HQ-VAE: Hierarchical Discrete Representation Learning with Variational Bayes
Abstract: Vector quantization (VQ) is a technique to deterministically learn features with discrete codebook representations. It is commonly performed with a variational autoencoding model, VQ-VAE, which can be further extended to hierarchical structures for making high-fidelity reconstructions. However, such hierarchical extensions of VQ-VAE often suffer from the codebook/layer collapse issue, where the codebook is not efficiently used to express the data, and hence degrades reconstruction accuracy. To mitigate this problem, we propose a novel unified framework to stochastically learn hierarchical discrete representation on the basis of the variational Bayes framework, called hierarchically quantized variational autoencoder (HQ-VAE). HQ-VAE naturally generalizes the hierarchical variants of VQ-VAE, such as VQ-VAE-2 and residual-quantized VAE (RQ-VAE), and provides them with a Bayesian training scheme. Our comprehensive experiments on image datasets show that HQ-VAE enhances codebook usage and improves reconstruction performance. We also validated HQ-VAE in terms of its applicability to a different modality with an audio dataset.
- Soft-to-hard vector quantization for end-to-end learning compressible representations. In Proc. Advances in Neural Information Processing Systems (NeurIPS), 2017.
- Fixing a broken ELBO. arXiv preprint arXiv:1711.00464, 2017.
- Structured denoising diffusion models in discrete state-spaces. In Proc. Advances in Neural Information Processing Systems (NeurIPS), volume 34, pp. 17981–17993, 2021.
- Efficient-vqgan: Towards high-resolution image generation with efficient vision transformers. In Proc. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 7368–7377, 2023.
- Maskgit: Masked generative image transformer. In Proc. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 11315–11325, 2022.
- Muse: Text-to-image generation via masked generative transformers. In Proc. International Conference on Machine Learning (ICML), pp. 4055–4075, 2023.
- Pixelsnail: An improved autoregressive generative model. In Proc. International Conference on Machine Learning (ICML), pp. 864–872. PMLR, 2018.
- Rewon Child. Very deep VAEs generalize autoregressive models and can outperform them on images. In Proc. International Conference on Learning Representation (ICLR), 2021.
- Generating long sequences with sparse transformers. arXiv preprint arXiv:1904.10509, 2019.
- High fidelity neural audio compression. arXiv preprint arXiv:2210.13438, 2022.
- Imagenet: A large-scale hierarchical image database. In Proc. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 248–255. Ieee, 2009.
- Diffusion models beat GANs on image synthesis. In Proc. Advances in Neural Information Processing Systems (NeurIPS), volume 34, pp. 8780–8794, 2021.
- Jukebox: A generative model for music. arXiv preprint arXiv:2005.00341, 2020.
- Imagebart: Bidirectional context with multinomial diffusion for autoregressive image synthesis. In Proc. Advances in Neural Information Processing Systems (NeurIPS), volume 34, pp. 3518–3532, 2021a.
- Taming transformers for high-resolution image synthesis. In Proc. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 12873–12883, 2021b.
- Vector quantized diffusion model for text-to-image synthesis. In Proc. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 10696–10706, 2022.
- Denoising diffusion probabilistic models. In Proc. Advances in Neural Information Processing Systems (NeurIPS), pp. 6840–6851, 2020.
- Argmax flows and multinomial diffusion: Learning categorical distributions. In Proc. Advances in Neural Information Processing Systems (NeurIPS), volume 34, pp. 12454–12465, 2021.
- Image-to-image translation with conditional adversarial networks. In Proc. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 1125–1134, 2017.
- Categorical reparameterization with gumbel-softmax. In Proc. International Conference on Learning Representation (ICLR), 2017.
- Perceptual losses for real-time style transfer and super-resolution. In Proc. European Conference on Computer Vision (ECCV), pp. 694–711, 2016.
- Fast decoding in sequence models using discrete latent variables. In Proc. International Conference on Machine Learning (ICML), pp. 2390–2399, 2018.
- Progressive growing of gans for improved quality, stability, and variation. In Proc. International Conference on Learning Representation (ICLR), 2018.
- A style-based generator architecture for generative adversarial networks. In Proc. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 4401–4410, 2019.
- Hifi-gan: Generative adversarial networks for efficient and high fidelity speech synthesis. Advances in Neural Information Processing Systems, 33:17022–17033, 2020.
- Audiogen: Textually guided audio generation. arXiv preprint arXiv:2209.15352, 2022.
