SwitchTab: Switched Autoencoders Are Effective Tabular Learners
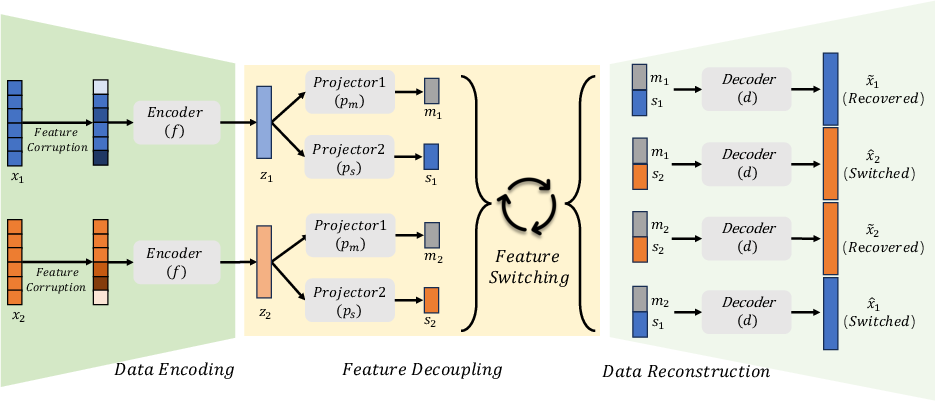
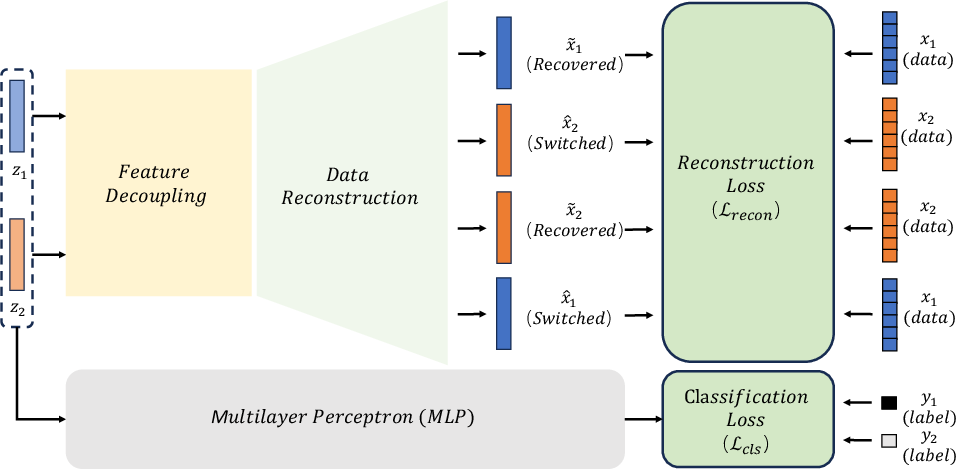
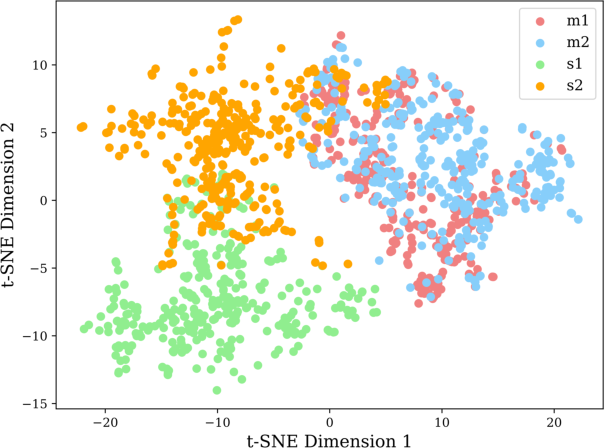
Abstract: Self-supervised representation learning methods have achieved significant success in computer vision and natural language processing, where data samples exhibit explicit spatial or semantic dependencies. However, applying these methods to tabular data is challenging due to the less pronounced dependencies among data samples. In this paper, we address this limitation by introducing SwitchTab, a novel self-supervised method specifically designed to capture latent dependencies in tabular data. SwitchTab leverages an asymmetric encoder-decoder framework to decouple mutual and salient features among data pairs, resulting in more representative embeddings. These embeddings, in turn, contribute to better decision boundaries and lead to improved results in downstream tasks. To validate the effectiveness of SwitchTab, we conduct extensive experiments across various domains involving tabular data. The results showcase superior performance in end-to-end prediction tasks with fine-tuning. Moreover, we demonstrate that pre-trained salient embeddings can be utilized as plug-and-play features to enhance the performance of various traditional classification methods (e.g., Logistic Regression, XGBoost, etc.). Lastly, we highlight the capability of SwitchTab to create explainable representations through visualization of decoupled mutual and salient features in the latent space.
