From Beginner to Expert: Modeling Medical Knowledge into General LLMs
Abstract: Recently, LLM based AI systems have demonstrated remarkable capabilities in natural language understanding and generation. However, these models face a significant challenge when it comes to sensitive applications, such as reasoning over medical knowledge and answering medical questions in a physician-like manner. Prior studies attempted to overcome this challenge by increasing the model size (>100B) to learn more general medical knowledge, while there is still room for improvement in LLMs with smaller-scale model sizes (<100B). In this work, we start from a pre-trained general LLM model (AntGLM-10B) and fine-tune it from a medical beginner towards a medical expert (called AntGLM-Med-10B), which leverages a 3-stage optimization procedure, i.e., general medical knowledge injection, medical domain instruction tuning, and specific medical task adaptation. Our contributions are threefold: (1) We specifically investigate how to adapt a pre-trained general LLM in medical domain, especially for a specific medical task. (2) We collect and construct large-scale medical datasets for each stage of the optimization process. These datasets encompass various data types and tasks, such as question-answering, medical reasoning, multi-choice questions, and medical conversations. (3) Specifically for multi-choice questions in the medical domain, we propose a novel Verification-of-Choice approach for prompting engineering, which significantly enhances the reasoning ability of LLMs. Remarkably, by combining the above approaches, our AntGLM-Med-10B model can outperform the most of LLMs on PubMedQA, including both general and medical LLMs, even when these LLMs have larger model size.
First 10 authors:
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (big picture)
This paper shows how to teach a general-purpose AI LLM to become much better at medical questions. The team starts with a regular LLM called AntGLM-10B and turns it into a medical specialist called AntGLM-Med-10B. They do this in three steps that are a lot like school: first the model “reads” medical knowledge, then it practices following medical instructions, and finally it trains hard on a specific kind of medical test. The goal is to make a smaller model (10 billion parameters) perform like a medical expert, even compared to larger models.
