AV-RIR: Audio-Visual Room Impulse Response Estimation
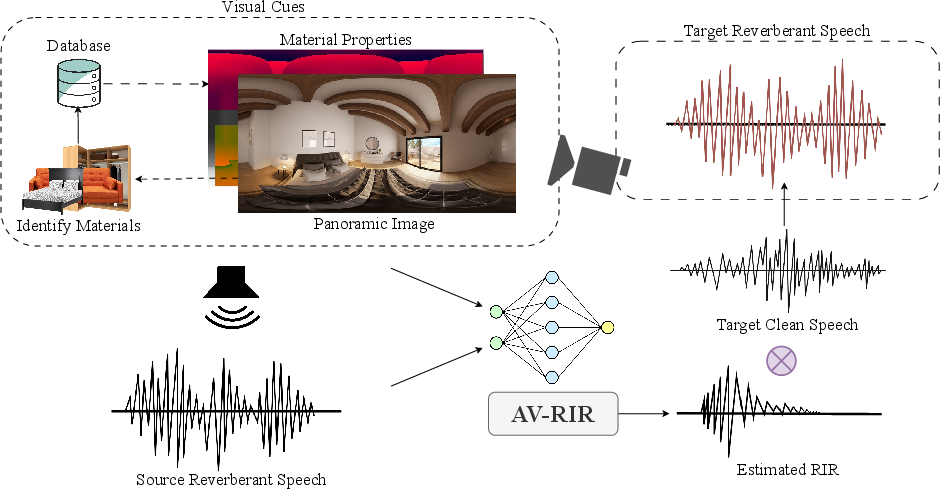
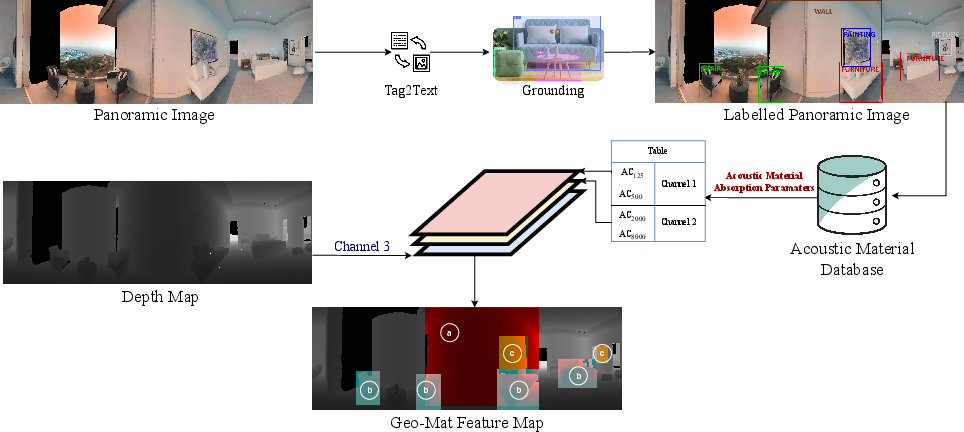
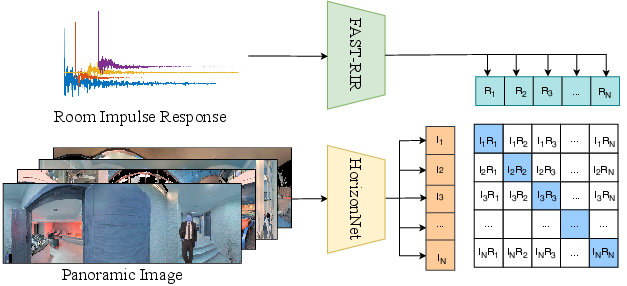
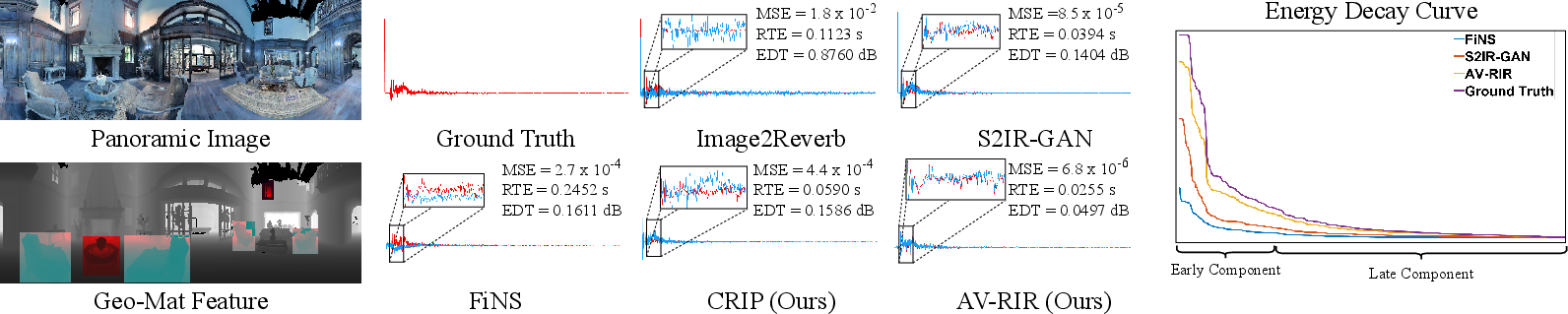
Abstract: Accurate estimation of Room Impulse Response (RIR), which captures an environment's acoustic properties, is important for speech processing and AR/VR applications. We propose AV-RIR, a novel multi-modal multi-task learning approach to accurately estimate the RIR from a given reverberant speech signal and the visual cues of its corresponding environment. AV-RIR builds on a novel neural codec-based architecture that effectively captures environment geometry and materials properties and solves speech dereverberation as an auxiliary task by using multi-task learning. We also propose Geo-Mat features that augment material information into visual cues and CRIP that improves late reverberation components in the estimated RIR via image-to-RIR retrieval by 86%. Empirical results show that AV-RIR quantitatively outperforms previous audio-only and visual-only approaches by achieving 36% - 63% improvement across various acoustic metrics in RIR estimation. Additionally, it also achieves higher preference scores in human evaluation. As an auxiliary benefit, dereverbed speech from AV-RIR shows competitive performance with the state-of-the-art in various spoken language processing tasks and outperforms reverberation time error score in the real-world AVSpeech dataset. Qualitative examples of both synthesized reverberant speech and enhanced speech can be found at https://www.youtube.com/watch?v=tTsKhviukAE.
- About this reverberation business. 1977.
- Steam audio, 2018.
- Oculus spatializer, 2019.
- Microsoft project acoustics, 2019.
- Audiocite.net: Livres audio gratuits mp3, 2023.
- Nobuharu Aoshima. Computer‐generated pulse signal applied for sound measurement. Journal of the Acoustical Society of America, 69:1484–1488, 1981.
- Auditorium Acoustics and Architectural Design. The Journal of the Acoustical Society of America, 96(1):612–612, 1994.
- Boundary element methods in acoustics. 1991.