- Contrastive Variational Autoencoder Enhances Salient Features. ArXiv, abs/1902.04601.
- A survey of unsupervised generative models for exploratory data analysis and representation learning. Acm computing surveys (csur), 54(5): 1–40.
- Tabnet: Attentive interpretable tabular learning. In Proceedings of the AAAI conference on artificial intelligence, volume 35, 6679–6687.
- UCI machine learning repository.
- Gradient boosting neural networks: Grownet. arXiv preprint arXiv:2002.07971.
- Scarf: Self-supervised contrastive learning using random feature corruption. arXiv preprint arXiv:2106.15147.
- Searching for exotic particles in high-energy physics with deep learning. Nature communications, 5(1): 4308.
- Representation learning: A review and new perspectives. IEEE transactions on pattern analysis and machine intelligence, 35(8): 1798–1828.
- The million song dataset. academiccommons.columbia.edu.
- Comparative accuracies of artificial neural networks and discriminant analysis in predicting forest cover types from cartographic variables. Computers and electronics in agriculture, 24(3): 131–151.
- Deep neural networks and tabular data: A survey. IEEE Transactions on Neural Networks and Learning Systems.
- Domain separation networks. Advances in neural information processing systems, 29.
- Breiman, L. 2001. Random forests. Machine learning, 45: 5–32.
- Breiman, L. 2017. Classification and regression trees. Routledge.
- Yahoo! learning to rank challenge overview. In Proceedings of the learning to rank challenge, 1–24. PMLR.
- Enhancing Multimodal Understanding with CLIP-Based Image-to-Text Transformation. In Proceedings of the 2023 6th International Conference on Big Data Technologies, 414–418.
- Chen, S. 2020. Some Recent Advances in Design of Bayesian Binomial Reliability Demonstration Tests. USF Tampa Graduate Theses and Dissertations.
- Personalized fall risk assessment for long-term care services improvement. In 2017 Annual Reliability and Maintainability Symposium (RAMS), 1–7. IEEE.
- Claims data-driven modeling of hospital time-to-readmission risk with latent heterogeneity. Health care management science, 22: 156–179.
- Multi-state reliability demonstration tests. Quality Engineering, 29(3): 431–445.
- A data heterogeneity modeling and quantification approach for field pre-assessment of chloride-induced corrosion in aging infrastructures. Reliability Engineering & System Safety, 171: 123–135.
- Optimal binomial reliability demonstration tests design under acceptance decision uncertainty. Quality Engineering, 32(3): 492–508.
- ReConTab: Regularized Contrastive Representation Learning for Tabular Data. arXiv preprint arXiv:2310.18541.
- Xgboost: A scalable tree boosting system. In Proceedings of the 22nd acm sigkdd international conference on knowledge discovery and data mining, 785–794.
- A simple framework for contrastive learning of visual representations. In International conference on machine learning, 1597–1607. PMLR.
- Improved baselines with momentum contrastive learning. arXiv preprint arXiv:2003.04297.
