Retrieval-Augmented Generation for Large Language Models: A Survey
Abstract: LLMs showcase impressive capabilities but encounter challenges like hallucination, outdated knowledge, and non-transparent, untraceable reasoning processes. Retrieval-Augmented Generation (RAG) has emerged as a promising solution by incorporating knowledge from external databases. This enhances the accuracy and credibility of the generation, particularly for knowledge-intensive tasks, and allows for continuous knowledge updates and integration of domain-specific information. RAG synergistically merges LLMs' intrinsic knowledge with the vast, dynamic repositories of external databases. This comprehensive review paper offers a detailed examination of the progression of RAG paradigms, encompassing the Naive RAG, the Advanced RAG, and the Modular RAG. It meticulously scrutinizes the tripartite foundation of RAG frameworks, which includes the retrieval, the generation and the augmentation techniques. The paper highlights the state-of-the-art technologies embedded in each of these critical components, providing a profound understanding of the advancements in RAG systems. Furthermore, this paper introduces up-to-date evaluation framework and benchmark. At the end, this article delineates the challenges currently faced and points out prospective avenues for research and development.
- Neuro-symbolic language modeling with automaton-augmented retrieval. In International Conference on Machine Learning, pages 468–485. PMLR, 2022.
- Lingua: Addressing scenarios for live interpretation and automatic dubbing. In Janice Campbell, Stephen Larocca, Jay Marciano, Konstantin Savenkov, and Alex Yanishevsky, editors, Proceedings of the 15th Biennial Conference of the Association for Machine Translation in the Americas (Volume 2: Users and Providers Track and Government Track), pages 202–209, Orlando, USA, September 2022. Association for Machine Translation in the Americas.
- AngIE. Angle-optimized text embeddings. https://github.com/SeanLee97/AnglE, 2023.
- Gar-meets-rag paradigm for zero-shot information retrieval. arXiv preprint arXiv:2310.20158, 2023.
- Retrieval-based language models and applications. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 6: Tutorial Abstracts), pages 41–46, 2023.
- Self-rag: Learning to retrieve, generate, and critique through self-reflection. arXiv preprint arXiv:2310.11511, 2023.
- BAAI. Flagembedding. https://github.com/FlagOpen/FlagEmbedding, 2023.
- Knowledge-augmented language model verification. arXiv preprint arXiv:2310.12836, 2023.
- Constitutional ai: Harmlessness from ai feedback. arXiv preprint arXiv:2212.08073, 2022.
- A multitask, multilingual, multimodal evaluation of chatgpt on reasoning, hallucination, and interactivity. arXiv preprint arXiv:2302.04023, 2023.
- Optimizing retrieval-augmented reader models via token elimination. arXiv preprint arXiv:2310.13682, 2023.
- Piqa: Reasoning about physical commonsense in natural language. In Proceedings of the AAAI conference on artificial intelligence, volume 34, pages 7432–7439, 2020.
- Vladimir Blagojevi. Enhancing rag pipelines in haystack: Introducing diversityranker and lostinthemiddleranker. https://towardsdatascience.com/enhancing-rag-pipelines-in-haystack-45f14e2bc9f5, 2023.
- Improving language models by retrieving from trillions of tokens. In International conference on machine learning, pages 2206–2240. PMLR, 2022.
- Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020.
- Neural machine translation with monolingual translation memory. arXiv preprint arXiv:2105.11269, 2021.
- Using external off-policy speech-to-text mappings in contextual end-to-end automated speech recognition. arXiv preprint arXiv:2301.02736, 2023.
- Open-domain question answering. In Proceedings of the 58th annual meeting of the association for computational linguistics: tutorial abstracts, pages 34–37, 2020.
- Walking down the memory maze: Beyond context limit through interactive reading. arXiv preprint arXiv:2310.05029, 2023.
- Benchmarking large language models in retrieval-augmented generation. arXiv preprint arXiv:2309.01431, 2023.
- Neural machine translation with contrastive translation memories. arXiv preprint arXiv:2212.03140, 2022.
- Uprise: Universal prompt retrieval for improving zero-shot evaluation. arXiv preprint arXiv:2303.08518, 2023.
- Lift yourself up: Retrieval-augmented text generation with self memory. arXiv preprint arXiv:2305.02437, 2023.
