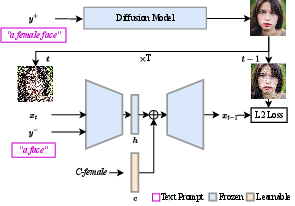
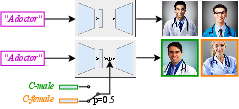
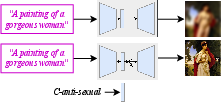
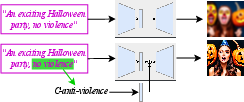
Self-Discovering Interpretable Diffusion Latent Directions for Responsible Text-to-Image Generation
Abstract: Diffusion-based models have gained significant popularity for text-to-image generation due to their exceptional image-generation capabilities. A risk with these models is the potential generation of inappropriate content, such as biased or harmful images. However, the underlying reasons for generating such undesired content from the perspective of the diffusion model's internal representation remain unclear. Previous work interprets vectors in an interpretable latent space of diffusion models as semantic concepts. However, existing approaches cannot discover directions for arbitrary concepts, such as those related to inappropriate concepts. In this work, we propose a novel self-supervised approach to find interpretable latent directions for a given concept. With the discovered vectors, we further propose a simple approach to mitigate inappropriate generation. Extensive experiments have been conducted to verify the effectiveness of our mitigation approach, namely, for fair generation, safe generation, and responsible text-enhancing generation. Project page: \url{https://interpretdiffusion.github.io}.
- Mitigating inappropriateness in image generation: Can there be value in reflecting the world’s ugliness? arXiv preprint arXiv:2305.18398, 2023.
- Debiasing vision-language models via biased prompts. arXiv preprint arXiv:2302.00070, 2023.
- Fair diffusion: Instructing text-to-image generation models on fairness. arXiv preprint arXiv:2302.10893, 2023.
- Scalable detection of offensive and non-compliant content/logo in product images. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 2247–2256, 2020.
- Erasing concepts from diffusion models. In Proceedings of the 2023 IEEE International Conference on Computer Vision, 2023.
- Unified concept editing in diffusion models. IEEE/CVF Winter Conference on Applications of Computer Vision, 2024.
- Towards robust prompts on vision-language models. arXiv preprint arXiv:2304.08479, 2023a.
- A systematic survey of prompt engineering on vision-language foundation models. arXiv preprint arXiv:2307.12980, 2023b.
- Discovering interpretable directions in the semantic latent space of diffusion models. arXiv preprint arXiv:2303.11073, 2023.
- Selective amnesia: A continual learning approach to forgetting in deep generative models. arXiv preprint arXiv:2305.10120, 2023.
- Prompt-to-prompt image editing with cross attention control. arXiv preprint arXiv:2208.01626, 2022.
- Classifier-free diffusion guidance. NeurIPS 2021 Workshop on Deep Generative Models and Downstream Applications, 2021.
- Denoising diffusion probabilistic models. Advances in neural information processing systems, 33:6840–6851, 2020.
- Training-free style transfer emerges from h-space in diffusion models. arXiv preprint arXiv:2303.15403, 2023.
- Elucidating the design space of diffusion-based generative models. Advances in Neural Information Processing Systems, 35:26565–26577, 2022.
- Diffusionclip: Text-guided diffusion models for robust image manipulation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2426–2435, 2022.
- Ablating concepts in text-to-image diffusion models. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 22691–22702, 2023.
- Diffusion models already have a semantic latent space. In The Eleventh International Conference on Learning Representations, 2023.
- Diffusegae: Controllable and high-fidelity image manipulation from disentangled representation. arXiv preprint arXiv:2307.05899, 2023.
- Do dall-e and flamingo understand each other? In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 1999–2010, 2023.
- Microsoft coco: Common objects in context. In Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part V 13, pages 740–755. Springer, 2014.
- Cones: Concept neurons in diffusion models for customized generation. arXiv preprint arXiv:2303.05125, 2023.
- An image is worth 1000 lies: Transferability of adversarial images across prompts on vision-language models. In The Twelfth International Conference on Learning Representations, 2023.
- Improving adversarial transferability via model alignment. arXiv preprint arXiv:2311.18495, 2023.
- SDEdit: Guided image synthesis and editing with stochastic differential equations. In International Conference on Learning Representations, 2022.
- Null-text inversion for editing real images using guided diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6038–6047, 2023.
- Ores: Open-vocabulary responsible visual synthesis. arXiv preprint arXiv:2308.13785, 2023a.
- Degeneration-tuning: Using scrambled grid shield unwanted concepts from stable diffusion. In Proceedings of the 31st ACM International Conference on Multimedia, pages 8900–8909, 2023b.
- Editing implicit assumptions in text-to-image diffusion models. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 7053–7061, 2023.
- Understanding the latent space of diffusion models through the lens of riemannian geometry. In Advances in Neural Information Processing Systems, 2023.
- Scalable diffusion models with transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 4195–4205, 2023.
- Large image datasets: A pyrrhic win for computer vision? arXiv preprint arXiv:2006.16923, 2020.
- Diffusion autoencoders: Toward a meaningful and decodable representation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10619–10629, 2022.
- Learning transferable visual models from natural language supervision. In International conference on machine learning, pages 8748–8763. PMLR, 2021.
- Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:2204.06125, 1(2):3, 2022.
- Red-teaming the stable diffusion safety filter. arXiv preprint arXiv:2210.04610, 2022.
- High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022.
- Can machines help us answering question 16 in datasheets, and in turn reflecting on inappropriate content? In Proceedings of the 2022 ACM Conference on Fairness, Accountability, and Transparency, pages 1350–1361, 2022.
- Safe latent diffusion: Mitigating inappropriate degeneration in diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22522–22531, 2023.
- Freeu: Free lunch in diffusion u-net. arXiv preprint arXiv:2309.11497, 2023.
- Deep unsupervised learning using nonequilibrium thermodynamics. In International conference on machine learning, pages 2256–2265. PMLR, 2015.
- Score-based generative modeling through stochastic differential equations. arXiv preprint arXiv:2011.13456, 2020.
- Linear spaces of meanings: Compositional structures in vision-language models. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 15395–15404, 2023.
- Plug-and-play diffusion features for text-driven image-to-image translation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1921–1930, 2023.
- Infodiffusion: Representation learning using information maximizing diffusion models. arXiv preprint arXiv:2306.08757, 2023.
- Uncovering the disentanglement capability in text-to-image diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1900–1910, 2023.
- Iti-gen: Inclusive text-to-image generation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 3969–3980, 2023a.
- Forget-me-not: Learning to forget in text-to-image diffusion models. arXiv preprint arXiv:2303.17591, 2023b.
- Adding conditional control to text-to-image diffusion models. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 3836–3847, 2023c.
- To generate or not? safety-driven unlearned diffusion models are still easy to generate unsafe images… for now. arXiv preprint arXiv:2310.11868, 2023d.
- Unsupervised representation learning from pre-trained diffusion probabilistic models. Advances in Neural Information Processing Systems, 35:22117–22130, 2022.
- Gender bias in coreference resolution: Evaluation and debiasing methods. arXiv preprint arXiv:1804.06876, 2018.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

