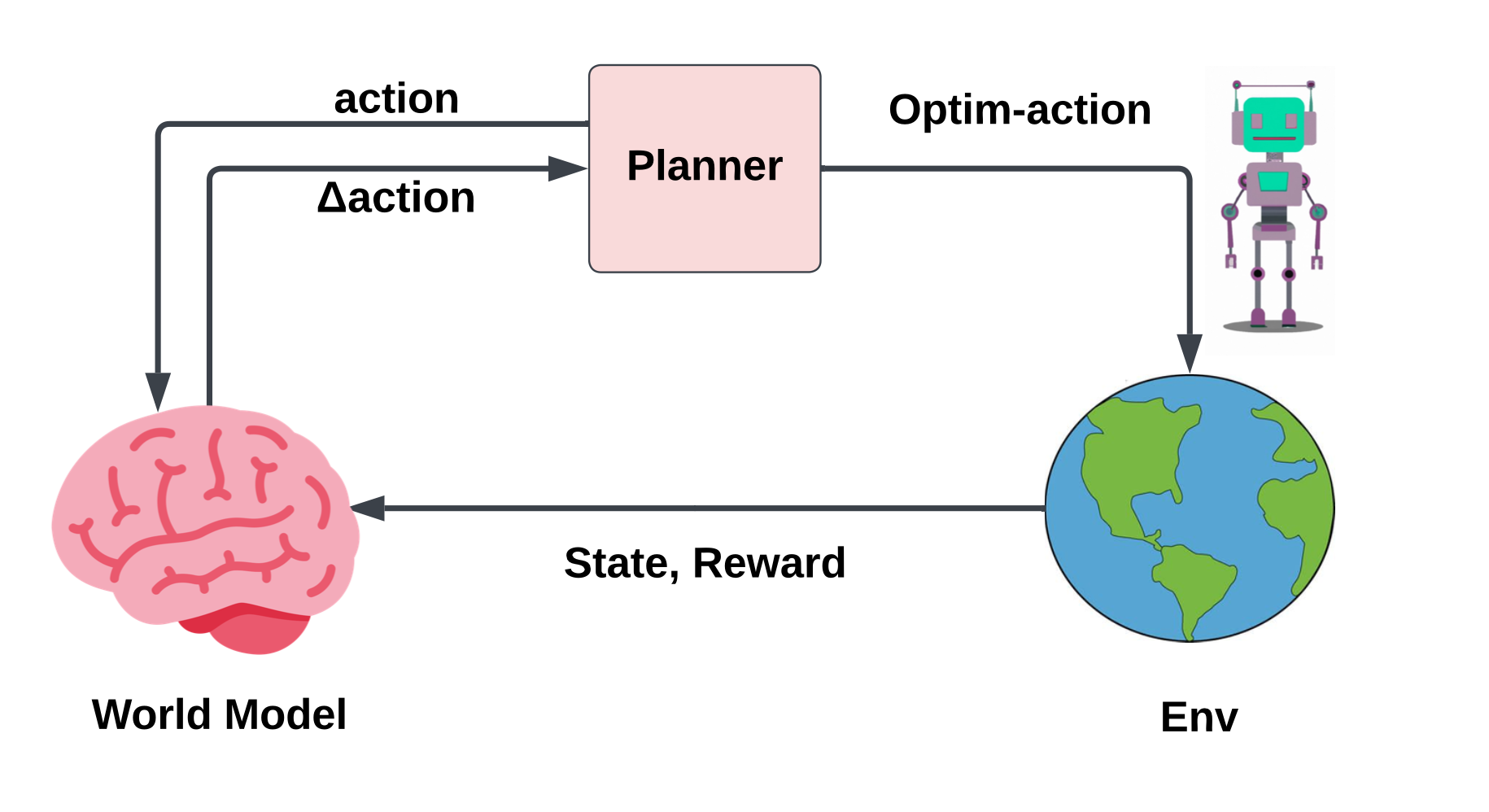
Gradient-based Planning with World Models
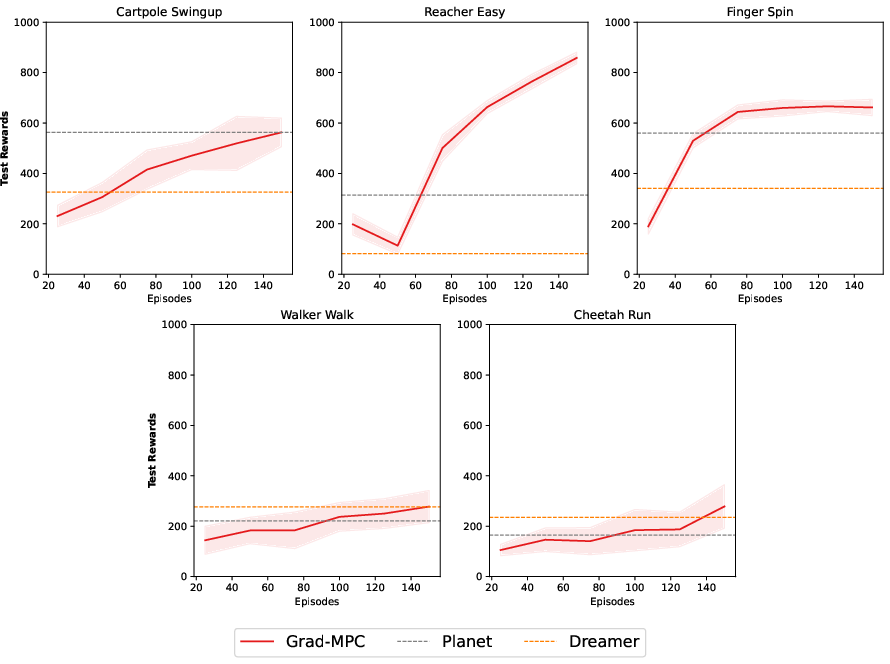
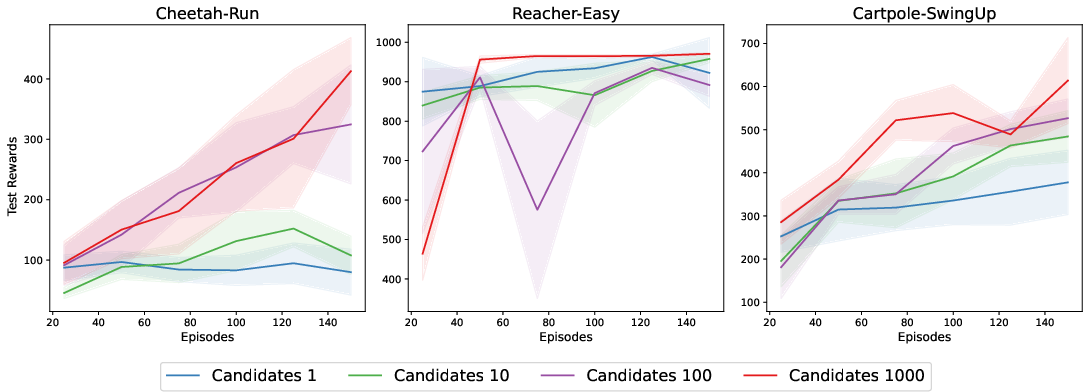
Abstract: The enduring challenge in the field of artificial intelligence has been the control of systems to achieve desired behaviours. While for systems governed by straightforward dynamics equations, methods like Linear Quadratic Regulation (LQR) have historically proven highly effective, most real-world tasks, which require a general problem-solver, demand world models with dynamics that cannot be easily described by simple equations. Consequently, these models must be learned from data using neural networks. Most model predictive control (MPC) algorithms designed for visual world models have traditionally explored gradient-free population-based optimisation methods, such as Cross Entropy and Model Predictive Path Integral (MPPI) for planning. However, we present an exploration of a gradient-based alternative that fully leverages the differentiability of the world model. In our study, we conduct a comparative analysis between our method and other MPC-based alternatives, as well as policy-based algorithms. In a sample-efficient setting, our method achieves on par or superior performance compared to the alternative approaches in most tasks. Additionally, we introduce a hybrid model that combines policy networks and gradient-based MPC, which outperforms pure policy based methods thereby holding promise for Gradient-based planning with world models in complex real-world tasks.
