- The paper introduces MADRA, integrating retrieval-augmented reasoning to overcome cognitive constraints in multi-agent debates.
- It employs a self-selection module to autonomously filter relevant evidence from Wikipedia and Google, enhancing multi-hop reasoning.
- Experimental results on datasets like HotpotQA and FEVER show significant performance gains over baseline models including GPT-4.
Knowledge-Enhanced Reasoning in Multi-Agent Debates
The paper "Apollo's Oracle: Retrieval-Augmented Reasoning in Multi-Agent Debates" (2312.04854) introduces the Multi-Agent Debate with Retrieval Augmented (MADRA) framework, aiming to mitigate cognitive constraints that frequently arise in multi-agent debate systems. These constraints manifest as agents' persistent adherence to incorrect viewpoints or their tendency to abandon correct ones during debates. By integrating retrieval of prior knowledge into the debate process, MADRA seeks to enhance agents' reasoning capabilities, an approach that has been validated across diverse datasets and demonstrates significant improvements in performance.
Introduction to MADRA Framework
Debate systems involving multiple agents are increasingly employed to derive accurate conclusions in complex reasoning tasks. These systems leverage agents in varied roles, fostering interactions that range from cooperative to adversarial. Within this domain, one prevalent method is multi-agent debate (MAD), which is particularly effective in mitigating hallucinations commonly encountered in LLMs. However, MAD approaches encounter significant challenges due to cognitive constraints, where agents fail to correct erroneous views or prematurely discard valid ones.

Figure 1: Cognitive constraints of multi-agent debate process can lead to debate failure. Introducing prior knowledge into the debate process can break cognitive constraints.
The MADRA framework aims to address these cognitive constraints by incorporating retrieval-augmented reasoning. This approach introduces prior knowledge into the debate process and employs a self-selection module enabling agents to autonomously filter relevant evidence from an evidence pool, thereby enhancing reasoning capabilities and minimizing the impact of irrelevant data.
Debate Framework and Methodology
The MADRA framework is organized around three key roles: debaters, judges, and summarizers. Debaters independently present views and select evidence from a pool during the debate stages. Judges assess the consensus after each debate round, determining whether to conclude the debate, while summarizers synthesize final answers from the debater contributions.
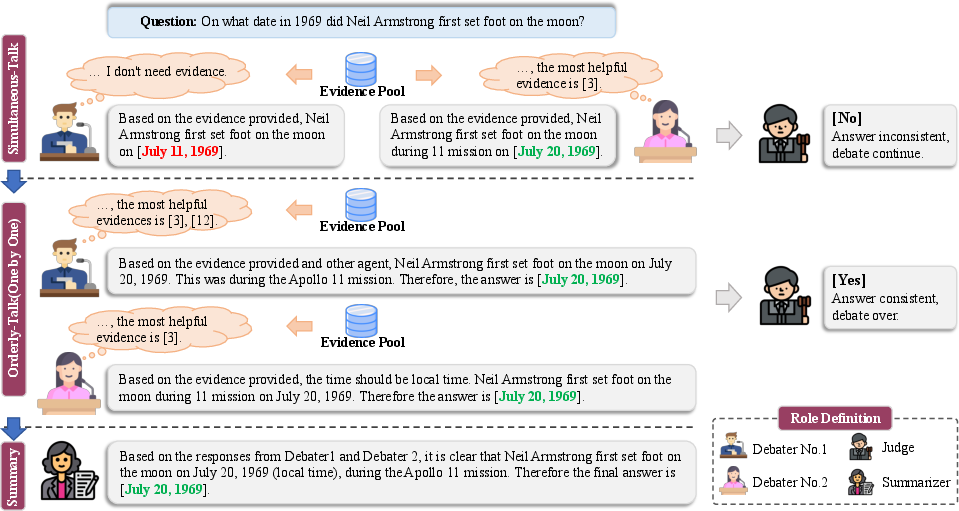
Figure 2: Framework of our multi-agent debate. Upon receiving the question, debaters initially present their views in the simultaneous-talk stage, followed by orderly individual debates in the next stage. A judge then assesses whether to conclude the debate after each round, and a summarizer compiles the final answers post-debate.
