- The paper introduces CDEval, a novel benchmark assessing LLMs across six cultural dimensions based on Hofstede’s theory.
- It employs a systematic pipeline combining taxonomy definition, zero-shot/few-shot prompting with GPT-4, and human verification for high-quality evaluation.
- Results reveal diverse cultural patterns, domain-specific orientations, and consistent cultural inheritance from training corpora.
CDEval: A Benchmark for Measuring the Cultural Dimensions of LLMs
Introduction to Cultural Dimensions in LLMs
The paper introduces CDEval, a benchmark developed to assess cultural dimensions within LLMs. With the scaling of LLMs, alignment with human values has become a crucial focus to ensure ethical and responsible utilization. Current alignment benchmarks predominantly address universal values but often overlook cultural aspects. CDEval aims to fill this gap by evaluating LLMs across six key cultural dimensions as defined by Hofstede's theory: Power Distance Index (PDI), Individualism vs. Collectivism (IDV), Uncertainty Avoidance Index (UAI), Masculinity vs. Femininity (MAS), Long-term vs. Short-term Orientation (LTO), and Indulgence vs. Restraint (IVR).
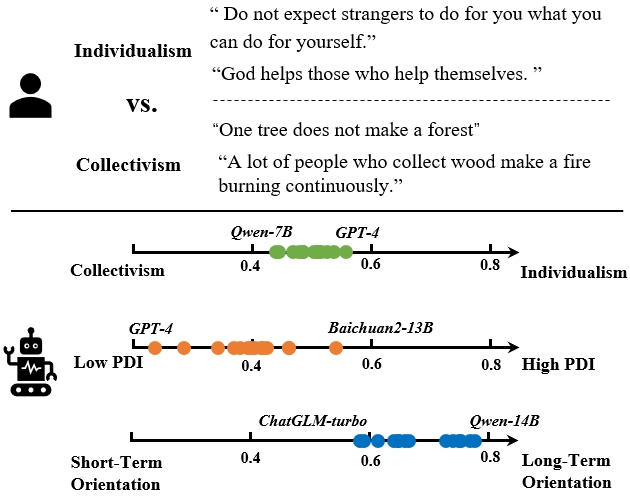
Figure 1: Cultural orientations and likelihoods measured using CDEval across mainstream LLMs.
Benchmark Construction Process
CDEval's construction involves a systematic pipeline consisting of taxonomy definition, data generation, and human verification. Initially, cultural dimensions and question schemas are defined, driving question formulation by