- The paper demonstrates that Behavioral Cloning outperforms advanced offline RL and sequence modeling methods on unseen test environments.
- The paper establishes that increased training data diversity, rather than mere data volume, is critical for reducing the generalization gap.
- The paper reveals that current offline RL algorithms are overly conservative, prompting the need for new robust generalization mechanisms.
The Generalization Gap in Offline Reinforcement Learning
Introduction and Motivation
The paper "The Generalization Gap in Offline Reinforcement Learning" (2312.05742) investigates the persistent limitations of offline RL algorithms in their ability to generalize to novel environments, focusing on rigorous, cross-environment generalization diagnostics. Offline RL is of significant practical relevance—especially in domains like healthcare, robotics, and autonomous systems—where online data collection is costly or risky. However, most prior offline RL studies use singleton environments and evaluate only within-distribution generalization, thereby limiting understanding of real-world deployment capabilities.
To address this gap, the authors introduce new benchmarks specifically constructed to evaluate environment-level generalization from offline data, utilizing two diverse domains: (i) Procgen, a suite of procedurally-generated 2D games with distinct dynamics, layouts, and reward structures; and (ii) WebShop, a language-based e-commerce navigation environment requiring instruction following. These benchmarks provide a foundation for principled, scalable, and reproducible evaluation of generalization in offline RL.


Figure 1: Representative input examples from the Procgen and WebShop benchmarks, illustrating the diversity of train/test environments and instructions.
Experimental Setup and Evaluation Protocol
The study collects and curates offline datasets varying in both scale and expertise, encompassing expert-only, mixed expert-suboptimal, and suboptimal-only data regimes. Procgen datasets span 16 games, with systematic splits between training (seen) and testing (unseen) levels to quantify generalization across new initial states and state transition functions. WebShop datasets are structured around distinct sets of shopping instructions, again partitioned to enforce out-of-distribution generalization requirements.
For offline learning methods, the paper comprehensively benchmarks seven algorithmic families:
Online RL (e.g., PPO) performance establishes an oracle upper bound.
Main Findings: Generalization Performance of Existing Methods
Key empirical findings highlight a large and persistent generalization gap in current offline RL approaches:
- On expert demonstrations, BC consistently outperforms all considered offline RL and sequence modeling algorithms on both held-in and held-out Procgen levels. All offline learning methods are substantially outperformed by online RL on test environments.
- Even with suboptimal data, the generalization advantage of BC over RL-based and sequence models persists, in direct contradiction to prior results from singleton environment benchmarks.
- Sequence modeling approaches (DT, BCT) sometimes match or even exceed offline RL methods on in-distribution (train) levels, but their performance drops significantly on unseen test levels, indicating poor out-of-distribution robustness.
- Increasing the diversity of environments in the training data, rather than merely increasing dataset size, yields the most significant improvement in test-time performance for all methods. Generalization gaps remain large if additional data is not accompanied by increased scenario diversity.
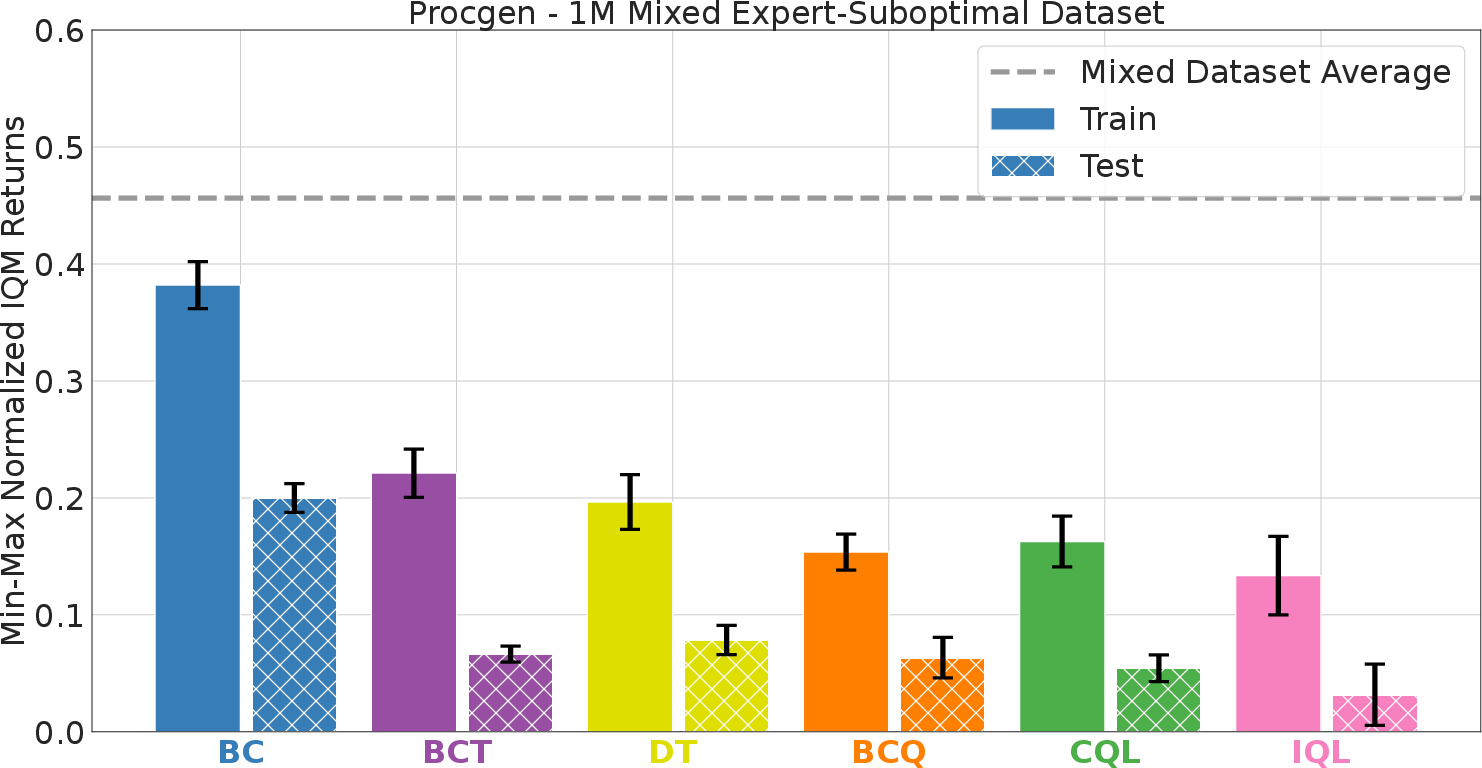