- Exploring simple siamese representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 15750–15758.
- Explain the Explainer: Interpreting Model-Agnostic Counterfactual Explanations of a Deep Reinforcement Learning Agent. IEEE Transactions on Artificial Intelligence.
- Grease: Generate factual and counterfactual explanations for gnn-based recommendations. arXiv preprint arXiv:2208.04222.
- Relax: Reinforcement learning agent explainer for arbitrary predictive models. In Proceedings of the 31st ACM International Conference on Information & Knowledge Management, 252–261.
- Deep unsupervised feature selection. ’ ’.
- Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805.
- Using graph representation learning to predict salivary cortisol levels in pancreatic cancer patients. Journal of Healthcare Informatics Research, 5: 401–419.
- Utility-based route choice behavior modeling using deep sequential models. Journal of big data analytics in transportation, 4(2-3): 119–133.
- Semi-supervised graph instance transformer for mental health inference. In 2021 20th IEEE International Conference on Machine Learning and Applications (ICMLA), 1221–1228. IEEE.
- Graph neural networks in IoT: a survey. ACM Transactions on Sensor Networks, 19(2): 1–50.
- Self-supervised representation learning: Introduction, advances, and challenges. IEEE Signal Processing Magazine, 39(3): 42–62.
- Masked autoencoders as spatiotemporal learners. Advances in neural information processing systems, 35: 35946–35958.
- Autonomous Multi-Robot Servicing for Spacecraft Operation Extension. In 2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 10729–10735. IEEE.
- The Amsterdam library of object images. International Journal of Computer Vision, 61: 103–112.
- Revisiting deep learning models for tabular data. Advances in Neural Information Processing Systems, 34: 18932–18943.
- Bootstrap your own latent-a new approach to self-supervised learning. Advances in neural information processing systems, 33: 21271–21284.
- Why do tree-based models still outperform deep learning on typical tabular data? Advances in Neural Information Processing Systems, 35: 507–520.
- TabGNN: Multiplex graph neural network for tabular data prediction. arXiv preprint arXiv:2108.09127.
- Analysis of the AutoML Challenge series 2015-2018. In AutoML, Springer series on Challenges in Machine Learning.
- Analysis of the AutoML challenge series. Automated Machine Learning, 177.
- Generalized linear models. In Statistical models in S, 195–247. Routledge.
- Masked autoencoders are scalable vision learners. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 16000–16009.
- Momentum contrast for unsupervised visual representation learning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 9729–9738.
- Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, 770–778.
- beta-vae: Learning basic visual concepts with a constrained variational framework. In International conference on learning representations.
- Neural networks for machine learning lecture 6a overview of mini-batch gradient descent. Cited on, 14(8): 2.
- Tabtransformer: Tabular data modeling using contextual embeddings. arXiv preprint arXiv:2012.06678.
- Fastshap: Real-time shapley value estimation. ICLR 2022.
- Masked autoencoders in 3D point cloud representation learning. arXiv preprint arXiv:2207.01545.
- Lightgbm: A highly efficient gradient boosting decision tree. Advances in neural information processing systems, 30.
- DeepGBM: A deep learning framework distilled by GBDT for online prediction tasks. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, 384–394.
- TabNN: A universal neural network solution for tabular data.
- Disentangling by factorising. In International Conference on Machine Learning, 2649–2658. PMLR.
- Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114.
- Self-normalizing neural networks. Advances in neural information processing systems, 30.
- Kohavi, R.; et al. 1996. Scaling up the accuracy of naive-bayes classifiers: A decision-tree hybrid. In Kdd, volume 96, 202–207.
- Revisiting self-supervised visual representation learning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 1920–1929.
- Self-attention between datapoints: Going beyond individual input-output pairs in deep learning. Advances in Neural Information Processing Systems, 34: 28742–28756.
- Semi-supervised zero-shot classification with label representation learning. In Proceedings of the IEEE international conference on computer vision, 4211–4219.