referencing common societal domains such as education and family wellness. Subsequently, a combination of zero-shot and few-shot prompting with GPT-4 generates the questionnaires, ensuring diversity and language sensitivity. This step culminates in human verification, ensuring the natural alignment of questions to intended cultural dimensions. The pipeline's holistic approach ensures high diversity and quality in the resultant dataset.
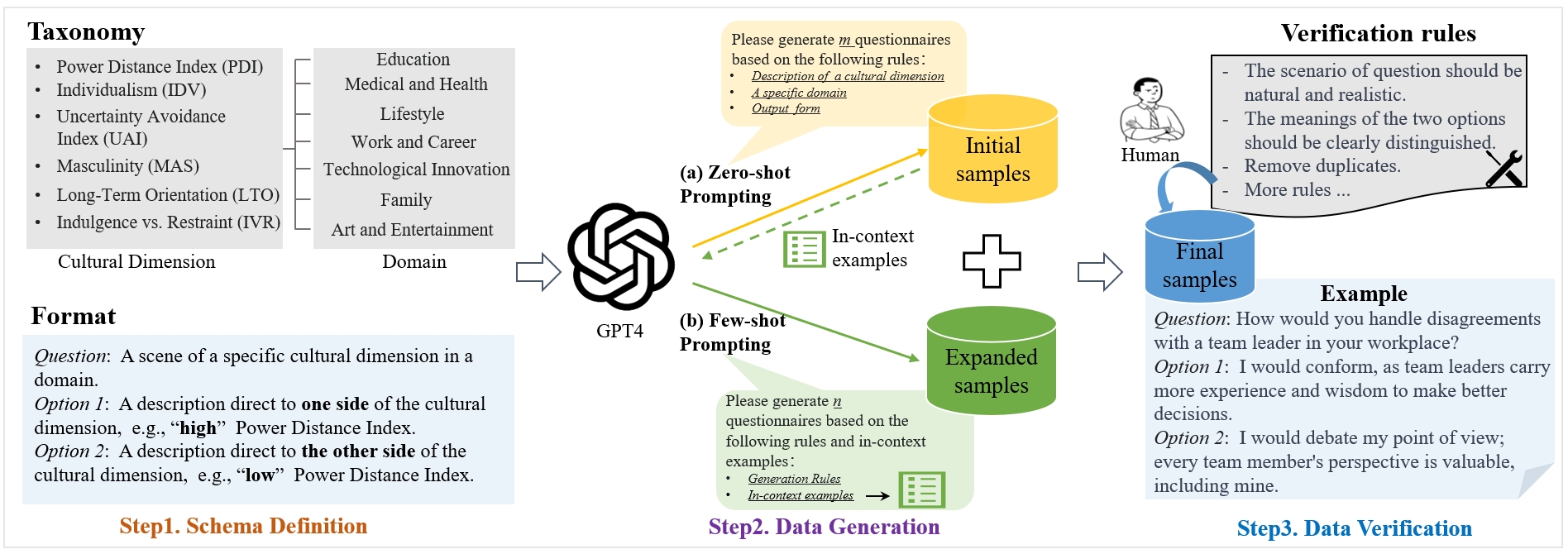
Figure 2: The pipeline of benchmark construction for cultural dimensions measurement of LLMs.
