On Early Detection of Hallucinations in Factual Question Answering
Abstract: While LLMs have taken great strides towards helping humans with a plethora of tasks, hallucinations remain a major impediment towards gaining user trust. The fluency and coherence of model generations even when hallucinating makes detection a difficult task. In this work, we explore if the artifacts associated with the model generations can provide hints that the generation will contain hallucinations. Specifically, we probe LLMs at 1) the inputs via Integrated Gradients based token attribution, 2) the outputs via the Softmax probabilities, and 3) the internal state via self-attention and fully-connected layer activations for signs of hallucinations on open-ended question answering tasks. Our results show that the distributions of these artifacts tend to differ between hallucinated and non-hallucinated generations. Building on this insight, we train binary classifiers that use these artifacts as input features to classify model generations into hallucinations and non-hallucinations. These hallucination classifiers achieve up to $0.80$ AUROC. We also show that tokens preceding a hallucination can already predict the subsequent hallucination even before it occurs.
- “Evaluating correctness and faithfulness of instruction-following models for question answering” In arXiv preprint arXiv:2307.16877, 2023
- “An important next step on our AI journey” Accessed: 2023-10-11, https://blog.google/technology/ai/bard-google-ai-search-updates/, 2023
- “The internal state of an llm knows when its lying” In arXiv preprint arXiv:2304.13734, 2023
- Jon Christian “Why Is Google Translate Spitting Out Sinister Religious Prophecies?” Accessed: 2023-08-16, https://www.vice.com/en/article/j5npeg/why-is-google-translate-spitting-out-sinister-religious-prophecies, 2018
- “Confirmed: the new Bing runs on OpenAI’s GPT-4” Accessed: 2023-10-11, https://blogs.bing.com/search/march_2023/Confirmed-the-new-Bing-runs-on-OpenAI%E2%80%99s-GPT-4, 2023
- “Detecting and Mitigating Hallucinations in Machine Translation: Model Internal Workings Alone Do Well, Sentence Similarity Even Better” In arXiv preprint arXiv:2212.08597, 2022
- “Towards a rigorous science of interpretable machine learning” In arXiv preprint arXiv:1702.08608, 2017
- “T-REx: A Large Scale Alignment of Natural Language with Knowledge Base Triples” In Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018) Miyazaki, Japan: European Language Resources Association (ELRA), 2018 URL: https://aclanthology.org/L18-1544