Incorporating retrieval knowledge into the debate involves two main sources: Wikipedia and Google. The evidence pool built from these sources assists agents in selecting useful evidence, crucial for mitigating cognitive constraints. The self-selection module allows agents to autonomously choose relevant evidence, thereby avoiding the incorporation of noisy or irrelevant information.
Experimental Evaluation
The experimental results demonstrate the efficacy of the MADRA framework across a variety of reasoning tasks, achieving substantial improvements compared to baseline methods. The framework's performance is particularly noteworthy in complex multi-hop reasoning and fact verification tasks, as reflected in datasets like HotpotQA and FEVER, where MADRA significantly surpasses established models including GPT-4.
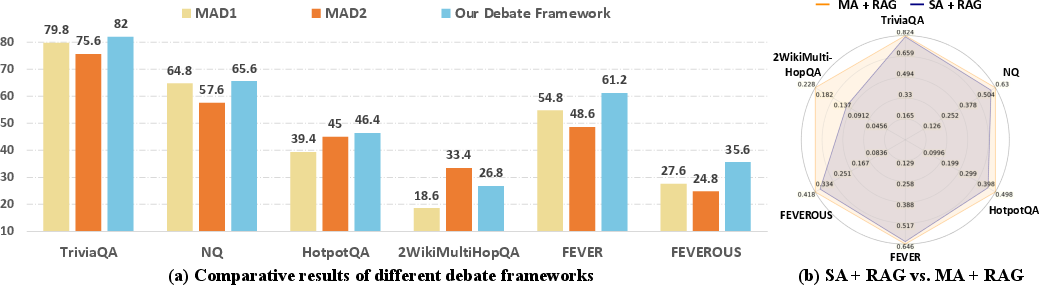
Figure 3: The effects of our debate framework (without retrieval knowledge).
Moreover, integrating retrieval-augmented methods into the framework has shown to enhance model performance dramatically, highlighting the strategic advantage of incorporating external knowledge sources in multi-agent debates.
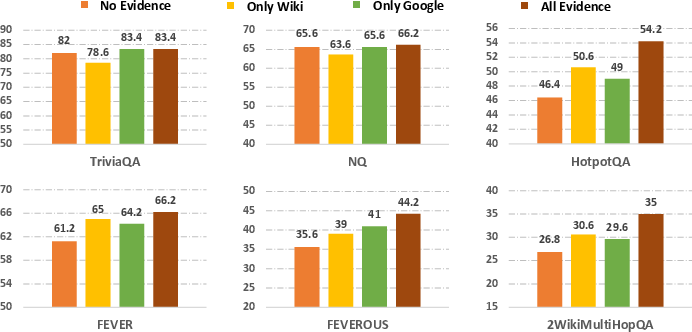
Figure 4: Model performance without retrieval knowledge and with different retrieval knowledge.
Discussion and Future Prospects
The introduction of prior knowledge into multi-agent debates offers promising avenues for enhancing the reasoning capabilities of LLM-based systems. The ability to navigate cognitive constraints effectively marks a significant stride in debate frameworks, paving the way for more accurate and consistent conclusions in complex reasoning tasks.
Looking ahead, further exploration of real-time knowledge retrieval and refined evidence selection methods will likely advance the field. The ongoing development of retrieval-augmented LLM systems presents a compelling research trajectory with substantial implications for AI-driven decision-making and collaborative reasoning environments.
Conclusion
The MADRA framework offers an innovative solution to overcoming cognitive constraints in multi-agent debates by leveraging retrieval-augmented reasoning. Through a systematic incorporation of prior knowledge and strategic evidence selection, MADRA significantly enhances debate outcomes, as demonstrated by comprehensive evaluations across diverse datasets. This approach not only improves factual accuracy and consistency but also sets a foundation for future developments in AI-driven reasoning systems.

