- The paper presents a compositional framework that decomposes complex robotic tasks into manageable subtasks for independent training and verification.
- It leverages a multifidelity pipeline combining low-fidelity simulation, high-fidelity SIL simulation, and hardware testing to ensure robust policy deployment.
- Experimental results on a Warthog unmanned ground robot demonstrate efficient adaptation to dynamic environments with minimal retraining overhead.
"A Multifidelity Sim-to-Real Pipeline for Verifiable and Compositional Reinforcement Learning" (2312.01249)
Overview
The paper introduces a compositional framework for reinforcement learning (RL) systems operating within a multifidelity sim-to-real pipeline. This framework is designed to facilitate the creation and deployment of reliable and adaptable RL policies on physical hardware. By decomposing intricate robotic tasks into more manageable subtasks, the framework allows for independent training and testing of RL policies, while providing assurances on the overall behavior through their composition.
Compositional Framework
The proposed framework leverages a high-level model (HLM) to manage complex decision-making processes. The HLM is a parametric Markov decision process (pMDP) that breaks down task-level specifications into subtask specifications, allowing for precise and goal-oriented training. Subtask policies are trained using a multifidelity simulation pipeline, enabling utilization and refinement in response to any discrepancies between simulation and reality.
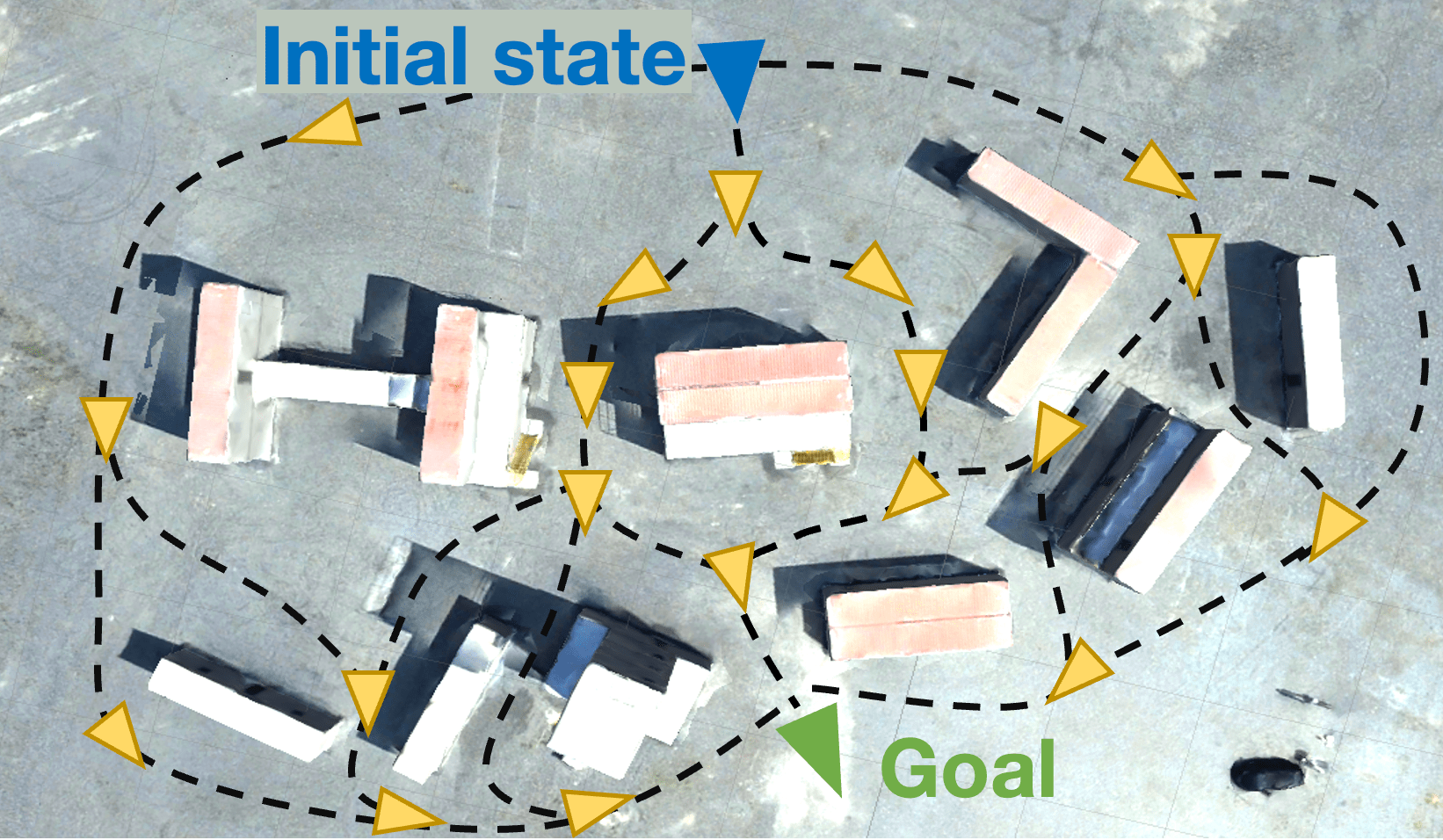

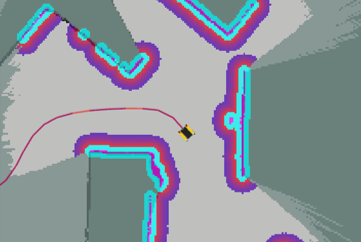