- Boolq: Exploring the surprising difficulty of natural yes/no questions. arXiv preprint arXiv:1905.10044, 2019.
- Cohere. Say goodbye to irrelevant search results: Cohere rerank is here. https://txt.cohere.com/rerank/, 2023.
- Promptagator: Few-shot dense retrieval from 8 examples. arXiv preprint arXiv:2209.11755, 2022.
- Ragas: Automated evaluation of retrieval augmented generation. arXiv preprint arXiv:2309.15217, 2023.
- Retrieval-generation synergy augmented large language models. arXiv preprint arXiv:2310.05149, 2023.
- Trends in integration of knowledge and large language models: A survey and taxonomy of methods, benchmarks, and applications. arXiv preprint arXiv:2311.05876, 2023.
- Precise zero-shot dense retrieval without relevance labels. arXiv preprint arXiv:2212.10496, 2022.
- Robust retrieval augmented generation for zero-shot slot filling. arXiv preprint arXiv:2108.13934, 2021.
- Google. Gemini: A family of highly capable multimodal models. https://goo.gle/GeminiPaper, 2023.
- Measuring massive multitask language understanding. arXiv preprint arXiv:2009.03300, 2020.
- Few-shot learning with retrieval augmented language models. arXiv preprint arXiv:2208.03299, 2022.
- A survey of techniques for maximizing llm performance. https://community.openai.com/t/openai-dev-day-2023-breakout-sessions/505213#a-survey-of-techniques-for-maximizing-llm-performance-2, 2023.
- Llmlingua: Compressing prompts for accelerated inference of large language models. arXiv preprint arXiv:2310.05736, 2023.
- Active retrieval augmented generation. arXiv preprint arXiv:2305.06983, 2023.
- Large language models struggle to learn long-tail knowledge. In International Conference on Machine Learning, pages 15696–15707. PMLR, 2023.
- Knowledge graph-augmented language models for knowledge-grounded dialogue generation. arXiv preprint arXiv:2305.18846, 2023.
- Dense passage retrieval for open-domain question answering. arXiv preprint arXiv:2004.04906, 2020.
- Generalization through memorization: Nearest neighbor language models. arXiv preprint arXiv:1911.00172, 2019.
- Colbert: Efficient and effective passage search via contextualized late interaction over bert. In Proceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval, pages 39–48, 2020.
- Demonstrate-search-predict: Composing retrieval and language models for knowledge-intensive nlp. arXiv preprint arXiv:2212.14024, 2022.
- Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics, 7:453–466, 2019.
- Learning dense representations of phrases at scale. arXiv preprint arXiv:2012.12624, 2020.
- Best practices for llm evaluation of rag applications. https://www.databricks.com/blog/LLM-auto-eval-best-practices-RAG, 2023.
- Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in Neural Information Processing Systems, 33:9459–9474, 2020.
- Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. arXiv preprint arXiv:2301.12597, 2023.
- From classification to generation: Insights into crosslingual retrieval augmented icl. arXiv preprint arXiv:2311.06595, 2023.
- Chain of knowledge: A framework for grounding large language models with structured knowledge bases. arXiv preprint arXiv:2305.13269, 2023.
- Structure-aware language model pretraining improves dense retrieval on structured data. arXiv preprint arXiv:2305.19912, 2023.
- Ra-dit: Retrieval-augmented dual instruction tuning. arXiv preprint arXiv:2310.01352, 2023.
- Scatter: selective context attentional scene text recognizer. In proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11962–11972, 2020.
- Lost in the middle: How language models use long contexts. arXiv preprint arXiv:2307.03172, 2023.
- Jerry Liu. Building production-ready rag applications. https://www.ai.engineer/summit/schedule/building-production-ready-rag-applications, 2023.
- Augmented large language models with parametric knowledge guiding. arXiv preprint arXiv:2305.04757, 2023.
- Query rewriting for retrieval-augmented large language models. arXiv preprint arXiv:2305.14283, 2023.
- Large language model is not a good few-shot information extractor, but a good reranker for hard samples! ArXiv, abs/2303.08559, 2023.
- Ret-llm: Towards a general read-write memory for large language models. arXiv preprint arXiv:2305.14322, 2023.
- Webgpt: Browser-assisted question-answering with human feedback. arXiv preprint arXiv:2112.09332, 2021.
- Retrieval-based prompt selection for code-related few-shot learning. In 2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE), pages 2450–2462, 2023.