What the researchers wanted to find out
Here are the main questions they asked, in simple terms:
- How can we turn a general AI into a medical expert without making it huge?
- What training steps help most for medical skills: general reading, instruction practice, or focused test prep?
- Can smart prompting (like checking each multiple-choice option carefully) make the AI reason better on medical exams?
- Can a smaller, well-trained model beat bigger ones on tough medical benchmarks (like PubMedQA)?
How they trained the model (the approach, explained simply)
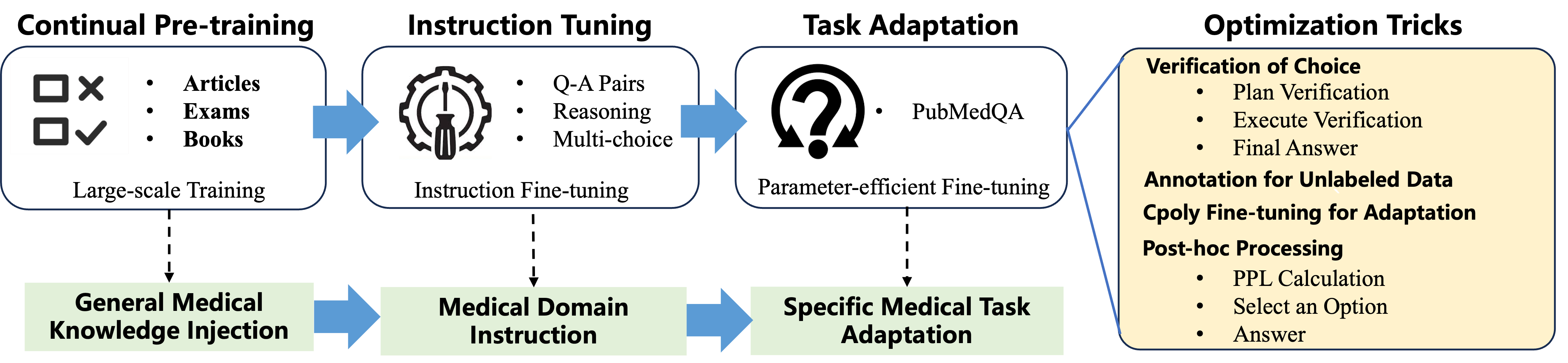
Think of the model as a student going from beginner to expert. The team used a three-stage plan:
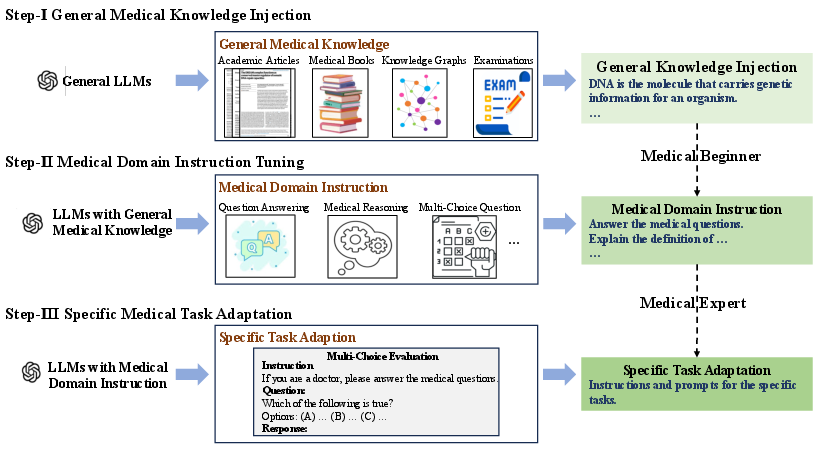
- Stage 1: General Medical Knowledge Injection
- Analogy: “Reading the textbook.”
- The model keeps pre-training on lots of medical text to learn the basics. This included:
- Medical books (clear, structured knowledge)
- Knowledge graphs (like a big map of medical facts turned into sentences)
- Medical Q&A pairs (real consultations)
- Exam questions (converted into readable facts)
- Medical articles (like PubMed abstracts and science articles)
- Goal: Build a strong medical foundation.
- Stage 2: Medical Domain Instruction Tuning
- Analogy: “Practicing with a teacher’s instructions.”
- The model learns to follow medical task instructions across many formats:
- Answering questions, reasoning, multiple-choice, and conversations
- This helps it understand how to respond properly to different medical prompts.
- Stage 3: Specific Medical Task Adaptation
- Analogy: “Focused test prep for a particular exam.”
- They target multiple-choice medical questions, especially the PubMedQA test (questions about medical research papers that have answers like yes/no/maybe).
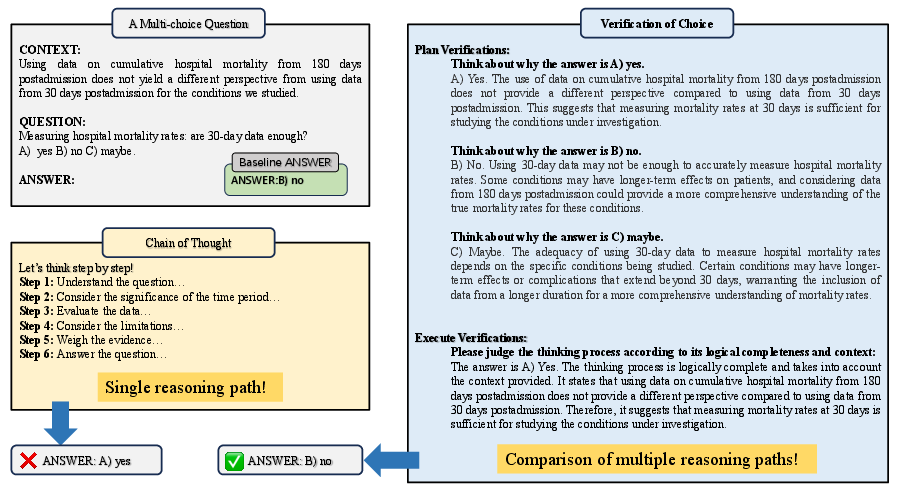
- They introduce a new prompting method called Verification-of-Choice (VoC):
- CoT (Chain-of-Thought) is like “show your work” for one answer.
- CoVE (Chain-of-Verification) is like “double-check your answer.”