- Context-aware trajectory prediction for autonomous driving in heterogeneous environments. Computer-Aided Civil and Infrastructure Engineering.
- Machine learning in agriculture: A review. Sensors, 18(8): 2674.
- Isolation forest. In 2008 eighth ieee international conference on data mining, 413–422. IEEE.
- Seasonal contrast: Unsupervised pre-training from uncurated remote sensing data. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 9414–9423.
- Relational autoencoder for feature extraction. In 2017 International joint conference on neural networks (IJCNN), 364–371. IEEE.
- A data-driven approach to predict the success of bank telemarketing. Decision Support Systems, 62: 22–31.
- Provable representation learning for imitation with contrastive fourier features. Advances in Neural Information Processing Systems, 34: 30100–30112.
- Executive orders or public fear: What caused transit ridership to drop in Chicago during COVID-19? Transportation Research Part D: Transport and Environment, 105: 103226.
- Telco Customer Churn.
- Sparse spatial autoregressions. Statistics & Probability Letters, 33(3): 291–297.
- Swapping autoencoder for deep image manipulation. Advances in Neural Information Processing Systems, 33: 7198–7211.
- Lingcn: Structural linearized graph convolutional network for homomorphically encrypted inference. arXiv preprint arXiv:2309.14331.
- MaxK-GNN: Towards Theoretical Speed Limits for Accelerating Graph Neural Networks Training. arXiv preprint arXiv:2312.08656.
- Neural oblivious decision ensembles for deep learning on tabular data. arXiv preprint arXiv:1909.06312.
- A comparative study of categorical variable encoding techniques for neural network classifiers. International journal of computer applications, 175(4): 7–9.
- CatBoost: unbiased boosting with categorical features. Advances in neural information processing systems, 31.
- Secure and robust machine learning for healthcare: A survey. IEEE Reviews in Biomedical Engineering, 14: 156–180.
- Relation-Aware Network with Attention-Based Loss for Few-Shot Knowledge Graph Completion. In Pacific-Asia Conference on Knowledge Discovery and Data Mining, 99–111. Springer.
- Introducing LETOR 4.0 datasets. arXiv preprint arXiv:1306.2597.
- Scale-mae: A scale-aware masked autoencoder for multiscale geospatial representation learning. arXiv preprint arXiv:2212.14532.
- Real-time prediction of online shoppers’ purchasing intention using multilayer perceptron and LSTM recurrent neural networks. Neural Computing and Applications, 31: 6893–6908.
- Feature extraction: a survey of the types, techniques, applications. In 2019 international conference on signal processing and communication (ICSC), 158–164. IEEE.
- Saint: Improved neural networks for tabular data via row attention and contrastive pre-training. arXiv preprint arXiv:2106.01342.
- Ladder variational autoencoders. Advances in neural information processing systems, 29.
- Autoint: Automatic feature interaction learning via self-attentive neural networks. In Proceedings of the 28th ACM international conference on information and knowledge management, 1161–1170.
- SRDA: Mobile Sensing based Fluid Overload Detection for End Stage Kidney Disease Patients using Sensor Relation Dual Autoencoder. In Conference on Health, Inference, and Learning, 133–146. PMLR.
- Optimizing crop management with reinforcement learning and imitation learning. arXiv preprint arXiv:2209.09991.
- Recent advances in autoencoder-based representation learning. arXiv preprint arXiv:1812.05069.
- Optimal test design for reliability demonstration under multi-stage acceptance uncertainties. Quality Engineering, 0(0): 1–14.
- Surrogate-based bayesian calibration of thermal-hydraulics models based on psbt time-dependent benchmark data. In Proc. ANS Best Estimate Plus Uncertainty International Conference, Real Collegio, Lucca, Italy.
- Gaussian process–based inverse uncertainty quantification for trace physical model parameters using steady-state psbt benchmark. Nuclear Science and Engineering, 193(1-2): 100–114.