- Interactive sound propagation with bidirectional path tracing. ACM Trans. Graph., 35(6):180:1–180:11, 2016.
- The ami meeting corpus: A pre-announcement. In Proceedings of the Second International Conference on Machine Learning for Multimodal Interaction, page 28–39, Berlin, Heidelberg, 2005. Springer-Verlag.
- Matterport3d: Learning from rgb-d data in indoor environments. International Conference on 3D Vision (3DV), 2017.
- Soundspaces: Audio-visual navigaton in 3d environments. In ECCV, 2020.
- Visual acoustic matching. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 18858–18868, 2022a.
- Soundspaces 2.0: A simulation platform for visual-acoustic learning. In NeurIPS 2022 Datasets and Benchmarks Track, 2022b.
- Novel-view acoustic synthesis. In 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 6409–6419, 2023a.
- Learning audio-visual dereverberation. In ICASSP 2023 - 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5, 2023b.
- Be everywhere - hear everything (bee): Audio scene reconstruction by sparse audio-visual samples. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 7853–7862, 2023c.
- Adverb: Visually guided audio dereverberation. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 7884–7896, 2023.
- Room impulse response estimation using sparse online prediction and absolute loss. In 2006 IEEE International Conference on Acoustics Speech and Signal Processing Proceedings, pages III–III, 2006.
- Simultaneous echo cancellation and car noise suppression employing a microphone array. In 1997 IEEE International Conference on Acoustics, Speech, and Signal Processing, pages 239–242 vol.1, 1997.
- High fidelity neural audio compression. arXiv preprint arXiv:2210.13438, 2022.
- Real Time Speech Enhancement in the Waveform Domain. In Proc. Interspeech 2020, pages 3291–3295, 2020.
- Looking to listen at the cocktail party: A speaker-independent audio-visual model for speech separation. ACM Trans. Graph., 37(4), 2018.
- Speech dereverberation using fully convolutional networks. In 2018 26th European Signal Processing Conference (EUSIPCO), pages 390–394, 2018.
- Angelo Farina. Advancements in impulse response measurements by sine sweeps. Journal of The Audio Engineering Society, 2007.