- VoC goes further for multiple-choice: the model writes its reasoning for each choice (A, B, C), compares them, spots mistakes or mismatches, and then picks the best one. It’s like a student explaining every option before selecting the answer.
- They also use:
- LoRA/adapters: think “plug-in skills” that are small add-ons instead of retraining the whole brain, making training faster and cheaper.
- C-Poly (multi-task adapters): like having shared skill modules plus task-specific modules so the model can learn common tricks across tasks and still specialize.
- Perplexity ranking: a “how surprised am I?” score the model uses to pick the most likely choice.
They also cleverly labeled unlabeled training data (PQA-U) by having the model generate answers using VoC—like making “practice tests” with answer keys to learn from.
What they found and why it matters
Here are the standout results:
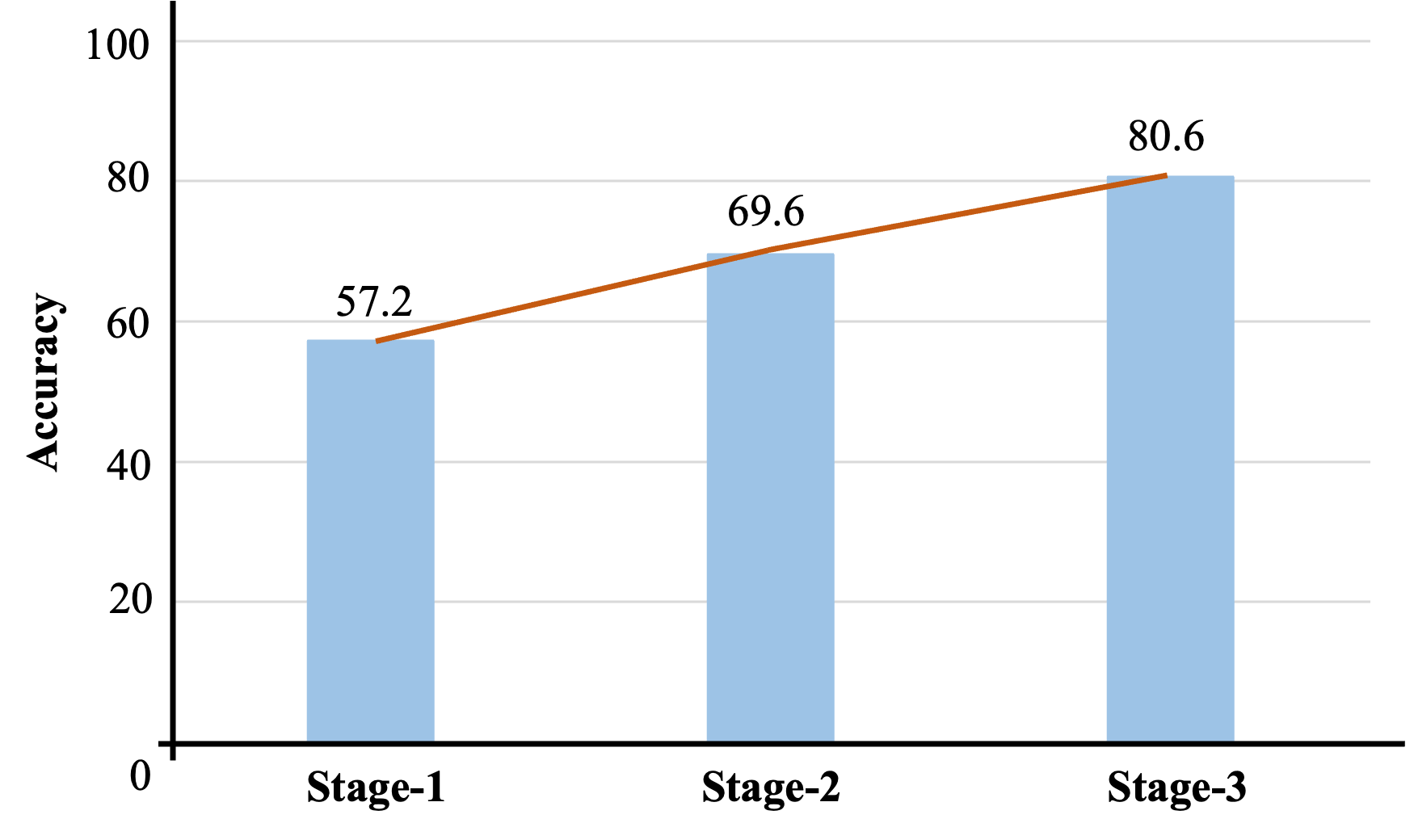
- Big accuracy jump across stages:
- Before any medical training, the model scored about 57.2% on PubMedQA.