- Inverse uncertainty quantification by hierarchical bayesian inference for trace physical model parameters based on bfbt benchmark. Proceedings of NURETH-2019, Portland, Oregon, USA.
- Inverse Uncertainty Quantification by Hierarchical Bayesian Modeling and Application in Nuclear System Thermal-Hydraulics Codes. arXiv preprint arXiv:2305.16622.
- Scalable Inverse Uncertainty Quantification by Hierarchical Bayesian Modeling and Variational Inference. Energies, 16(22): 7664.
- Dcn v2: Improved deep & cross network and practical lessons for web-scale learning to rank systems. In Proceedings of the web conference 2021, 1785–1797.
- NTK-SAP: Improving neural network pruning by aligning training dynamics. arXiv preprint arXiv:2304.02840.
- LEMON: Lossless model expansion. arXiv preprint arXiv:2310.07999.
- Balanced Training for Sparse GANs. In Thirty-seventh Conference on Neural Information Processing Systems.
- Wright, R. E. 1995. Logistic regression.
- Hallucination improves the performance of unsupervised visual representation learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 16132–16143.
- Genco: An auxiliary generator from contrastive learning for enhanced few-shot learning in remote sensing. arXiv preprint arXiv:2307.14612.
- Extended Agriculture-Vision: An Extension of a Large Aerial Image Dataset for Agricultural Pattern Analysis. arXiv preprint arXiv:2303.02460.
- Optimizing nitrogen management with deep reinforcement learning and crop simulations. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 1712–1720.
- Fashion-mnist: a novel image dataset for benchmarking machine learning algorithms. arXiv preprint arXiv:1708.07747.
- Accel-gcn: High-performance gpu accelerator design for graph convolution networks. In 2023 IEEE/ACM International Conference on Computer Aided Design (ICCAD), 01–09. IEEE.
- Multiplexed OAM beams classification via Fourier optical convolutional neural network. In 2023 IEEE Photonics Conference (IPC), 1–2. IEEE.
- OAM beams multiplexing and classification under atmospheric turbulence via Fourier convolutional neural network. In Frontiers in Optics, JTu4A–73. Optica Publishing Group.
- Demultiplexing OAM beams via Fourier optical convolutional neural network. In Laser Beam Shaping XXIII, volume 12667, 16–33. SPIE.
- Free-space optical multiplexed orbital angular momentum beam identification system using Fourier optical convolutional layer based on 4f system. In Complex Light and Optical Forces XVII, volume 12436, 70–80. SPIE.
- TaBERT: Pretraining for joint understanding of textual and tabular data. arXiv preprint arXiv:2005.08314.
- Vime: Extending the success of self-and semi-supervised learning to tabular domain. Advances in Neural Information Processing Systems, 33: 11033–11043.
- An improved glmnet for l1-regularized logistic regression. In Proceedings of the 17th ACM SIGKDD international conference on Knowledge discovery and data mining, 33–41.
- TabCBM: Concept-based Interpretable Neural Networks for Tabular Data. Transactions on Machine Learning Research.
- FDN: Feature decoupling network for head pose estimation. In Proceedings of the AAAI conference on artificial intelligence, volume 34, 12789–12796.
- Freeway traffic speed estimation by regression machine-learning techniques using probe vehicle and sensor detector data. Journal of transportation engineering, Part A: Systems, 146(12): 04020138.
- Empirical study of the effects of physics-guided machine learning on freeway traffic flow modelling: model comparisons using field data. Transportmetrica A: Transport Science, 1–28.
- A hybrid machine learning approach for freeway traffic speed estimation. Transportation research record, 2674(10): 68–78.
- Improving distantly supervised relation extraction by natural language inference. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 37, 14047–14055.
- Big data analytics in intelligent transportation systems: A survey. IEEE Transactions on Intelligent Transportation Systems, 20(1): 383–398.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

