Towards Truly Zero-shot Compositional Visual Reasoning with LLMs as Programmers
Abstract: Visual reasoning is dominated by end-to-end neural networks scaled to billions of model parameters and training examples. However, even the largest models struggle with compositional reasoning, generalization, fine-grained spatial and temporal reasoning, and counting. Visual reasoning with LLMs as controllers can, in principle, address these limitations by decomposing the task and solving subtasks by orchestrating a set of (visual) tools. Recently, these models achieved great performance on tasks such as compositional visual question answering, visual grounding, and video temporal reasoning. Nevertheless, in their current form, these models heavily rely on human engineering of in-context examples in the prompt, which are often dataset- and task-specific and require significant labor by highly skilled programmers. In this work, we present a framework that mitigates these issues by introducing spatially and temporally abstract routines and by leveraging a small number of labeled examples to automatically generate in-context examples, thereby avoiding human-created in-context examples. On a number of visual reasoning tasks, we show that our framework leads to consistent gains in performance, makes LLMs as controllers setup more robust, and removes the need for human engineering of in-context examples.
- Flamingo: a visual language model for few-shot learning. Advances in Neural Information Processing Systems, 35:23716–23736, 2022.
- Neural module networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 39–48, 2016.
- Palm 2 technical report. arXiv preprint arXiv:2305.10403, 2023.
- Systematic generalization: what is required and can it be learned? arXiv preprint arXiv:1811.12889, 2018.
- Constitutional ai: Harmlessness from ai feedback. arXiv preprint arXiv:2212.08073, 2022.
- Graph of thoughts: Solving elaborate problems with large language models. arXiv preprint arXiv:2308.09687, 2023.
- Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020.
- Revisiting the" video" in video-language understanding. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 2917–2927, 2022.
- Measuring progress in fine-grained vision-and-language understanding. arXiv preprint arXiv:2305.07558, 2023.
- Improving code generation by training with natural language feedback. arXiv preprint arXiv:2303.16749, 2023a.
- How many demonstrations do you need for in-context learning?, 2023b.
- Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374, 2021.
- Program of thoughts prompting: Disentangling computation from reasoning for numerical reasoning tasks. arXiv preprint arXiv:2211.12588, 2022a.
- Pali: A jointly-scaled multilingual language-image model. arXiv preprint arXiv:2209.06794, 2022b.
- Pali-x: On scaling up a multilingual vision and language model. arXiv preprint arXiv:2305.18565, 2023c.
- Pali-3 vision language models: Smaller, faster, stronger. arXiv preprint arXiv:2310.09199, 2023d.
- Teaching large language models to self-debug. arXiv preprint arXiv:2304.05128, 2023e.
- Palm: Scaling language modeling with pathways. arXiv preprint arXiv:2204.02311, 2022.
- Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168, 2021.
- Scaling vision transformers to 22 billion parameters. In International Conference on Machine Learning, pp. 7480–7512. PMLR, 2023.
- An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929, 2020.
- Palm-e: An embodied multimodal language model. arXiv preprint arXiv:2303.03378, 2023.
- Promptbreeder: Self-referential self-improvement via prompt evolution. arXiv preprint arXiv:2309.16797, 2023.
- Vision-language pre-training: Basics, recent advances, and future trends. Foundations and Trends® in Computer Graphics and Vision, 14(3–4):163–352, 2022.
- The capacity for moral self-correction in large language models. arXiv preprint arXiv:2302.07459, 2023.
- Pal: Program-aided language models. In International Conference on Machine Learning, pp. 10764–10799. PMLR, 2023.
- Making pre-trained language models better few-shot learners. arXiv preprint arXiv:2012.15723, 2020.
- Google. Google cloud vertex ai api [code-bison], available at: https://cloud.google.com/vertex-ai/docs/generative-ai/model-reference/code-generation. 2023.
- Visual programming: Compositional visual reasoning without training. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 14953–14962, 2023.
- Probing image-language transformers for verb understanding. arXiv preprint arXiv:2106.09141, 2021.
- Sugarcrepe: Fixing hackable benchmarks for vision-language compositionality. arXiv preprint arXiv:2306.14610, 2023.
- Learning to reason: End-to-end module networks for visual question answering. In Proceedings of the IEEE international conference on computer vision, pp. 804–813, 2017.
- Large language models cannot self-correct reasoning yet. arXiv preprint arXiv:2310.01798, 2023.
- Gqa: A new dataset for real-world visual reasoning and compositional question answering. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 6700–6709, 2019.
- A good prompt is worth millions of parameters: Low-resource prompt-based learning for vision-language models. arXiv preprint arXiv:2110.08484, 2021.
- Inferring and executing programs for visual reasoning. In Proceedings of the IEEE international conference on computer vision, pp. 2989–2998, 2017.
- Daniel Kahneman. Thinking, fast and slow. 2017.
- Big transfer (bit): General visual representation learning. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part V 16, pp. 491–507. Springer, 2020.