- After the full three-stage process, it reached 80.6%.
- This shows each step added real value, especially the final, focused adaptation.
- Competitive performance with a smaller model:
- AntGLM-Med-10B (10B parameters) scored 80.6% on PubMedQA.
- That’s close to the very best models (like Med-PaLM 2 at 81.8%) and better than many larger models.
- Lesson: Smart training can beat raw size.
- Verification-of-Choice helps:
- Using VoC to label the unlabeled data improved results further.
- In short, explaining and checking each option before choosing boosts reasoning accuracy.
- Multi-task training with adapters (C-Poly) works well:
- Training on several related datasets together helped more than training on one at a time.
- Shared “common skills” plus “task-specific skills” made learning more efficient.
Why this is important: It shows you don’t need the biggest model to get expert-level performance if you train cleverly. This can make high-quality medical AI more accessible and efficient.
What this could mean for the future
- Better medical AI with fewer resources: Hospitals, clinics, and researchers could run strong models without always needing giant, expensive systems.
- Safer, more reliable reasoning: Techniques like Verification-of-Choice encourage the model to think carefully, not just guess—useful in sensitive fields like medicine.
- A roadmap for other expert fields: The same three-stage approach (read widely, practice instructions, then specialize) could help build expert AIs in law, finance, or engineering.
- Still, use with care: Even with strong results, medical AI should support—not replace—health professionals. Testing, supervision, and ethics remain crucial.
In short, this paper presents a smart training plan that turns a general AI into a capable medical assistant, showing that better “study habits” can rival sheer size.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper, written to be concrete and actionable for future research.
- Evaluation scope is narrow:
- Results focus primarily on PubMedQA; comprehensive benchmarks (e.g., MedQA-USMLE, MedMCQA, MMLU-Clinical, MultiMedQA) are not reported with standard splits, hindering claims about broad medical competence.
- No real-world, clinician-authored, or workflow-oriented evaluations (e.g., case vignettes, differential diagnosis, triage, guideline adherence).
- Reproducibility and evaluation protocol clarity:
- Inconsistent PubMedQA results (80.6% “main result” vs. 88%+ in fine-tuning table) with unclear splits, seeds, and whether the official test set and evaluation server were used.
- Several ablations use 500-sample subsets without specifying sampling protocols, seeds, or whether they match standard dev/test splits.
- Lack of full details on prompt templates, hyperparameters per stage, early stopping criteria, and selection of best checkpoints.
- Potential data contamination and leakage:
- PubMed abstracts are used for pretraining; only PQA-L abstracts are excluded, but possible overlaps with other PubMedQA subsets or evaluation-like data are not systematically deduplicated or reported.
- PQA-U pseudo-labels are generated using the dataset’s “long answers,” which may encode answer cues; deduplication and leakage audits (hashing, n-gram overlap, semantic similarity) are not provided.
- Quality and ethics of training data:
- Synthetic rewrites (knowledge graphs, exam questions) lack quality control studies (factual accuracy, consistency, bias).
- “Purchased professional medical articles” introduce licensing, usage rights, and provenance questions; no licensing or ethical review details provided.
- Real-world QA pairs may contain sensitive information; privacy protection, de-identification, and IRB/ethics approvals are not discussed.
- Cross-lingual generalization is untested:
- Training leverages extensive Chinese and English data, but performance on Chinese medical benchmarks (e.g., CMB, C-Eval medical tracks, CMExam, Huatuo-related test suites) is not reported, leaving bilingual transfer unknown.
- Generalization beyond multiple-choice is unproven:
- The approach and VoC prompting are tailored to multiple-choice; effectiveness on open-ended, long-form, or evidence-grounded medical QA (e.g., justification with citations) remains untested.