- OpenAI. Gpt-4 technical report. https://cdn.openai.com/papers/gpt-4.pdf, 2023.
- Language models as knowledge bases? arXiv preprint arXiv:1909.01066, 2019.
- Exploring the limits of transfer learning with a unified text-to-text transformer. The Journal of Machine Learning Research, 21(1):5485–5551, 2020.
- Sequence level training with recurrent neural networks. arXiv preprint arXiv:1511.06732, 2015.
- Coqa: A conversational question answering challenge. Transactions of the Association for Computational Linguistics, 7:249–266, 2019.
- The probabilistic relevance framework: Bm25 and beyond. Foundations and Trends® in Information Retrieval, 3(4):333–389, 2009.
- Ares: An automated evaluation framework for retrieval-augmented generation systems. arXiv preprint arXiv:2311.09476, 2023.
- Toolformer: Language models can teach themselves to use tools. arXiv preprint arXiv:2302.04761, 2023.
- Simple entity-centric questions challenge dense retrievers. arXiv preprint arXiv:2109.08535, 2021.
- Enhancing retrieval-augmented large language models with iterative retrieval-generation synergy. arXiv preprint arXiv:2305.15294, 2023.
- Replug: Retrieval-augmented black-box language models. arXiv preprint arXiv:2301.12652, 2023.
- Retrieval augmentation reduces hallucination in conversation. arXiv preprint arXiv:2104.07567, 2021.
- Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. arXiv preprint arXiv:2206.04615, 2022.
- Recitation-augmented language models. arXiv preprint arXiv:2210.01296, 2022.
- Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288, 2023.
- Interleaving retrieval with chain-of-thought reasoning for knowledge-intensive multi-step questions. arXiv preprint arXiv:2212.10509, 2022.
- Attention is all you need. Advances in neural information processing systems, 30, 2017.
- Open-set recognition: A good closed-set classifier is all you need? arXiv preprint arXiv:2110.06207, 2021.
- VoyageAI. Voyage’s embedding models. https://docs.voyageai.com/embeddings/, 2023.
- Superglue: A stickier benchmark for general-purpose language understanding systems. Advances in neural information processing systems, 32, 2019.
- Training data is more valuable than you think: A simple and effective method by retrieving from training data. arXiv preprint arXiv:2203.08773, 2022.
- Training data is more valuable than you think: A simple and effective method by retrieving from training data. In Smaranda Muresan, Preslav Nakov, and Aline Villavicencio, editors, Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 3170–3179, Dublin, Ireland, May 2022. Association for Computational Linguistics.
- Shall we pretrain autoregressive language models with retrieval? a comprehensive study. arXiv preprint arXiv:2304.06762, 2023.
- Query2doc: Query expansion with large language models. arXiv preprint arXiv:2303.07678, 2023.
- Knowledgpt: Enhancing large language models with retrieval and storage access on knowledge bases. arXiv preprint arXiv:2308.11761, 2023.
- Self-knowledge guided retrieval augmentation for large language models. arXiv preprint arXiv:2310.05002, 2023.
- Chain-of-thought prompting elicits reasoning in large language models. Advances in Neural Information Processing Systems, 35:24824–24837, 2022.
- Graph based translation memory for neural machine translation. In Proceedings of the AAAI conference on artificial intelligence, volume 33, pages 7297–7304, 2019.
- Recomp: Improving retrieval-augmented lms with compression and selective augmentation. arXiv preprint arXiv:2310.04408, 2023.
- Retrieval meets long context large language models. arXiv preprint arXiv:2310.03025, 2023.
- Vid2seq: Large-scale pretraining of a visual language model for dense video captioning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10714–10726, 2023.
- Prca: Fitting black-box large language models for retrieval question answering via pluggable reward-driven contextual adapter. arXiv preprint arXiv:2310.18347, 2023.
- Auto-gpt for online decision making: Benchmarks and additional opinions. arXiv preprint arXiv:2306.02224, 2023.
- Llm lies: Hallucinations are not bugs, but features as adversarial examples. arXiv preprint arXiv:2310.01469, 2023.
- Retrieval-augmented multimodal language modeling. arXiv preprint arXiv:2211.12561, 2022.
- Coreferential reasoning learning for language representation. arXiv preprint arXiv:2004.06870, 2020.