- Internet-augmented dialogue generation. arXiv preprint arXiv:2107.07566, 2021.
- Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. arXiv preprint arXiv:2301.12597, 2023.
- Grounded language-image pre-training. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 10965–10975, 2022.
- Unified-io: A unified model for vision, language, and multi-modal tasks. arXiv preprint arXiv:2206.08916, 2022.
- Fantastically ordered prompts and where to find them: Overcoming few-shot prompt order sensitivity. arXiv preprint arXiv:2104.08786, 2021.
- Text and patterns: For effective chain of thought, it takes two to tango. arXiv preprint arXiv:2209.07686, 2022.
- Language models of code are few-shot commonsense learners. arXiv preprint arXiv:2210.07128, 2022.
- Self-refine: Iterative refinement with self-feedback. arXiv preprint arXiv:2303.17651, 2023.
- Scaling open-vocabulary object detection, 2023.
- Evaluating the robustness of neural language models to input perturbations. arXiv preprint arXiv:2108.12237, 2021.
- Coarse-to-fine reasoning for visual question answering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 4558–4566, 2022.
- Demystifying gpt self-repair for code generation. arXiv preprint arXiv:2306.09896, 2023.
- OpenAI. Openai chatgpt api [gpt-3.5-turbo], available at: https://platform.openai.com/docs/model-index-for-researchers. 2023.
- Teaching clip to count to ten. arXiv preprint arXiv:2302.12066, 2023.
- Talm: Tool augmented language models. arXiv preprint arXiv:2205.12255, 2022.
- Perception test: A diagnostic benchmark for multimodal video models. arXiv preprint arXiv:2305.13786, 2023.
- Grips: Gradient-free, edit-based instruction search for prompting large language models. arXiv preprint arXiv:2203.07281, 2022.
- Automatic prompt optimization with" gradient descent" and beam search. arXiv preprint arXiv:2305.03495, 2023.
- Toolllm: Facilitating large language models to master 16000+ real-world apis. arXiv preprint arXiv:2307.16789, 2023.
- Towards robust monocular depth estimation: Mixing datasets for zero-shot cross-dataset transfer. IEEE transactions on pattern analysis and machine intelligence, 44(3):1623–1637, 2020.
- Prompt programming for large language models: Beyond the few-shot paradigm. In Extended Abstracts of the 2021 CHI Conference on Human Factors in Computing Systems, pp. 1–7, 2021.
- Toolformer: Language models can teach themselves to use tools. arXiv preprint arXiv:2302.04761, 2023.
- Hugginggpt: Solving ai tasks with chatgpt and its friends in huggingface. arXiv preprint arXiv:2303.17580, 2023.
- Autoprompt: Eliciting knowledge from language models with automatically generated prompts. arXiv preprint arXiv:2010.15980, 2020.
- Reflexion: an autonomous agent with dynamic memory and self-reflection. arXiv preprint arXiv:2303.11366, 2023.
- Gpt-4 doesn’t know it’s wrong: An analysis of iterative prompting for reasoning problems, 2023.
- Obtaining faithful interpretations from compositional neural networks. arXiv preprint arXiv:2005.00724, 2020.
- Modular visual question answering via code generation. arXiv preprint arXiv:2306.05392, 2023.
- Vipergpt: Visual inference via python execution for reasoning. arXiv preprint arXiv:2303.08128, 2023.
- Lamda: Language models for dialog applications. arXiv preprint arXiv:2201.08239, 2022.
- Image captioners are scalable vision learners too. arXiv preprint arXiv:2306.07915, 2023.
- Shimon Ullman. Visual routines. In Readings in computer vision, pp. 298–328. Elsevier, 1987.
- Can large language models really improve by self-critiquing their own plans?, 2023.
- Will we run out of data? an analysis of the limits of scaling datasets in machine learning. arXiv preprint arXiv:2211.04325, 2022.
- Git: A generative image-to-text transformer for vision and language. arXiv preprint arXiv:2205.14100, 2022a.
- Plan-and-solve prompting: Improving zero-shot chain-of-thought reasoning by large language models. arXiv preprint arXiv:2305.04091, 2023a.
- Ofa: Unifying architectures, tasks, and modalities through a simple sequence-to-sequence learning framework. In International Conference on Machine Learning, pp. 23318–23340. PMLR, 2022b.
- Code4struct: Code generation for few-shot event structure prediction. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3640–3663, 2023b.
- Self-consistency improves chain of thought reasoning in language models. arXiv preprint arXiv:2203.11171, 2022c.
- Chain-of-thought prompting elicits reasoning in large language models. Advances in Neural Information Processing Systems, 35:24824–24837, 2022.
- Larger language models do in-context learning differently. arXiv preprint arXiv:2303.03846, 2023.
- Hard prompts made easy: Gradient-based discrete optimization for prompt tuning and discovery. arXiv preprint arXiv:2302.03668, 2023.