Figure 2: BC achieves the highest mean normalized test returns across all Procgen games in the 1M expert regime, outperforming both RL-based and sequence modeling methods on both train and test environments.
Figure 3: In mixed expert-suboptimal data regimes, BC maintains a sizeable generalization advantage on both training and test levels relative to all other offline methods.
WebShop Results
- On WebShop, BC outperforms BCQ and CQL in both average test scores and success rates, even when trained on human demonstrations or suboptimal, automatically generated trajectories.
- The performance benefits from larger and more diverse datasets, but improvements plateau unless more unique instruction types are included.
Analysis of Contributing Factors
Careful ablation and scaling studies clarify that:
- Data diversity is the single most critical factor for transfer to novel environments. Scaling the number of unique training environments (with fixed data volume per environment) substantially reduces the generalization gap.
- Increases in data size alone (more trajectories from the same environments) provide only marginal gains and do not close the generalization gap.
- Offline RL algorithms typically enforce risk-averse action selection to avoid extrapolating out-of-distribution, leading to overconservative policies that fail to generalize when states encountered at test time differ from those seen during training.
- BC, by more aggressively leveraging global regularities in state-action mappings (even without explicit risk controls), generalizes better at the cost of being more susceptible to distributional shift in sparse or poor-quality data.
Implications and Directions for Future Research
The findings in this paper provide strong, reproducible evidence that existing offline RL algorithms lack sufficient environment-level generalization capabilities for robust deployment. Behavioral Cloning, despite its theoretical weaknesses in off-distribution states, empirically offers the most stable generalization performance, notably contradicting established conclusions from singleton environment studies.
The critical implication is that offline RL, as currently instantiated, is not yet suitable for scalable deployment in applications requiring strict generalization guarantees to new scenarios, even with large and high-quality offline datasets. Methods based on risk-averse Q-learning or Transformer sequence modeling architectures are insufficient when confronted with nontrivial procedural or semantic novelty.
Future research must:
- Develop offline learning algorithms with new mechanisms for robust generalization, inspired potentially by data augmentation, contrastive and invariant representation learning, or uncertainty modeling approaches from online RL literature.
- Focus on scalable construction of diverse, high-entropy training datasets, rather than simply collecting more data from fixed scenarios.
- Expand offline RL benchmarks to more realistic, procedurally generated, and semantically structured domains, as exemplified by Procgen and WebShop.
- Pursue transformer variants capable of handling extended context windows, especially in compositional environments such as WebShop.
Conclusion
This study rigorously demonstrates the prevalence of the generalization gap in offline RL, even with modern algorithmic advances and large-scale data. Behavioral Cloning, not state-of-the-art offline RL or sequence modeling, provides the most robust out-of-distribution performance. True progress will require an explicit focus on generalization, both in algorithmic innovation and benchmark construction, to enable the reliable deployment of offline-trained agents in real-world environments where novelty is unavoidable.