- Making retrieval-augmented language models robust to irrelevant context. arXiv preprint arXiv:2310.01558, 2023.
- Generate rather than retrieve: Large language models are strong context generators. arXiv preprint arXiv:2209.10063, 2022.
- Chain-of-note: Enhancing robustness in retrieval-augmented language models. arXiv preprint arXiv:2311.09210, 2023.
- Augmentation-adapted retriever improves generalization of language models as generic plug-in. arXiv preprint arXiv:2305.17331, 2023.
- Ernie: Enhanced language representation with informative entities. arXiv preprint arXiv:1905.07129, 2019.
- Retrieve anything to augment large language models. arXiv preprint arXiv:2310.07554, 2023.
- Siren’s song in the ai ocean: A survey on hallucination in large language models. arXiv preprint arXiv:2309.01219, 2023.
- Jiawei Zhang. Graph-toolformer: To empower llms with graph reasoning ability via prompt augmented by chatgpt. arXiv preprint arXiv:2304.11116, 2023.
- Generating synthetic speech from spokenvocab for speech translation. arXiv preprint arXiv:2210.08174, 2022.
- Take a step back: Evoking reasoning via abstraction in large language models. arXiv preprint arXiv:2310.06117, 2023.
- Training language models with memory augmentation. arXiv preprint arXiv:2205.12674, 2022.
- Visualize before you write: Imagination-guided open-ended text generation. arXiv preprint arXiv:2210.03765, 2022.