- Sparse modeling of the early part of noisy room impulse responses with sparse bayesian learning. In ICASSP 2022 - 2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 586–590, 2022.
- Metricgan+: An improved version of metricgan for speech enhancement. arXiv preprint arXiv:2104.03538, 2021.
- Visual Speech Enhancement. In Proc. Interspeech 2018, pages 1170–1174, 2018.
- Digging into self-supervised monocular depth prediction. 2019.
- Deep residual learning for image recognition. In 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 770–778, 2016.
- Audio-visual speech enhancement using multimodal deep convolutional neural networks. IEEE Transactions on Emerging Topics in Computational Intelligence, 2(2):117–128, 2018.
- Tag2text: Guiding vision-language model via image tagging. arXiv preprint arXiv:2303.05657, 2023.
- Cortical adaptation to sound reverberation. eLife, 11:e75090, 2022.
- A multi-microphone signal subspace approach for speech enhancement. In 2001 IEEE International Conference on Acoustics, Speech, and Signal Processing. Proceedings (Cat. No.01CH37221), pages 205–208 vol.1, 2001.
- Generative Adversarial Network-Based Postfilter for STFT Spectrograms. In Proc. Interspeech 2017, pages 3389–3393, 2017.
- Estimation of modal decay parameters from noisy response measurements. Journal of the Audio Engineering Society, 50(11):867–878, 2002.
- Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014.
- A summary of the reverb challenge: State-of-the-art and remaining challenges in reverberant speech processing research. Journal on Advances in Signal Processing, 2016, 2016.
- Segment anything. arXiv:2304.02643, 2023.
- Christoph Kling. Absorption coefficient database, 2018.
- Hifi-gan: Generative adversarial networks for efficient and high fidelity speech synthesis. In Advances in Neural Information Processing Systems, pages 17022–17033. Curran Associates, Inc., 2020.
- Complex-Valued Time-Frequency Self-Attention for Speech Dereverberation. In Proc. Interspeech 2022, pages 2543–2547, 2022a.
- Vinay Kothapally and John H. L. Hansen. Skipconvgan: Monaural speech dereverberation using generative adversarial networks via complex time-frequency masking. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 30:1600–1613, 2022b.
- Melgan: Generative adversarial networks for conditional waveform synthesis. In Advances in Neural Information Processing Systems. Curran Associates, Inc., 2019.
- Yet another generative model for room impulse response estimation. In 2023 IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA), pages 1–5, 2023.
- Virtual reality system with integrated sound field simulation and reproduction. EURASIP J. Adv. Signal Process, 2007(1):187, 2007.
- Real-time speech frequency bandwidth extension. In ICASSP 2021 - 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 691–695, 2021.
- Av-nerf: Learning neural fields for real-world audio-visual scene synthesis. arXiv preprint arXiv:2302.02088, 2023a.
- Neural acoustic context field: Rendering realistic room impulse response with neural fields. In NeurIPS, 2023b.
- Bayesian regularization and nonnegative deconvolution for room impulse response estimation. IEEE Transactions on Signal Processing, 54(3):839–847, 2006.
- VoiceFixer: A Unified Framework for High-Fidelity Speech Restoration. In Proc. Interspeech 2022, pages 4232–4236, 2022.
- Sound Synthesis, Propagation, and Rendering. Morgan & Claypool Publishers, 2022.
- Grounding dino: Marrying dino with grounded pre-training for open-set object detection. arXiv preprint arXiv:2303.05499, 2023.
- Learning neural acoustic fields. In Advances in Neural Information Processing Systems, pages 3165–3177. Curran Associates, Inc., 2022.
- Few-shot audio-visual learning of environment acoustics. In Advances in Neural Information Processing Systems, 2022.
- Analysis of noise reduction and dereverberation techniques based on microphone arrays with postfiltering. IEEE Transactions on Speech and Audio Processing, 6(3):240–259, 1998.
- Wave-based sound propagation in large open scenes using an equivalent source formulation. ACM Trans. Graph., 32(2), 2013.
- Inverse filtering of room acoustics. IEEE Transactions on Acoustics, Speech, and Signal Processing, 36(2):145–152, 1988.
- Speech dereverberation based on variance-normalized delayed linear prediction. IEEE Transactions on Audio, Speech, and Language Processing, 18(7):1717–1731, 2010.
- Speech Dereverberation. Springer Publishing Company, Incorporated, 1st edition, 2010.
- Librispeech: An asr corpus based on public domain audio books. In 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 5206–5210, 2015.
- Tcnn: Temporal convolutional neural network for real-time speech enhancement in the time domain. In ICASSP 2019 - 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 6875–6879, 2019.