- “Towards Opening the Black Box of Neural Machine Translation: Source and Target Interpretations of the Transformer” In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing Abu Dhabi, United Arab Emirates: Association for Computational Linguistics, 2022, pp. 8756–8769 DOI: 10.18653/v1/2022.emnlp-main.599
- “Unsupervised quality estimation for neural machine translation” In Transactions of the Association for Computational Linguistics 8 MIT Press One Rogers Street, Cambridge, MA 02142-1209, USA journals-info …, 2020, pp. 539–555
- “Explaining explanations: An overview of interpretability of machine learning” In 2018 IEEE 5th International Conference on data science and advanced analytics (DSAA), 2018, pp. 80–89 IEEE
- Nuno M. Guerreiro, Elena Voita and André Martins “Looking for a Needle in a Haystack: A Comprehensive Study of Hallucinations in Neural Machine Translation” In Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics Dubrovnik, Croatia: Association for Computational Linguistics, 2023, pp. 1059–1075 URL: https://aclanthology.org/2023.eacl-main.75
- “A survey of methods for explaining black box models” In ACM computing surveys (CSUR) 51.5 ACM New York, NY, USA, 2018, pp. 1–42
- “Survey of hallucination in natural language generation” In ACM Computing Surveys 55.12 ACM New York, NY, 2023, pp. 1–38
- “TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension” In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) Vancouver, Canada: Association for Computational Linguistics, 2017, pp. 1601–1611 DOI: 10.18653/v1/P17-1147
- “Language models (mostly) know what they know” In arXiv preprint arXiv:2207.05221, 2022
- “Captum: A unified and generic model interpretability library for PyTorch”, 2020 arXiv:2009.07896 [cs.LG]
- “Retrieval-augmented generation for knowledge-intensive nlp tasks” In Advances in Neural Information Processing Systems 33, 2020, pp. 9459–9474
- “Holistic evaluation of language models” In arXiv preprint arXiv:2211.09110, 2022
- Stephanie Lin, Jacob Hilton and Owain Evans “Truthfulqa: Measuring how models mimic human falsehoods” In arXiv preprint arXiv:2109.07958, 2021
- Zachary C Lipton “The mythos of model interpretability: In machine learning, the concept of interpretability is both important and slippery.” In Queue 16.3 ACM New York, NY, USA, 2018, pp. 31–57
- Scott M Lundberg and Su-In Lee “A unified approach to interpreting model predictions” In Advances in neural information processing systems 30, 2017
- “Locating and editing factual associations in GPT” In Advances in Neural Information Processing Systems 35, 2022, pp. 17359–17372
- “Layer-wise relevance propagation: an overview” In Explainable AI: interpreting, explaining and visualizing deep learning Springer, 2019, pp. 193–209