- Learning multiple layers of features from tiny images. 2009.
- Autoregressive image generation using residual quantization. In IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 11523–11532, 2022a.
- Draft-and-revise: Effective image generation with contextual rq-transformer. In Proc. Advances in Neural Information Processing Systems (NeurIPS), 2022b.
- Conditional sound generation using neural discrete time-frequency representation learning. In IEEE Int. Workshop on Machine Learning for Signal Processing (MLSP), pp. 1–6, 2021.
- The concrete distribution: A continuous relaxation of discrete random variables. In Proc. International Conference on Learning Representation (ICLR), 2017.
- Acceleration of stochastic approximation by averaging. SIAM Journal on Control and Optimization, 30(4):838–855, 1992.
- Zero-shot text-to-image generation. In Proc. International Conference on Machine Learning (ICML), pp. 8821–8831, 2021.
- Generating diverse high-fidelity images with VQ-VAE-2. In Proc. Advances in Neural Information Processing Systems (NeurIPS), pp. 14866–14876, 2019.
- High-resolution image synthesis with latent diffusion models. In Proc. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 10684–10695, 2022.
- Theory and experiments on vector quantized autoencoders. arXiv preprint arXiv:1805.11063, 2018.
- A dataset and taxonomy for urban sound research. In ACM Int. Conf. on Multimedia (ACM MM), pp. 1041–1044, 2014.
- webmushra—a comprehensive framework for web-based listening tests. Journal of Open Research Software, 6(1), 2018.
- B Series. Method for the subjective assessment of intermediate quality level of audio systems. International Telecommunication Union Radiocommunication Assembly, 2014.
- Bit prioritization in variational autoencoders via progressive coding. In International Conference on Machine Learning (ICML), pp. 20141–20155, 2022.
- Deep unsupervised learning using nonequilibrium thermodynamics. In Proc. International Conference on Machine Learning (ICML), pp. 2256–2265. PMLR, 2015.
- Ladder variational autoencoders. In Proc. Advances in Neural Information Processing Systems (NeurIPS), pp. 3738–3746, 2016.
- Continuous relaxation training of discrete latent variable image models. In Beysian DeepLearning workshop, NIPS, 2017.
- Denoising diffusion implicit models. In Proc. International Conference on Learning Representation (ICLR), 2020.
- Preventing oversmoothing in VAE via generalized variance parameterization. Neurocomputing, 509:137–156, 2022a.
- SQ-VAE: Variational bayes on discrete representation with self-annealed stochastic quantization. In Proc. International Conference on Machine Learning (ICML), 2022b.
- Lossy image compression with compressive autoencoders. In Proc. International Conference on Learning Representation (ICLR), 2017.
- Variable rate image compression with recurrent neural networks. In Proc. International Conference on Learning Representation (ICLR), 2016.
- Nvae: A deep hierarchical variational autoencoder. In Proc. Advances in Neural Information Processing Systems (NeurIPS), volume 33, pp. 19667–19679, 2020.
- Pixel recurrent neural networks. In Proc. International Conference on Machine Learning (ICML), pp. 1747–1756, 2016.
- Neural discrete representation learning. In Proc. Advances in Neural Information Processing Systems (NeurIPS), pp. 6306–6315, 2017.
- Neural data-dependent transform for learned image compression. In Proc. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 17379–17388, 2022.
- Image quality assessment: from error visibility to structural similarity. IEEE transactions on image processing, 13(4):600–612, 2004.
- Hierarchical quantized autoencoders. arXiv preprint arXiv:2002.08111, 2020.
- Multi-scale residual convolutional encoder decoder with bidirectional long short-term memory for single channel speech enhancement. In Proc. European Signal Process. Conf. (EUSIPCO), pp. 431–435, 2021.
- Diffsound: Discrete diffusion model for text-to-sound generation. arXiv preprint arXiv:2207.09983, 2022.
- Locally hierarchical auto-regressive modeling for image generation. In Proc. Advances in Neural Information Processing Systems (NeurIPS), volume 35, pp. 16360–16372, 2022.
- Vector-quantized image modeling with improved VQGAN. In Proc. International Conference on Learning Representation (ICLR), 2022.
- SoundStream: An end-to-end neural audio codec. IEEE Trans. Audio, Speech, Lang. Process., 30:495–507, 2021.