- Machine-learning-based estimation of reverberation time using room geometry for room effect rendering. In Proceedings of the 23rd International Congress on Acoustics: integrating 4th EAA Euroregio, page 13, 2019.
- Learning transferable visual models from natural language supervision. In International conference on machine learning, pages 8748–8763. PMLR, 2021.
- Interactive and Immersive Auralization. Springer, 2022.
- Precomputed wave simulation for real-time sound propagation of dynamic sources in complex scenes. ACM Trans. Graph., 29(4), 2010.
- Listen2Scene: Interactive material-aware binaural sound propagation for reconstructed 3D scenes. arXiv e-prints, art. arXiv:2302.02809, 2023.
- IR-GAN: room impulse response generator for far-field speech recognition. In Interspeech, pages 286–290. ISCA, 2021.
- Mesh2ir: Neural acoustic impulse response generator for complex 3d scenes. In Proceedings of the 30th ACM International Conference on Multimedia, page 924–933, New York, NY, USA, 2022a. Association for Computing Machinery.
- Fast-rir: Fast neural diffuse room impulse response generator. In ICASSP 2022 - 2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 571–575, 2022b.
- Towards improved room impulse response estimation for speech recognition. In ICASSP 2023 - 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5, 2023.
- SpeechBrain: A general-purpose speech toolkit, 2021. arXiv:2106.04624.
- Generating diverse high-fidelity images with vq-vae-2. In Advances in Neural Information Processing Systems. Curran Associates, Inc., 2019.
- Sentence-BERT: Sentence embeddings using Siamese BERT-networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 3982–3992, Hong Kong, China, 2019. Association for Computational Linguistics.
- Small-rooms dedicated to music: From room response analysis to acoustic design. Journal of The Audio Engineering Society, 2016.
- Gsound: Interactive sound propagation for games. In Audio Engineering Society Conference: 41st International Conference: Audio for Games. Audio Engineering Society, 2011.
- Interactive sound propagation and rendering for large multi-source scenes. ACM Trans. Graph., 36(4), 2016.
- Acoustic classification and optimization for multi-modal rendering of real-world scenes. IEEE Transactions on Visualization and Computer Graphics, 24(3):1246–1259, 2018.
- M. R. Schroeder. Integrated‐impulse method measuring sound decay without using impulses. The Journal of the Acoustical Society of America, 66(2):497–500, 1979.
- M. R. Schroeder. New Method of Measuring Reverberation Time. The Journal of the Acoustical Society of America, 37(3):409–412, 2005.
- Image2reverb: Cross-modal reverb impulse response synthesis. In ICCV, pages 286–295. IEEE, 2021.
- Self-supervised visual acoustic matching. In NeurIPS, 2023.
- Filtered noise shaping for time domain room impulse response estimation from reverberant speech. In 2021 IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA), pages 221–225, 2021.
- HiFi-GAN: High-Fidelity Denoising and Dereverberation Based on Speech Deep Features in Adversarial Networks. In Proc. Interspeech 2020, pages 4506–4510, 2020.
- Horizonnet: Learning room layout with 1d representation and pano stretch data augmentation. In 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 1047–1056, 2019.
- Scene-aware audio rendering via deep acoustic analysis. IEEE Transactions on Visualization and Computer Graphics, 26(5):1991–2001, 2020.
- Gwa: A large high-quality acoustic dataset for audio processing. In ACM SIGGRAPH 2022 Conference Proceedings, New York, NY, USA, 2022. Association for Computing Machinery.
- Guided multiview ray tracing for fast auralization. IEEE Transactions on Visualization and Computer Graphics, 18(11):1797–1810, 2012.
- Neural discrete representation learning. In Advances in Neural Information Processing Systems. Curran Associates, Inc., 2017.
- A review of vector quantization techniques. IEEE Potentials, 25(4):39–47, 2006.
- Cross-domain diffusion based speech enhancement for very noisy speech. In ICASSP 2023 - 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5, 2023.
- Audiodec: An open-source streaming high-fidelity neural audio codec. In ICASSP 2023 - 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5, 2023.
- Hifi-codec: Group-residual vector quantization for high fidelity audio codec. arXiv preprint arXiv:2305.02765, 2023.
- Audio-visual speech codecs: Rethinking audio-visual speech enhancement by re-synthesis. In 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 8217–8227, 2022.
- Wave-ray coupling for interactive sound propagation in large complex scenes. ACM Trans. Graph., 32(6), 2013.
- Soundstream: An end-to-end neural audio codec. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 30:495–507, 2022.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.