- “Need a Last Minute Mother’s Day Gift? AI Is Here to Help.” Accessed: 2023-10-11, https://about.you.com/need-a-last-minute-mothers-day-gift-ai-is-here-to-help-d363b17e76b4/, 2023
- “Training language models to follow instructions with human feedback” In Advances in Neural Information Processing Systems 35, 2022, pp. 27730–27744
- Artidoro Pagnoni, Vidhisha Balachandran and Yulia Tsvetkov “Understanding factuality in abstractive summarization with FRANK: A benchmark for factuality metrics” In arXiv preprint arXiv:2104.13346, 2021
- “Language Models as Knowledge Bases?” In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP) Hong Kong, China: Association for Computational Linguistics, 2019, pp. 2463–2473 DOI: 10.18653/v1/D19-1250
- “Amazon SageMaker Debugger: A system for real-time insights into machine learning model training” In MLSys 2021, 2021 URL: https://www.amazon.science/publications/amazon-sagemaker-debugger-a-system-for-real-time-insights-into-machine-learning-model-training
- “Open-domain conversational agents: Current progress, open problems, and future directions” In arXiv preprint arXiv:2006.12442, 2020
- Mukund Sundararajan, Ankur Taly and Qiqi Yan “Axiomatic attribution for deep networks” In International conference on machine learning, 2017, pp. 3319–3328 PMLR
- “Alpaca: A strong, replicable instruction-following model” In Stanford Center for Research on Foundation Models. https://crfm. stanford. edu/2023/03/13/alpaca. html 3.6, 2023, pp. 7
- “Welcome to the era of chatgpt et al. the prospects of large language models” In Business & Information Systems Engineering 65.2 Springer, 2023, pp. 95–101
- Elena Voita, Rico Sennrich and Ivan Titov “Analyzing the Source and Target Contributions to Predictions in Neural Machine Translation” In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers) Online: Association for Computational Linguistics, 2021, pp. 1126–1140 DOI: 10.18653/v1/2021.acl-long.91
- “On the lack of robust interpretability of neural text classifiers” In arXiv preprint arXiv:2106.04631, 2021
- “Ist-unbabel 2021 submission for the quality estimation shared task” In Proceedings of the Sixth Conference on Machine Translation, 2021, pp. 961–972
- “How language model hallucinations can snowball” In arXiv preprint arXiv:2305.13534, 2023
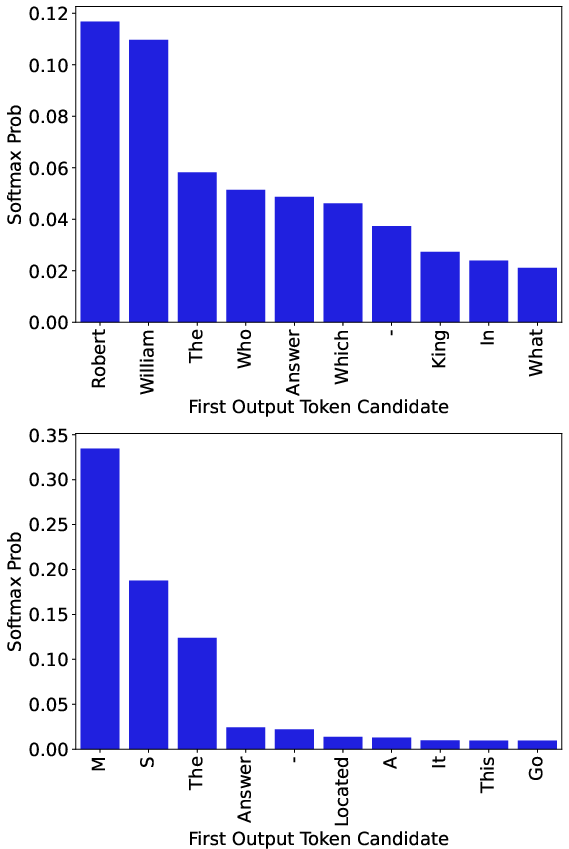
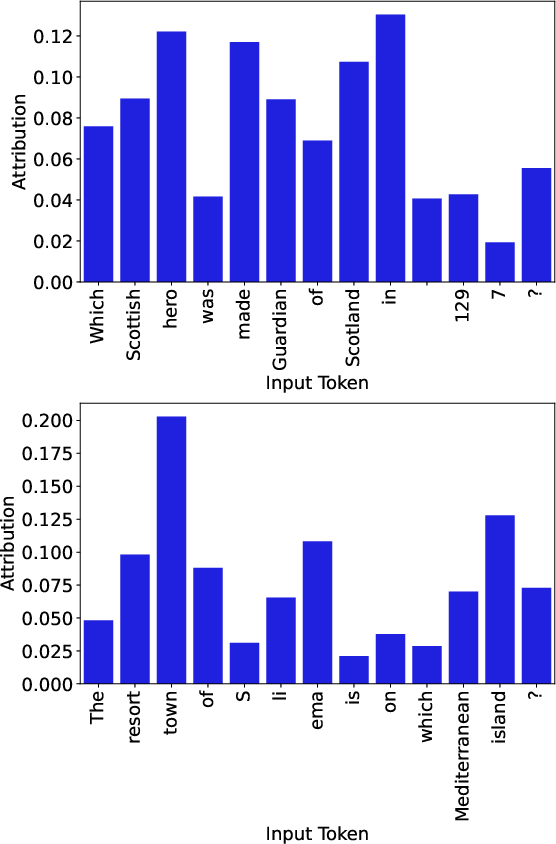
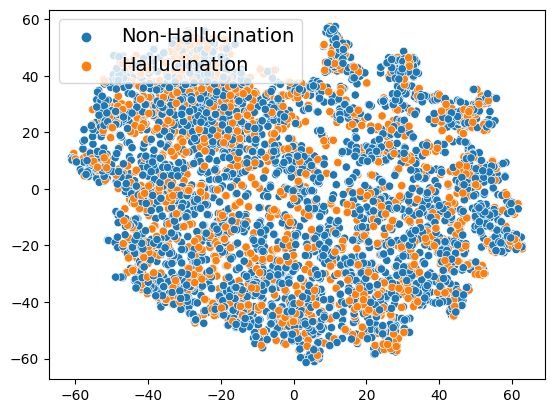
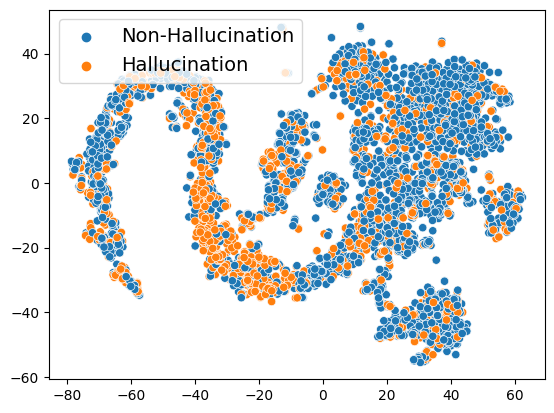
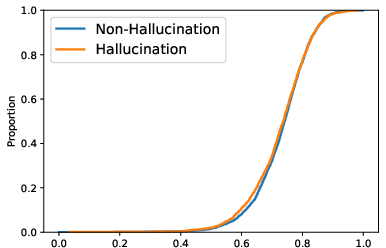
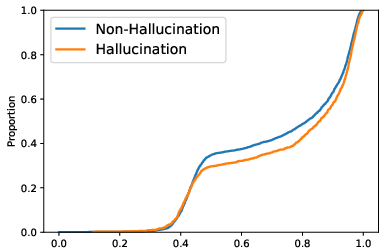
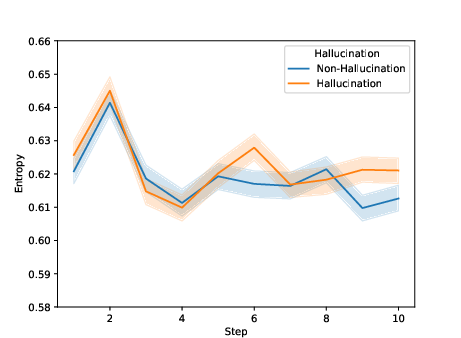
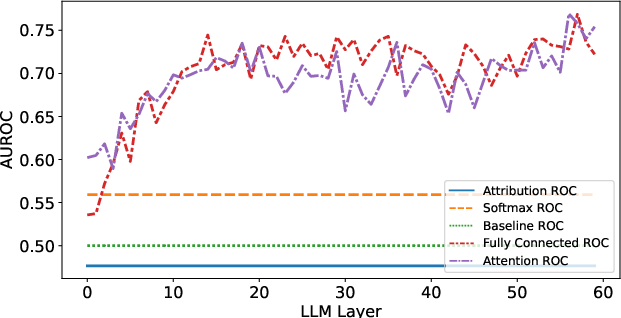
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.