- The unreasonable effectiveness of deep features as a perceptual metric. In Proc. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 586–595, 2018.
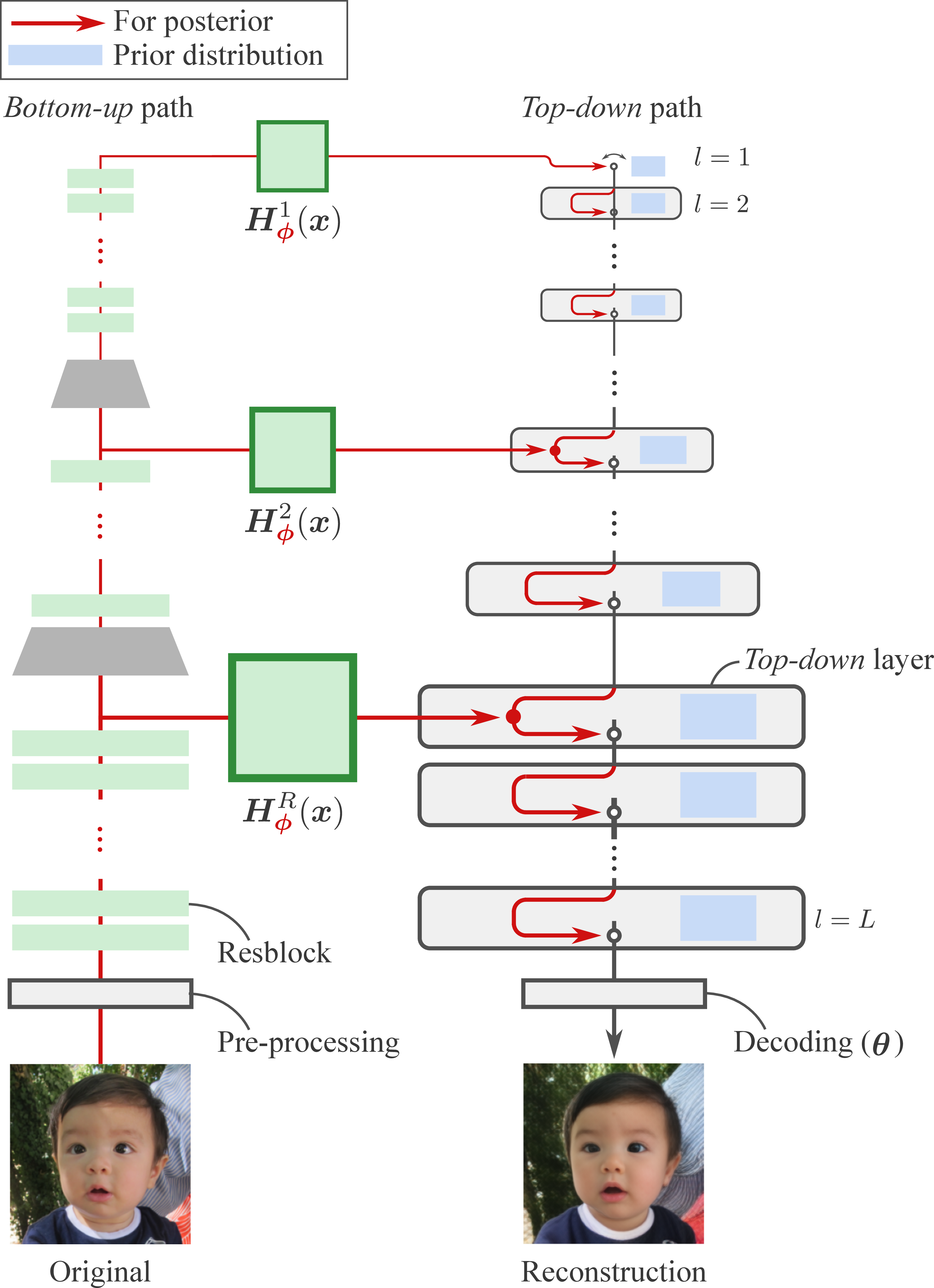
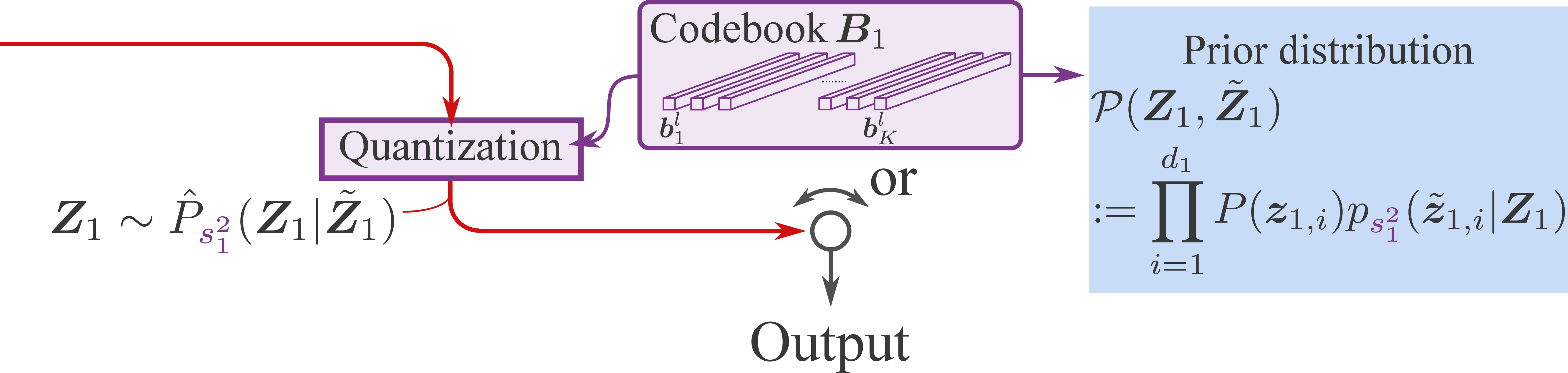