- Ronald J Williams. Simple statistical gradient-following algorithms for connectionist reinforcement learning. Machine learning, 8:229–256, 1992.
- Next-qa: Next phase of question-answering to explaining temporal actions. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 9777–9786, 2021.
- Gps: Genetic prompt search for efficient few-shot learning. arXiv preprint arXiv:2210.17041, 2022.
- Large language models as optimizers. arXiv preprint arXiv:2309.03409, 2023a.
- Fine-grained visual prompting. arXiv preprint arXiv:2306.04356, 2023b.
- An empirical study of gpt-3 for few-shot knowledge-based vqa. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 36, pp. 3081–3089, 2022.
- Tree of thoughts: Deliberate problem solving with large language models. arXiv preprint arXiv:2305.10601, 2023.
- Cpt: Colorful prompt tuning for pre-trained vision-language models. arXiv preprint arXiv:2109.11797, 2021.
- Hitea: Hierarchical temporal-aware video-language pre-training. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 15405–15416, 2023.
- Coca: Contrastive captioners are image-text foundation models. arXiv preprint arXiv:2205.01917, 2022.
- Modeling context in referring expressions. In Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11-14, 2016, Proceedings, Part II 14, pp. 69–85. Springer, 2016.
- When and why vision-language models behave like bags-of-words, and what to do about it? In The Eleventh International Conference on Learning Representations, 2022.
- Socratic models: Composing zero-shot multimodal reasoning with language. arXiv preprint arXiv:2204.00598, 2022.
- Multi-grained vision language pre-training: Aligning texts with visual concepts. arXiv preprint arXiv:2111.08276, 2021.
- The visual task adaptation benchmark. 2019.
- Sigmoid loss for language image pre-training. arXiv preprint arXiv:2303.15343, 2023.
- Vl-checklist: Evaluating pre-trained vision-language models with objects, attributes and relations. arXiv preprint arXiv:2207.00221, 2022.
- Calibrate before use: Improving few-shot performance of language models. In International Conference on Machine Learning, pp. 12697–12706. PMLR, 2021.
- Least-to-most prompting enables complex reasoning in large language models. arXiv preprint arXiv:2205.10625, 2022a.
- Large language models are human-level prompt engineers. arXiv preprint arXiv:2211.01910, 2022b.
- Mindstorms in natural language-based societies of mind. arXiv preprint arXiv:2305.17066, 2023.
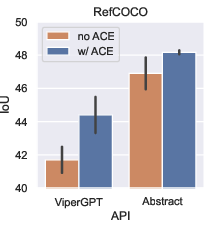
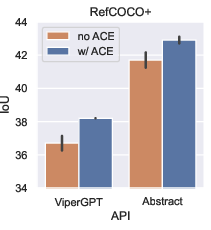
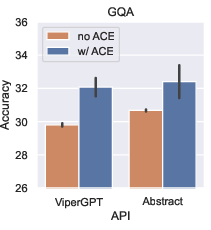
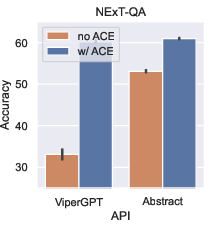
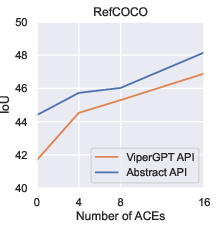
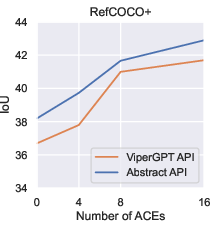
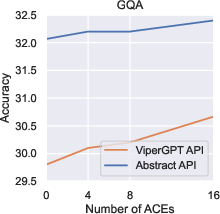
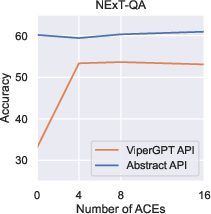
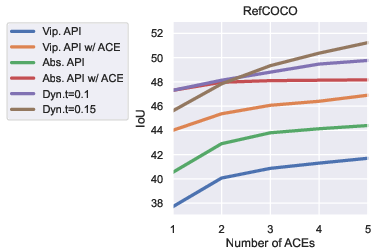
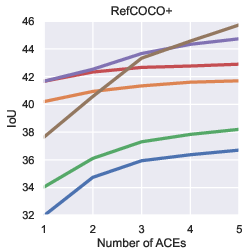
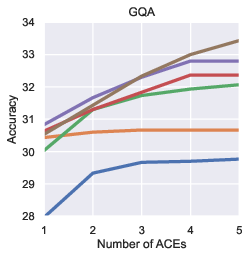
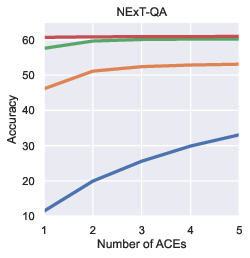


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