Figure 1: The proposed framework provides a compositional approach to training and verifying reinforcement learning (RL) policies in a multifidelity simulation pipeline, before deploying the trained policies on robot hardware.
This compositionality is achieved by planning and executing meta-policies that dictate which subtasks need to be completed to fulfill an overall task. The framework also enables iteration through feedback from simulations and hardware tests to update the HLM as needed.
Multifidelity Sim-to-Real Pipeline
The pipeline comprises three fidelity layers; an initial low-fidelity simulation for training and verifying subtask policies, a high-fidelity software-in-the-loop (SIL) simulation for integration testing, and deployment on physical hardware.
- Low-Fidelity Simulation: This stage utilizes simplified assumptions about sensor measurements and state estimations to efficiently train RL policies, focusing solely on the robot's physical dynamics.
- High-Fidelity SIL Simulation: This incorporates the entire autonomy software stack, providing it with realistic observation and decision-loop asynchrony to capture more accurate robot-environment interactions.
- Hardware Deployment: Finally, the policies verified through the HLM and tested in SIL simulations are deployed on the hardware. Performance data collected across these stages feeds back to the HLM for refinement.
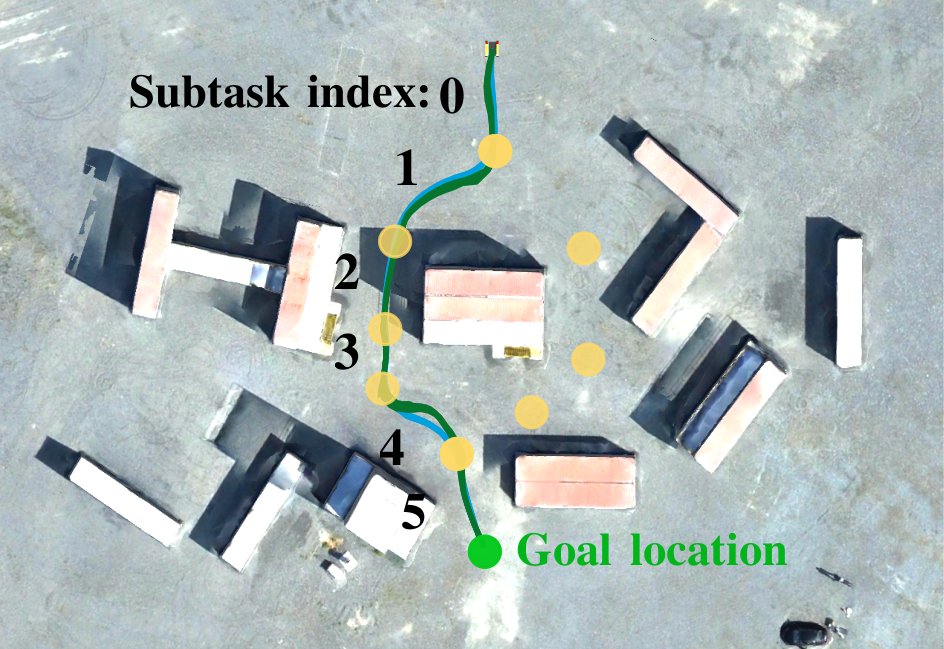
Figure 2: Left: Robot trajectories generated by a composition of subtask policies in the high-fidelity simulator (blue) and in the real world (green).