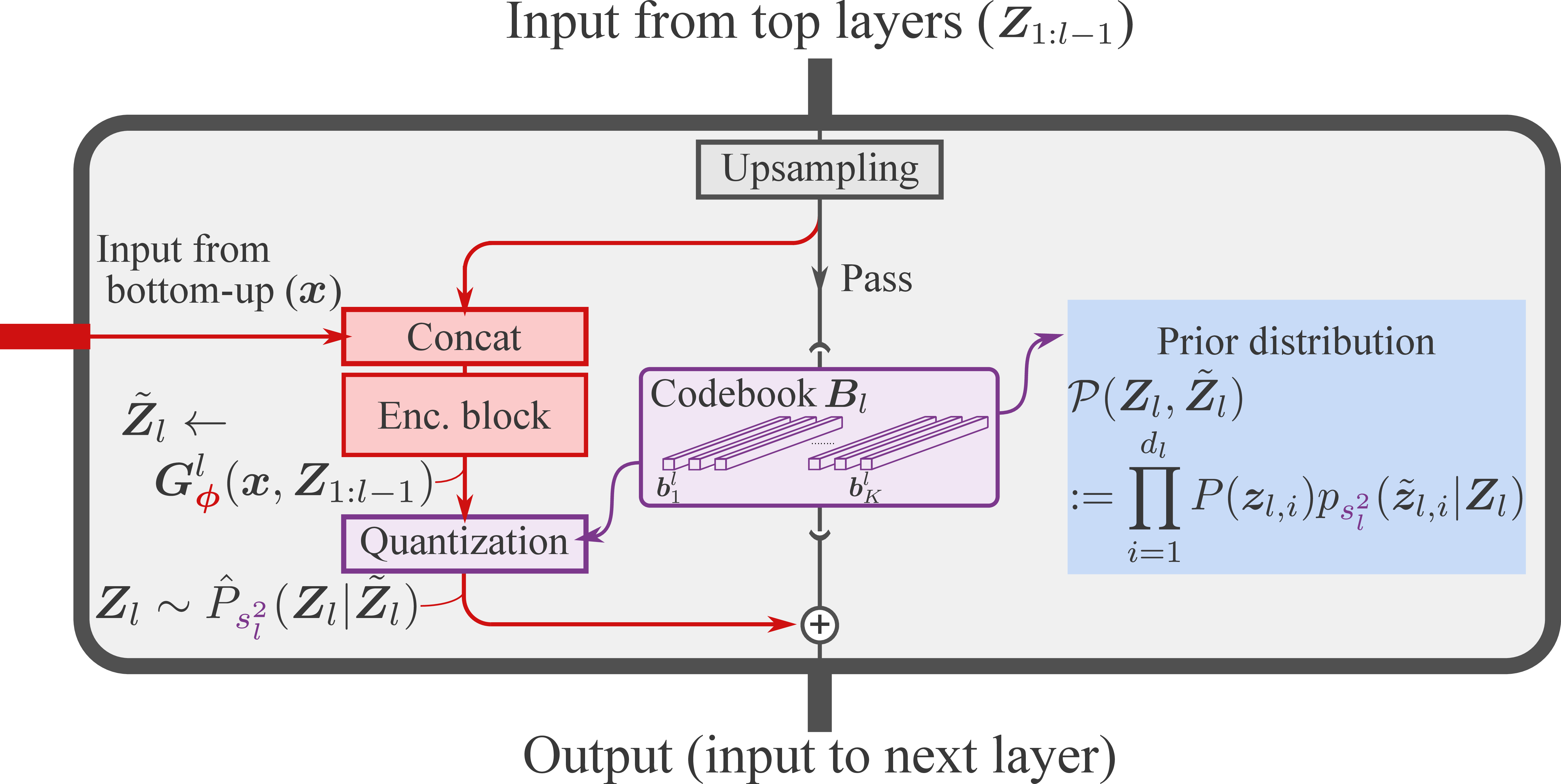
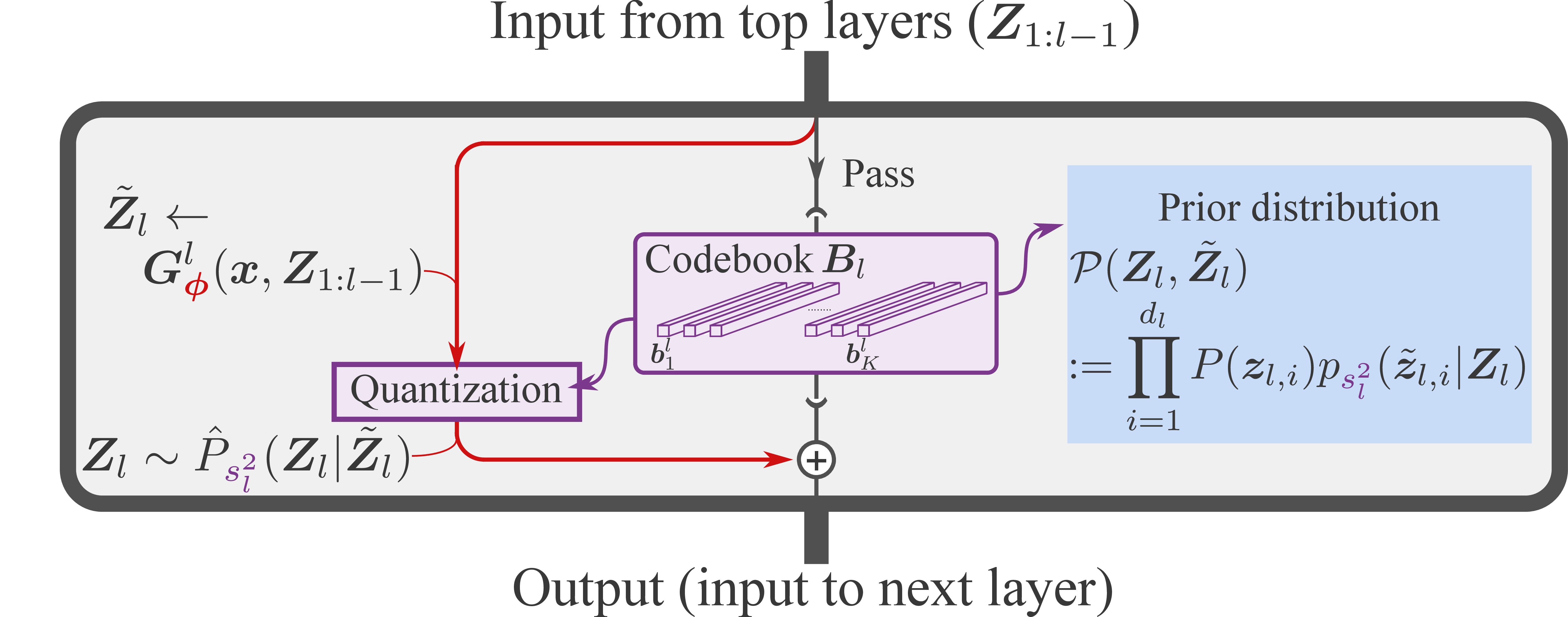
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

