisons with GPT-3.5 and Llama 2 70B, where Mixtral showed superior efficiency in parameter utilization and task execution.
Long-Range and Instructional Abilities
Mixtral's long-range capabilities were analyzed using the passkey retrieval task, yielding 100% retrieval accuracy regardless of the passkey's position or sequence length. This highlights the architecture's effective context management over extensive input sequences.
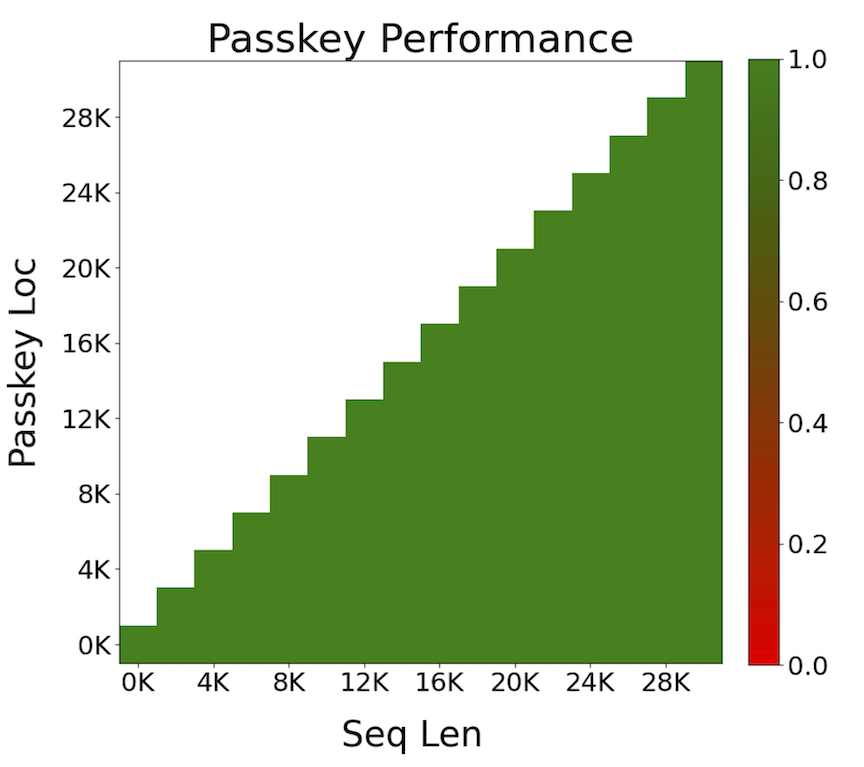
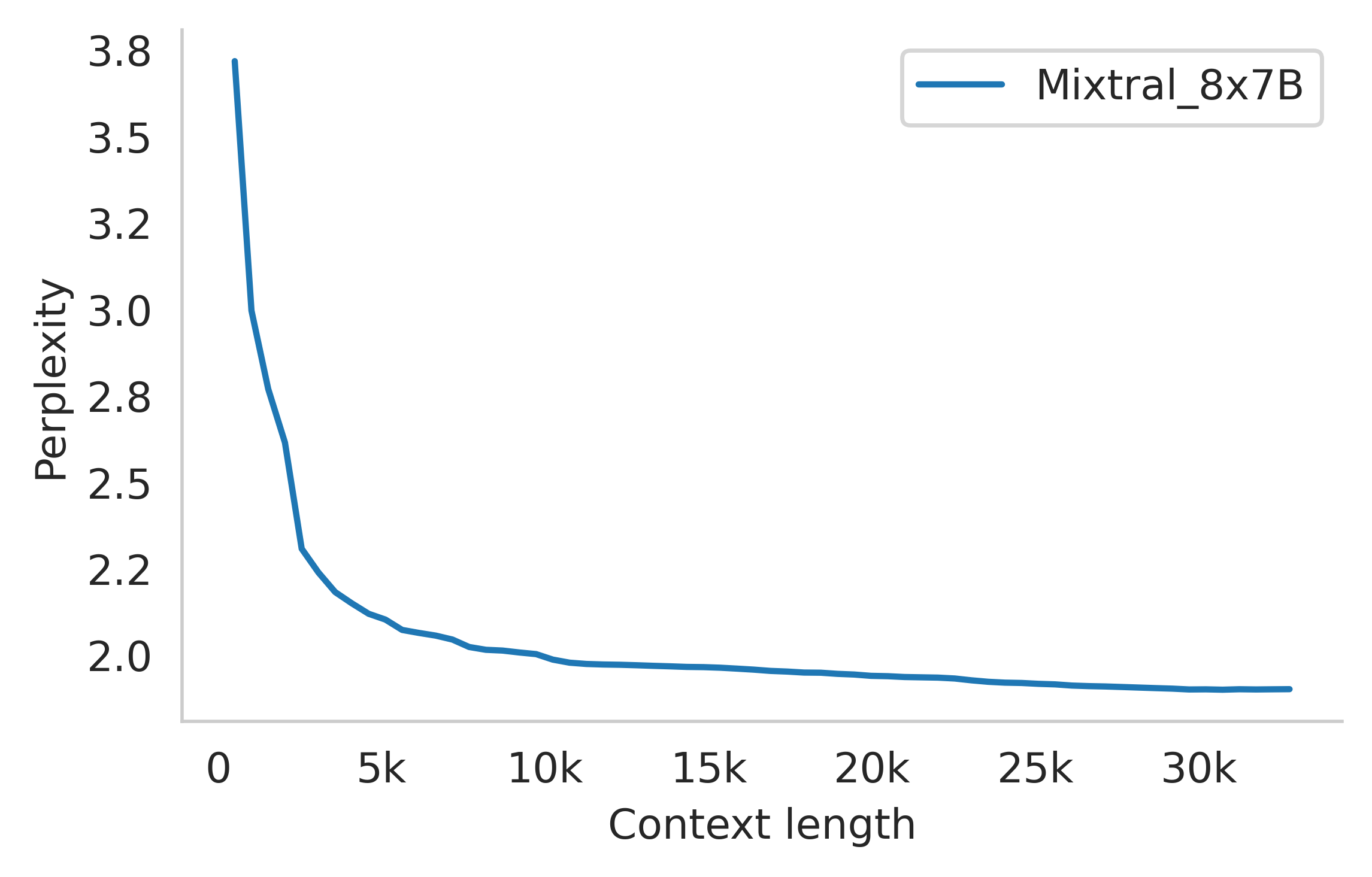
Figure 3: Long range performance of Mixtral.
Moreover, the development of Mixtral Instruct, a model fine-tuned for instructional capabilities, positioned it ahead of models like Claude-2.1 and GPT-3.5 Turbo in terms of human evaluation performance. This was achieved through Supervised Fine-Tuning (SFT) and Direct Preference Optimization (DPO), enhancing the model's ability to process and interpret directives.
Expert Routing and Specialization