- No evaluation on tasks like summarization of clinical notes, guideline recommendation synthesis, or SOAP note generation.
- Verification-of-Choice (VoC) analysis is limited:
- No direct comparison with strong reasoning baselines (self-consistency, majority vote over CoT samples, debate, verifiers/critics, PoT/program-of-thought, tool-augmented verification).
- Computational overhead (latency, token budget) of VoC is not quantified; cost–benefit trade-offs are unknown.
- VoC’s robustness with >3 options, longer contexts, and adversarial distractors is untested.
- No analysis of VoC failure modes (e.g., confirmation bias, inconsistent rationales).
- Hallucination and faithfulness not rigorously measured:
- Claims about reduced hallucination via verification are not supported by standardized metrics (e.g., fact-score, attribution fidelity) or third-party fact-checking benchmarks.
- No tests of rationale faithfulness (e.g., causal scrubbing, input perturbation studies) for CoT/VoC explanations.
- Uncertainty and calibration remain open:
- Perplexity-based selection is used ad hoc without calibration evaluation (ECE, Brier score), selective prediction, or abstention strategies for safety-critical settings.
- Safety, harm, and bias:
- No safety alignment (RLHF with clinical constraints, constitutional health policies), bias/disparity audits, or toxicity/unsafe advice evaluations.
- No adverse event simulation or harm-reduction protocols; no mechanism for refusal/triage when uncertain.
- Catastrophic forgetting and retained general abilities:
- The impact of medical specialization on general-domain capabilities is unmeasured (pre/post comparisons on general benchmarks like MMLU, HELM, BIG-Bench, or GLUE/SuperGLUE).
- Multi-task adapter method (C-Poly) limitations:
- Authors note that C-Poly’s router “cannot index and effectively predict untrained unknown tasks”; generalization and out-of-distribution task routing remain unresolved.
- No comparison with alternative MTL/PEFT methods (e.g., mixture-of-adapters, prompt-tuning, IA3, (IA)3, LoRA variants with routing, sparsely gated MoE) under equal compute.
- Scaling and data ablations are missing:
- No systematic scaling study across model sizes (e.g., 7B/13B/34B) or data sizes per corpus; contributions of each corpus (books, KGs, exams, QA, articles) to final performance remain opaque.
- No study of continual pretraining duration vs. gains or instruction-tuning mixture composition and sampling strategies.
- Training efficiency and environmental impact:
- Wall-clock time, total tokens seen, compute budget, and energy usage are not reported; implications for reproducibility and sustainability are unclear.
- Error analysis is absent:
- No breakdown by question type (causal, statistical, trial design), linguistic phenomena (negation, numerical reasoning), clinical domain (cardio, oncology), or class (yes/no/maybe) to guide targeted improvements.
- Robustness and security:
- No robustness evaluation against noisy abstracts, contradicting evidence, prompt injection, or distribution shifts (e.g., newer PubMed years, non-PubMed sources).
- Retrieval and tool augmentation:
- The approach is purely parametric; benefits of retrieval-augmented generation (e.g., PubMed search with grounding and citation), tool use (calculators, guidelines), or external verifiers are unexplored.
- Deployment constraints:
- Inference latency, memory footprint, and throughput—especially with VoC—are not quantified; suitability for clinical settings with time constraints is unknown.
- Transparency and release:
- It is unclear whether the model, prompts, and curated datasets (with licenses) will be released; lack of artifacts limits independent verification and broader impact.
- Pseudo-labeling of PQA-U remains uncertain:
- No human auditing of pseudo-label accuracy or estimated noise rate; no confidence-thresholding, self-training iterations, or co-teaching strategies to mitigate label noise.
- Outdated or incomplete baselines:
- Comparisons exclude several recent open-source medical LLMs (e.g., LLaMA-2/3-based med models, BioGPT-XL, ClinicalCamel, PMC-LLaMA, MedAlpaca variants), limiting the strength of claims about competitiveness.
- Clinical integration and governance:
- No discussion of how the system would integrate with clinical workflows, EHRs, audit trails, or regulatory requirements (e.g., ISO/IEC, FDA/EMA guidance for clinical AI).
Collections
Sign up for free to add this paper to one or more collections.