- Large language models for information retrieval: A survey. arXiv preprint arXiv:2308.07107, 2023.
- Open-source large language models are strong zero-shot query likelihood models for document ranking. arXiv preprint arXiv:2310.13243, 2023.
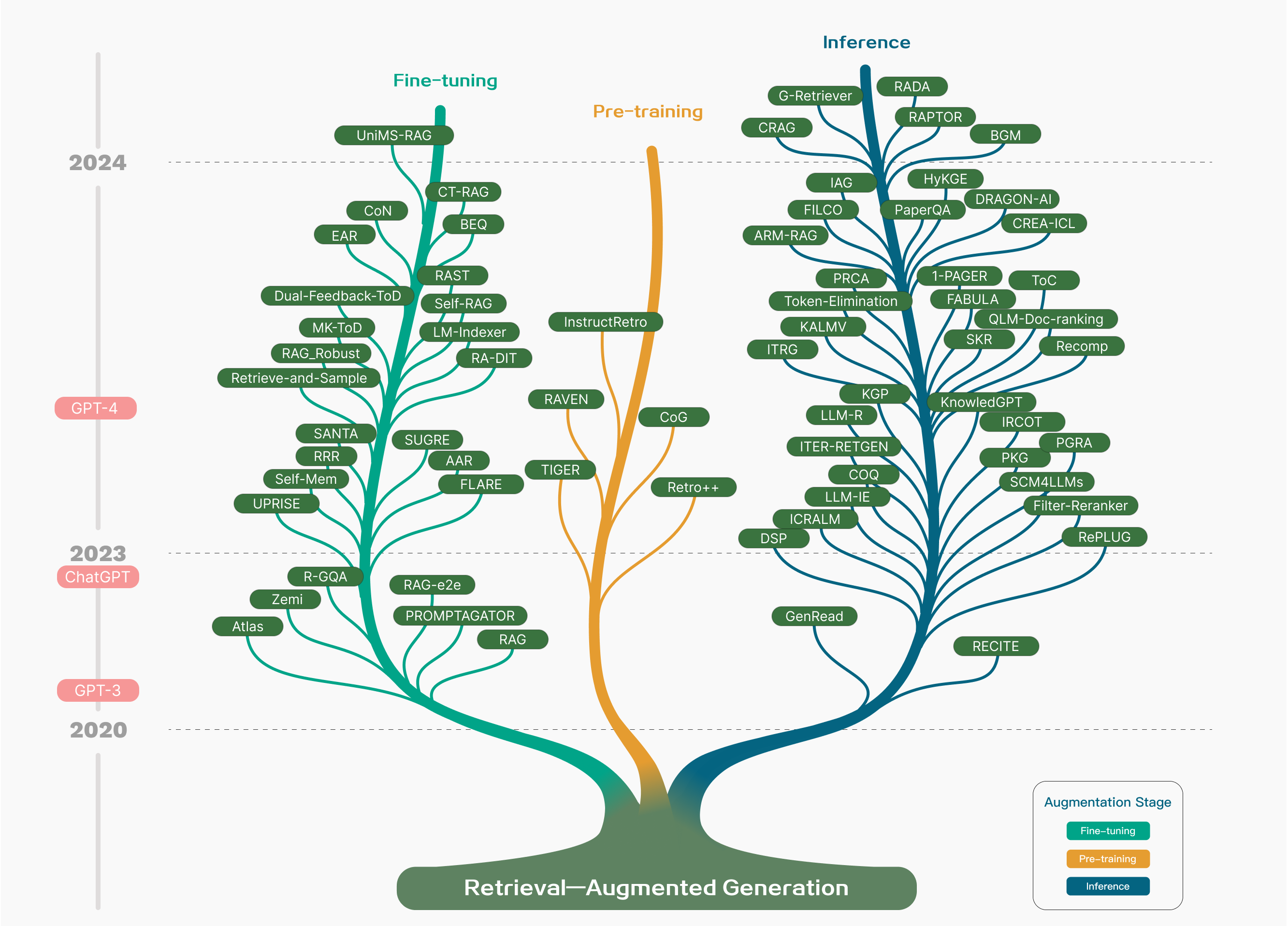
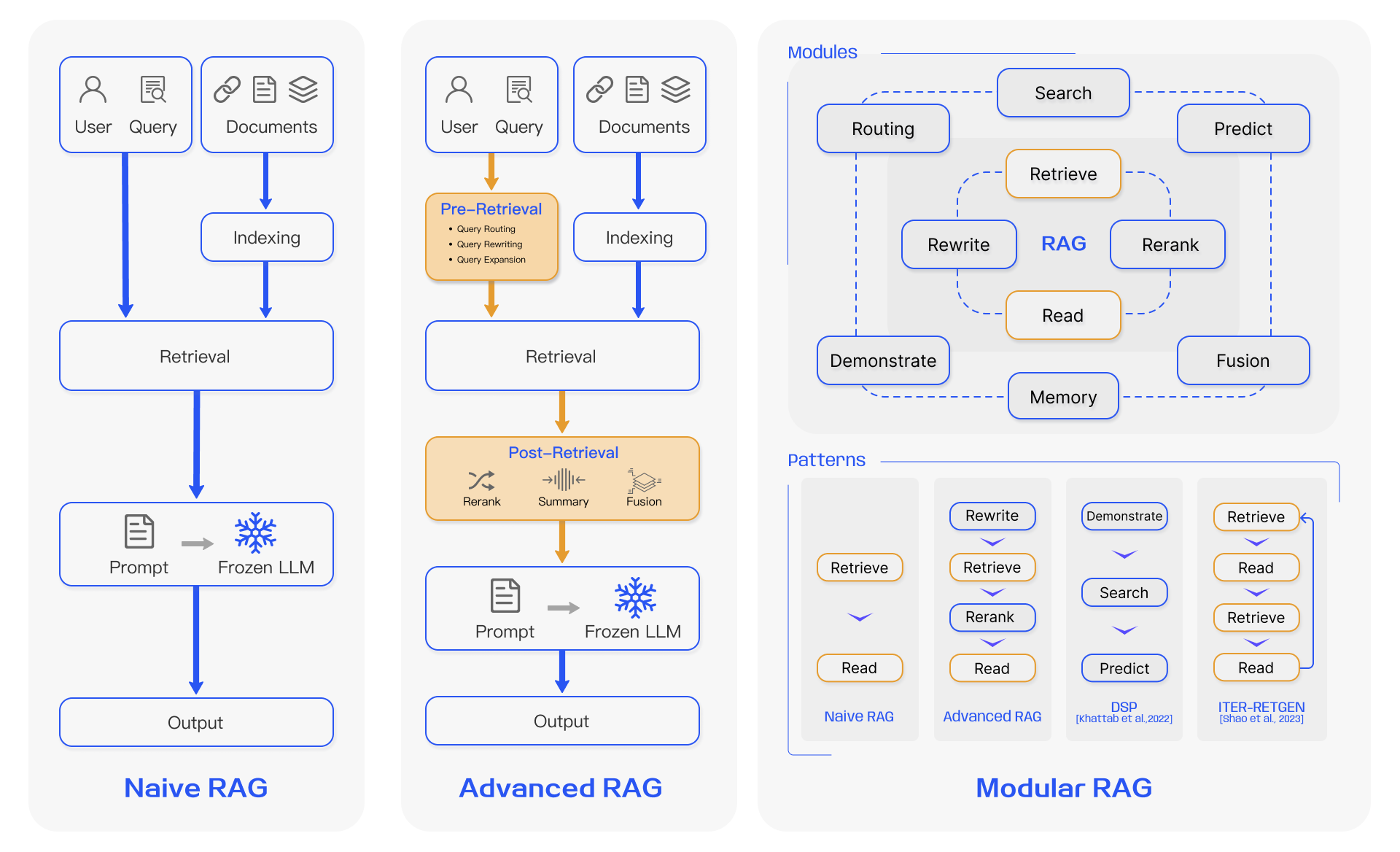
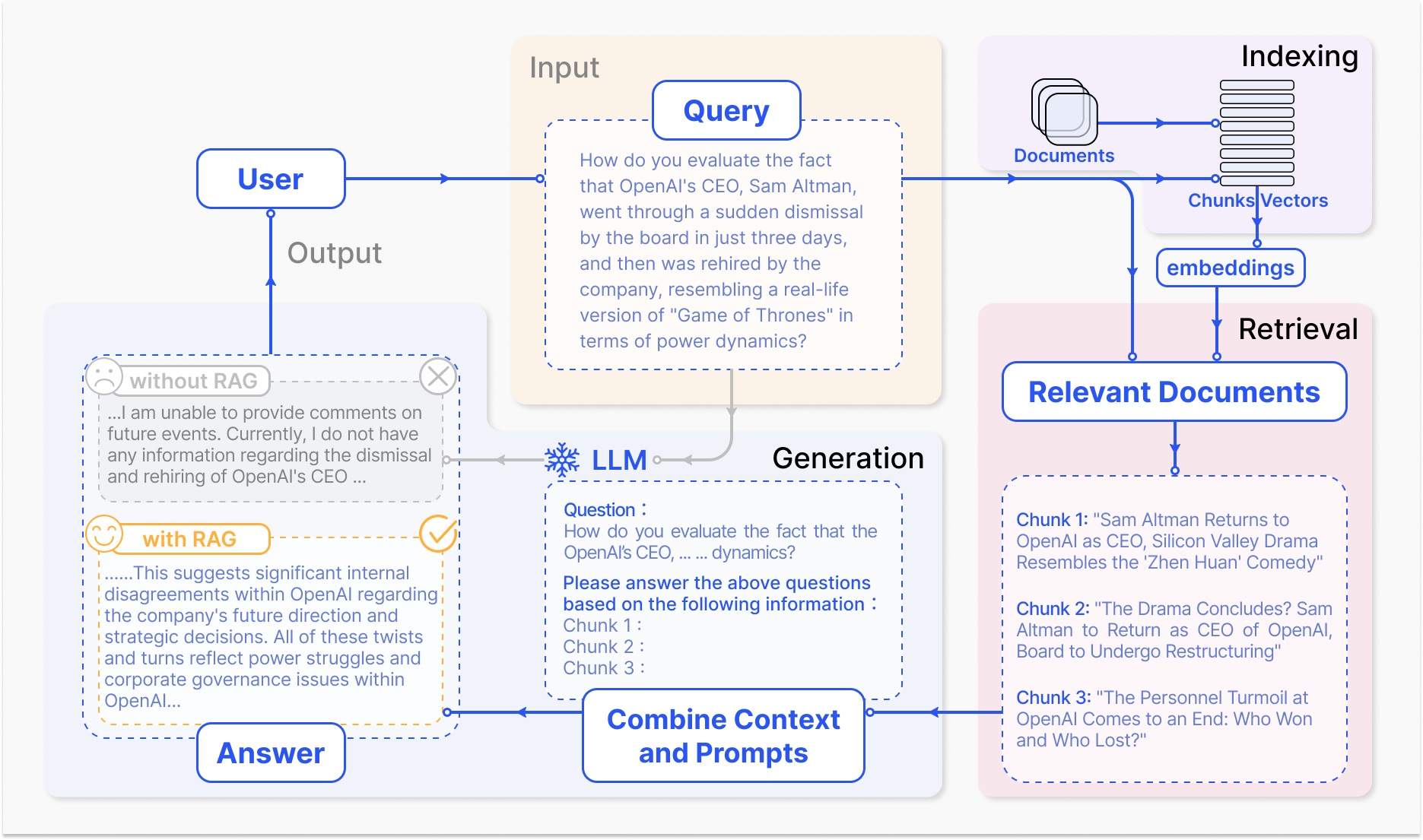
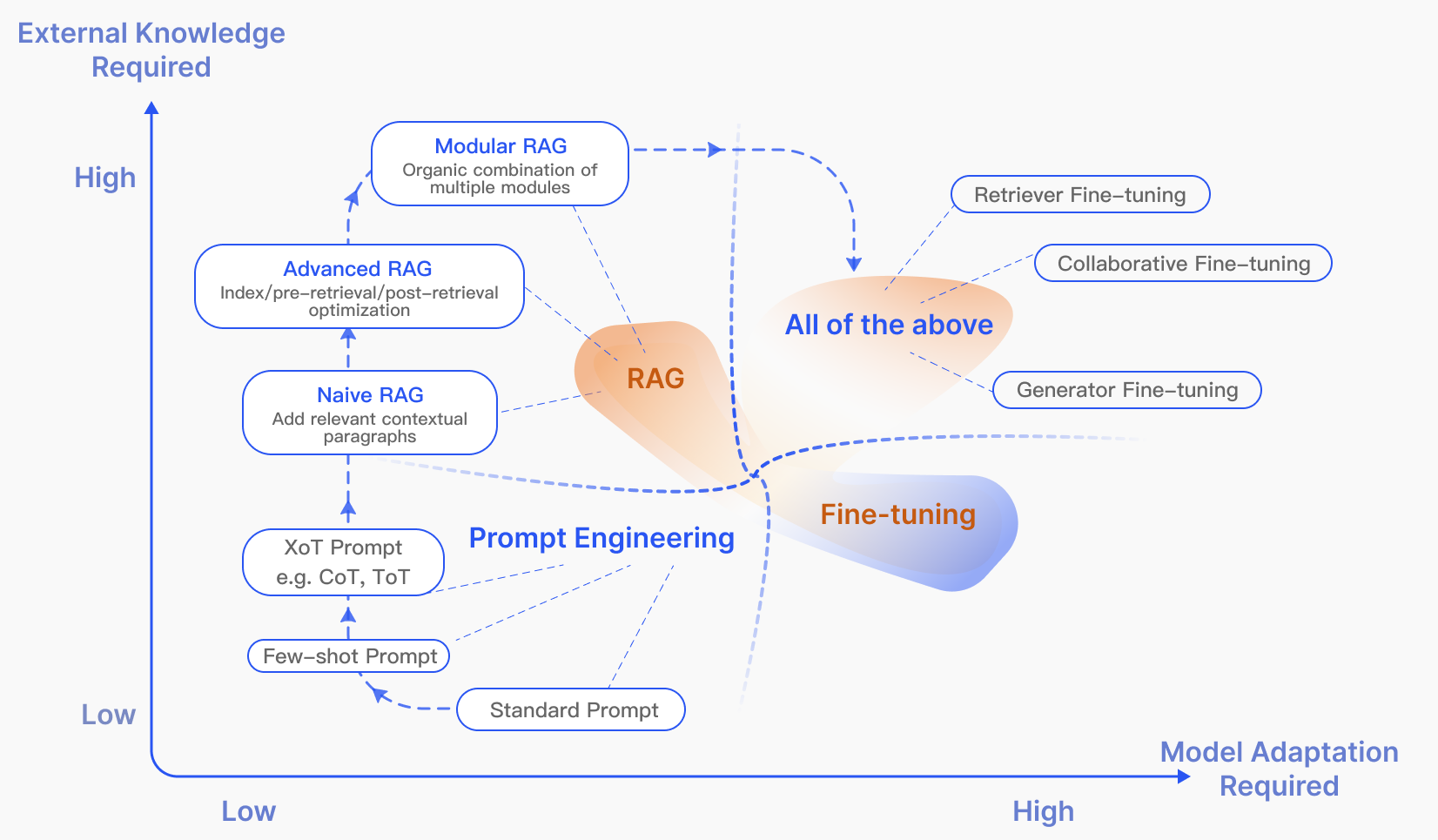
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.