Experimental Validation
The paper details an experimental case study where the framework successfully trained and deployed RL policies to navigate a Warthog unmanned ground robot through complex environments. The multifidelity pipeline was critical for assessing and ensuring the policies' performance across changing environmental scenarios and facilitating necessary adaptions with minimal training overhead.
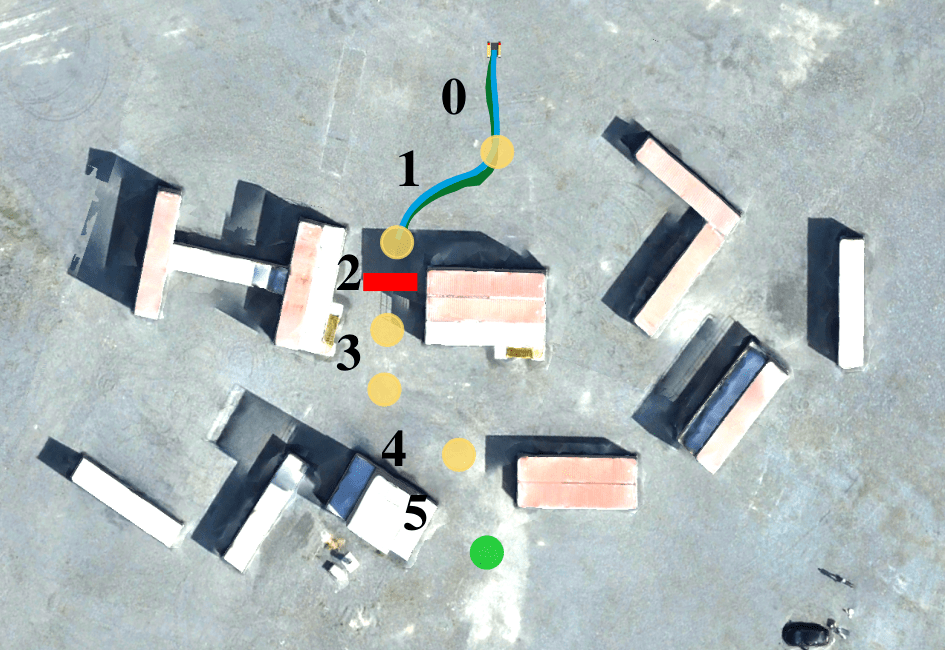

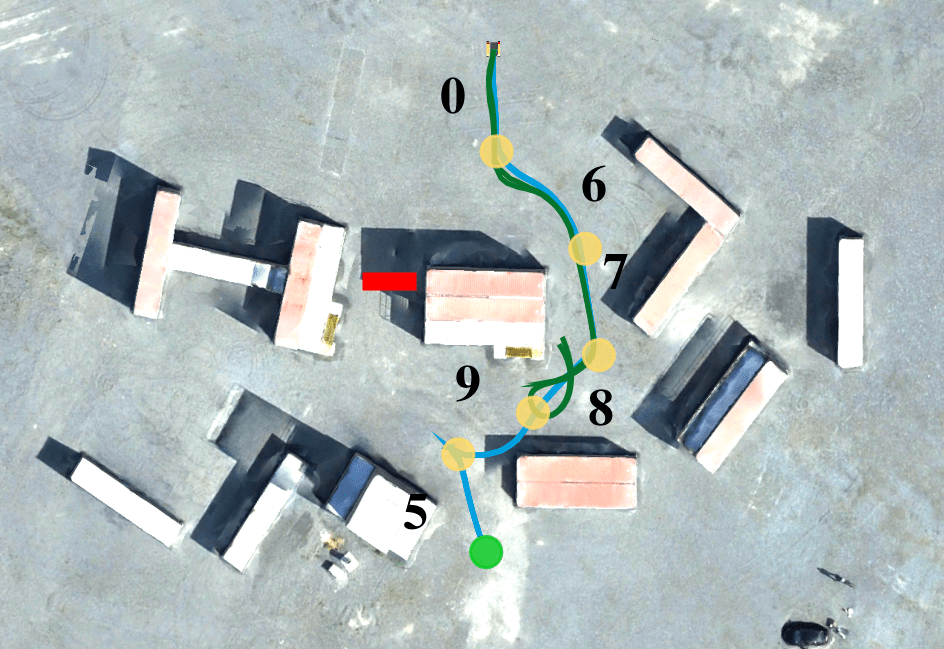
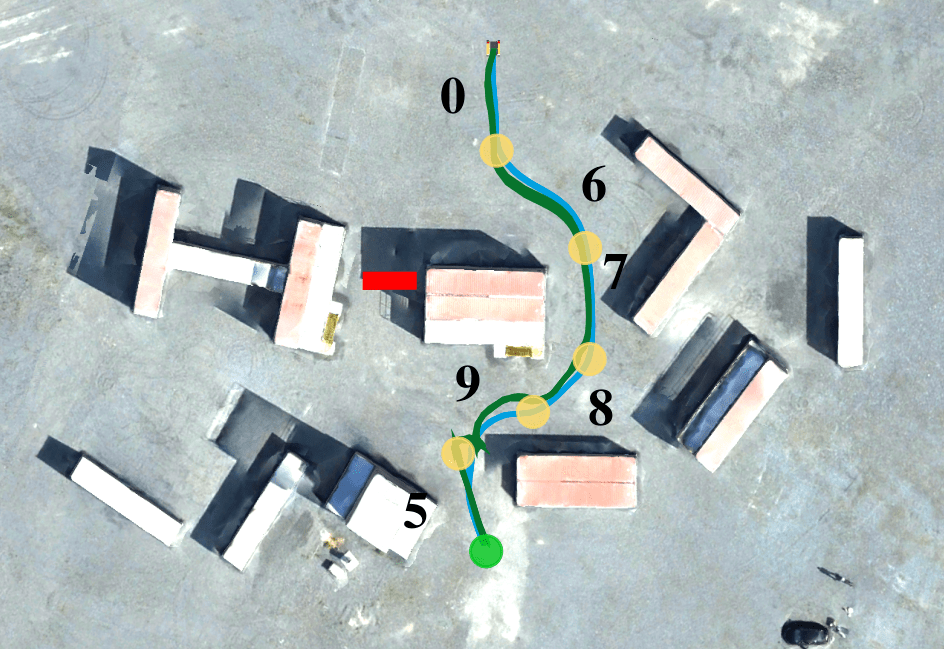
Figure 3: The compositional framework enables efficient adaptation to changes in the operating environment. It also simplifies the process of resolving sim-to-real errors.
Conclusion
This paper's framework integrates compositionality in RL and a multifidelity simulation pipeline to address challenges in deploying RL systems reliably on robotic hardware. The results demonstrate how the framework supports efficient learning, adapts to environmental changes, and addresses sim-to-real transfer issues. Future work could extend this approach to multi-robot systems and incorporate temporal logics for task specification. The structured learning environment and adaptive capabilities it fosters are poised to expedite the deployment of robust RL solutions across diverse robotic applications.