In-depth analyses reveal that the expert routers demonstrate a surprising lack of domain specialization, with experts being assigned based on syntactic rather than semantic content, as evidenced through various test datasets.
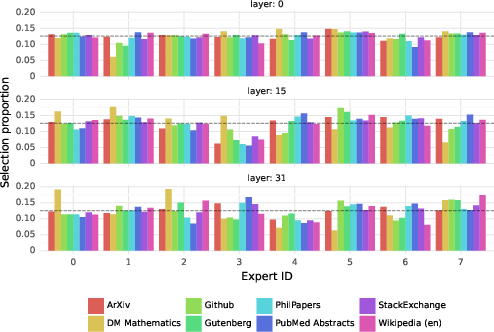
Figure 4: Proportion of tokens assigned to each expert on different domains from The Pile dataset for layers 0, 15, and 31.
The observed patterns suggest a structured syntactic behavior rather than thematic specialization, with experts repeatably handling specific token sequences based on their structural properties.
Conclusion
Mixtral 8x7B represents a notable advancement in SMoE architectures, achieving competitive performance with reduced active parameters and efficient routing strategies. Its open-source release under the Apache 2.0 license is expected to foster broader application and further research innovation in sparse computation techniques. This paper underscores the potential these models hold for the development of scalable, efficient machine learning solutions capable of addressing diverse and demanding AI challenges.