- A. Argenson and G. Dulac-Arnold. Model-based offline planning. (arXiv:2008.05556), Mar. 2021. URL http://arxiv.org/abs/2008.05556. arXiv:2008.05556 [cs, eess, stat].
- K. Arulkumaran. Planet pytorch. https://github.com/Kaixhin/PlaNet/, 2021.
- Vicreg: Variance-invariance-covariance regularization for self-supervised learning. arXiv preprint arXiv:2105.04906, 2021.
- The arcade learning environment: An evaluation platform for general agents. Journal of Artificial Intelligence Research, 47:253–279, jun 2013. doi: 10.1613/jair.3912. URL https://doi.org/10.1613%2Fjair.3912.
- Model-predictive control via cross-entropy and gradient-based optimization. In Learning for Dynamics and Control, pages 277–286. PMLR, 2020.
- Adaptive linear quadratic control using policy iteration. In Proceedings of 1994 American Control Conference-ACC’94, volume 3, pages 3475–3479. IEEE, 1994.
- Transdreamer: Reinforcement learning with transformer world models, 2022.
- Learning phrase representations using rnn encoder-decoder for statistical machine translation. arXiv preprint arXiv:1406.1078, 2014.
- Deep reinforcement learning in a handful of trials using probabilistic dynamics models. Advances in neural information processing systems, 31, 2018.
- Generalization and regularization in dqn, 2020.
- Byol-explore: Exploration by bootstrapped prediction. Advances in neural information processing systems, 35:31855–31870, 2022.
- D. Ha and J. Schmidhuber. World models. arXiv preprint arXiv:1803.10122, 2018.
- Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. In International conference on machine learning, pages 1861–1870. PMLR, 2018.
- Dream to control: Learning behaviors by latent imagination. arXiv preprint arXiv:1912.01603, 2019a.
- Learning latent dynamics for planning from pixels. In International conference on machine learning, pages 2555–2565. PMLR, 2019b.
- Deep hierarchical planning from pixels. Advances in Neural Information Processing Systems, 35:26091–26104, 2022.
- Mastering diverse domains through world models. arXiv preprint arXiv:2301.04104, 2023.
- D. P. Kingma and J. Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014.
- D. P. Kingma and M. Welling. Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114, 2013.
- Curl: Contrastive unsupervised representations for reinforcement learning. In International Conference on Machine Learning, pages 5639–5650. PMLR, 2020.
- Y. LeCun. A path towards autonomous machine intelligence version 0.9. 2, 2022-06-27. Open Review, 62, 2022.
- Convolutional networks for images, speech, and time series. The handbook of brain theory and neural networks, 3361(10):1995, 1995.
- Transformers are sample efficient world models. arXiv preprint arXiv:2209.00588, 2022.
- Playing atari with deep reinforcement learning. arXiv preprint arXiv:1312.5602, 2013.
- M. Morari and J. H. Lee. Model predictive control: past, present and future. Computers & chemical engineering, 23(4-5):667–682, 1999.
- Transformer-based world models are happy with 100k interactions. arXiv preprint arXiv:2303.07109, 2023.
- R. Y. Rubinstein. Optimization of computer simulation models with rare events. European Journal of Operational Research, 99(1):89–112, 1997.
- Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347, 2017.
- Data-efficient reinforcement learning with momentum predictive representations. CoRR, abs/2007.05929, 2020. URL https://arxiv.org/abs/2007.05929.
- Masked world models for visual control. In Conference on Robot Learning, pages 1332–1344. PMLR, 2023.
- Joint embedding predictive architectures focus on slow features. arXiv preprint arXiv:2211.10831, 2022.
- Observational overfitting in reinforcement learning, 2019.
- R. S. Sutton. Dyna, an integrated architecture for learning, planning, and reacting. SIGART Bull., 2:160–163, 1990. URL https://api.semanticscholar.org/CorpusID:207162288.
- Deepmind control suite, 2018.
- Y. Urakami. Dreamer pytorch. https://github.com/yusukeurakami/dreamer-pytorch, 2022.
- Aggressive driving with model predictive path integral control. In 2016 IEEE International Conference on Robotics and Automation (ICRA), pages 1433–1440. IEEE, 2016.
- D. Yarats. Soft actor-critic (sac) implementation in pytorch. https://github.com/denisyarats/pytorch_sac, 2019.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