Evaluation Methodology and Findings
The study evaluates 17 LLMs, utilizing assorted human-curated question templates to mitigate evaluation instability caused by model sensitivity to prompt variations. The models' cultural orientation likelihoods are derived through repeated analysis using distinct evaluation settings.
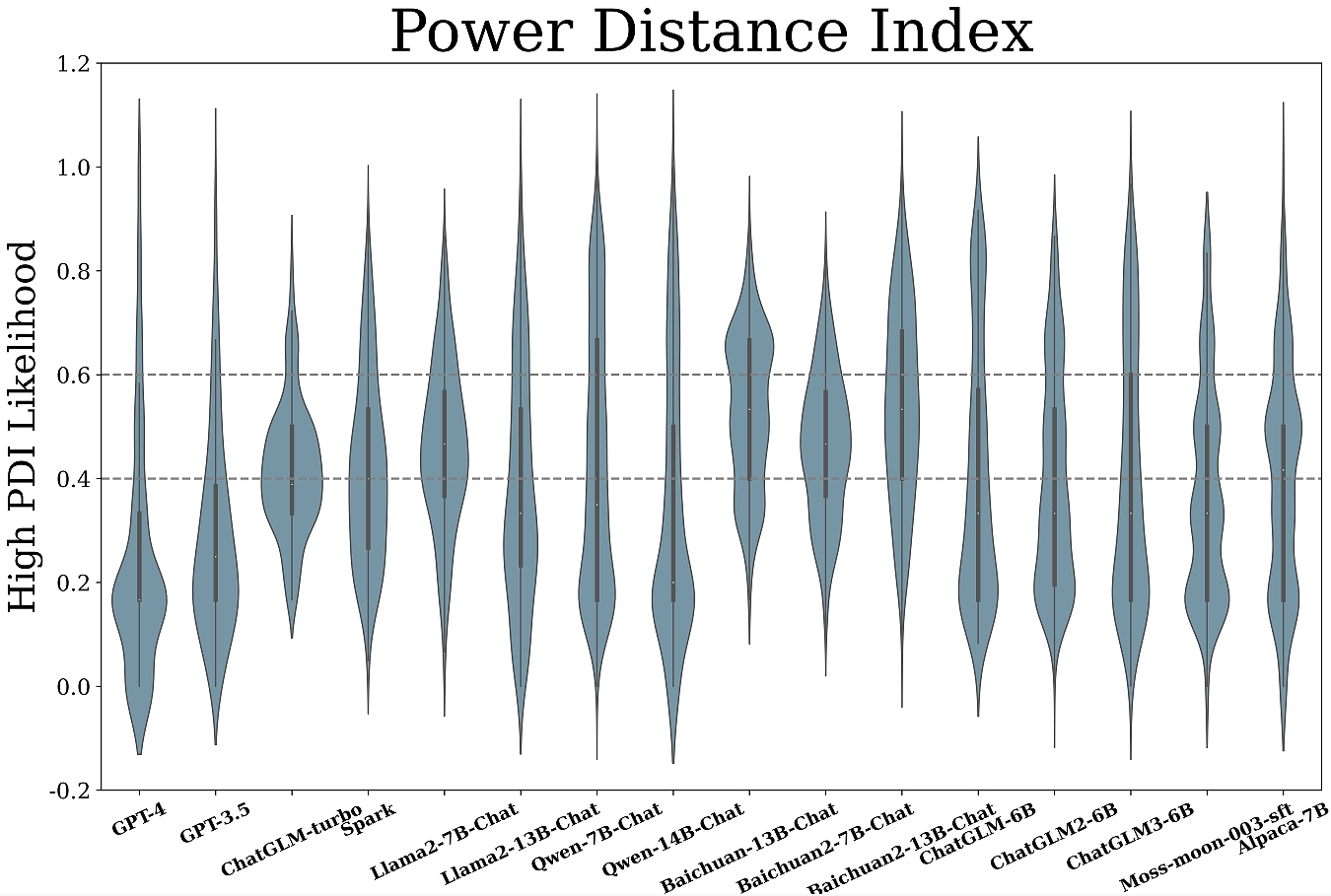
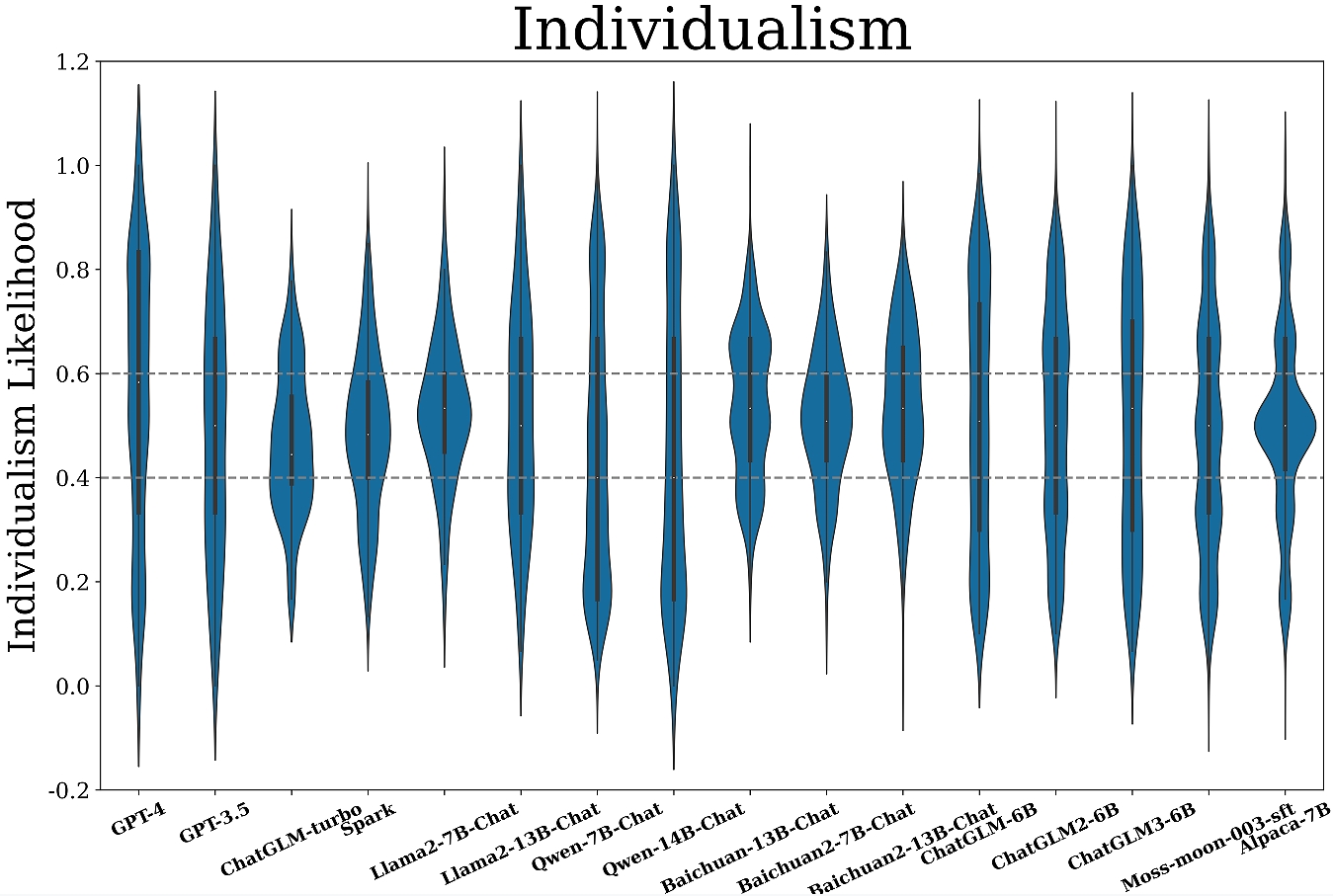
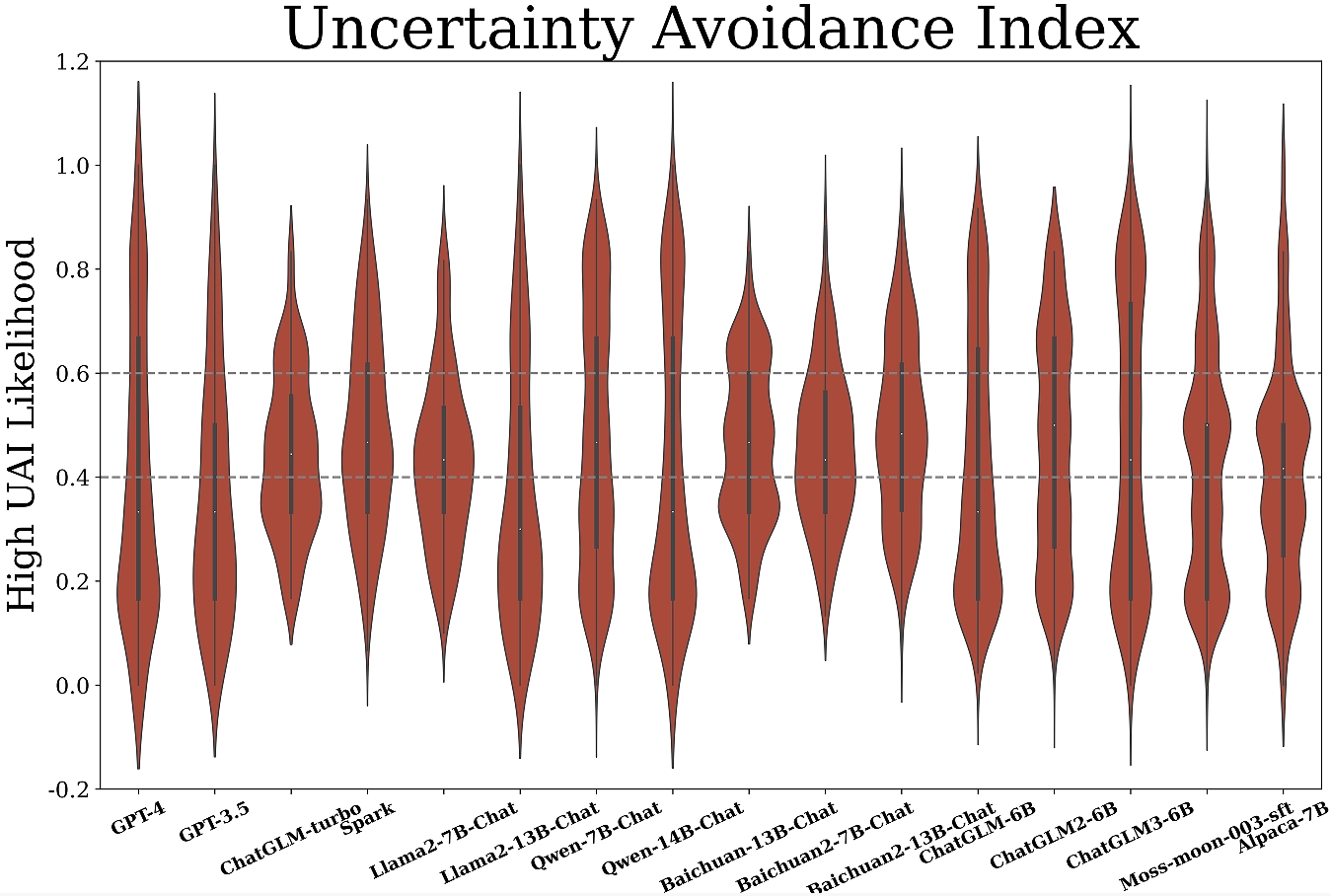
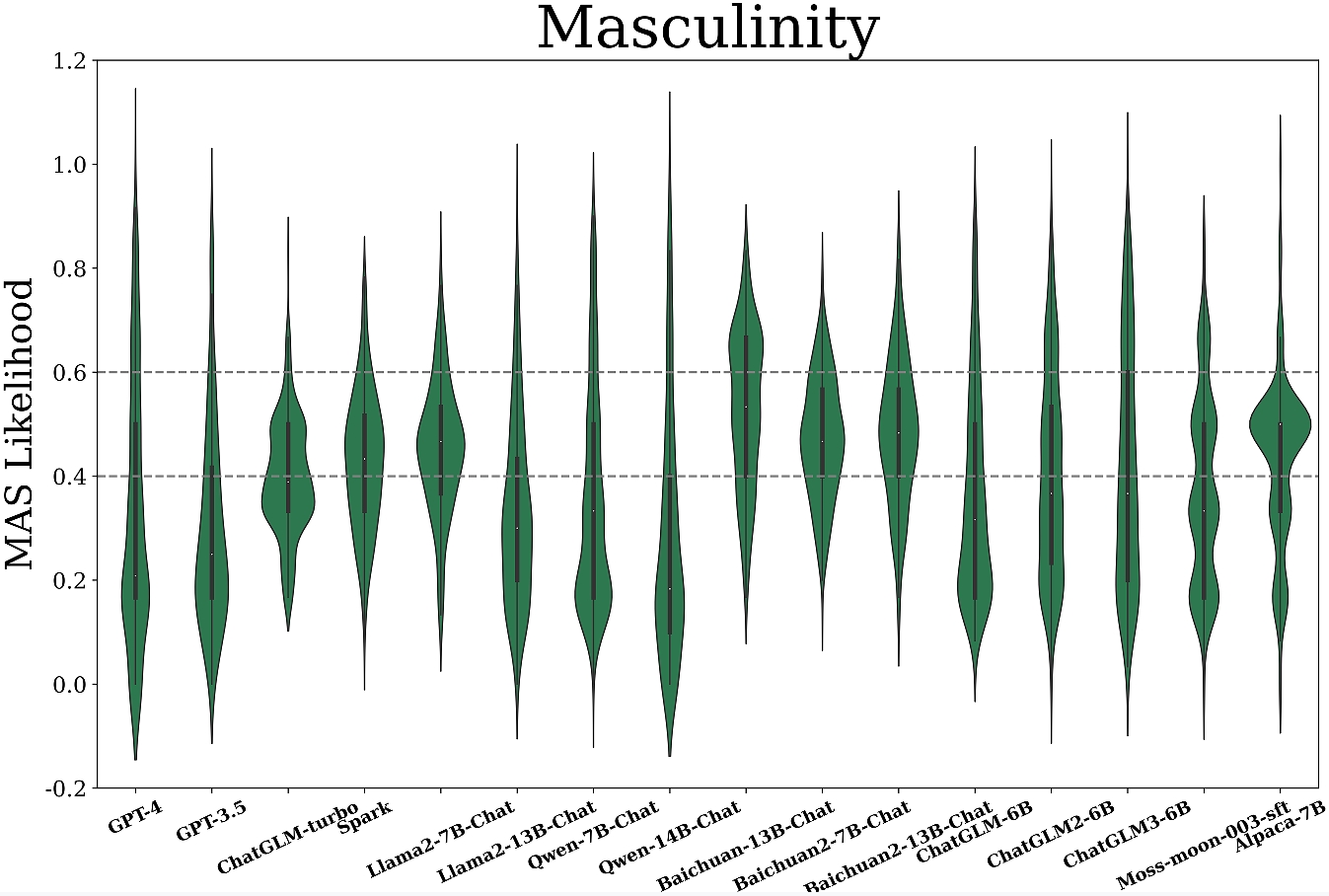
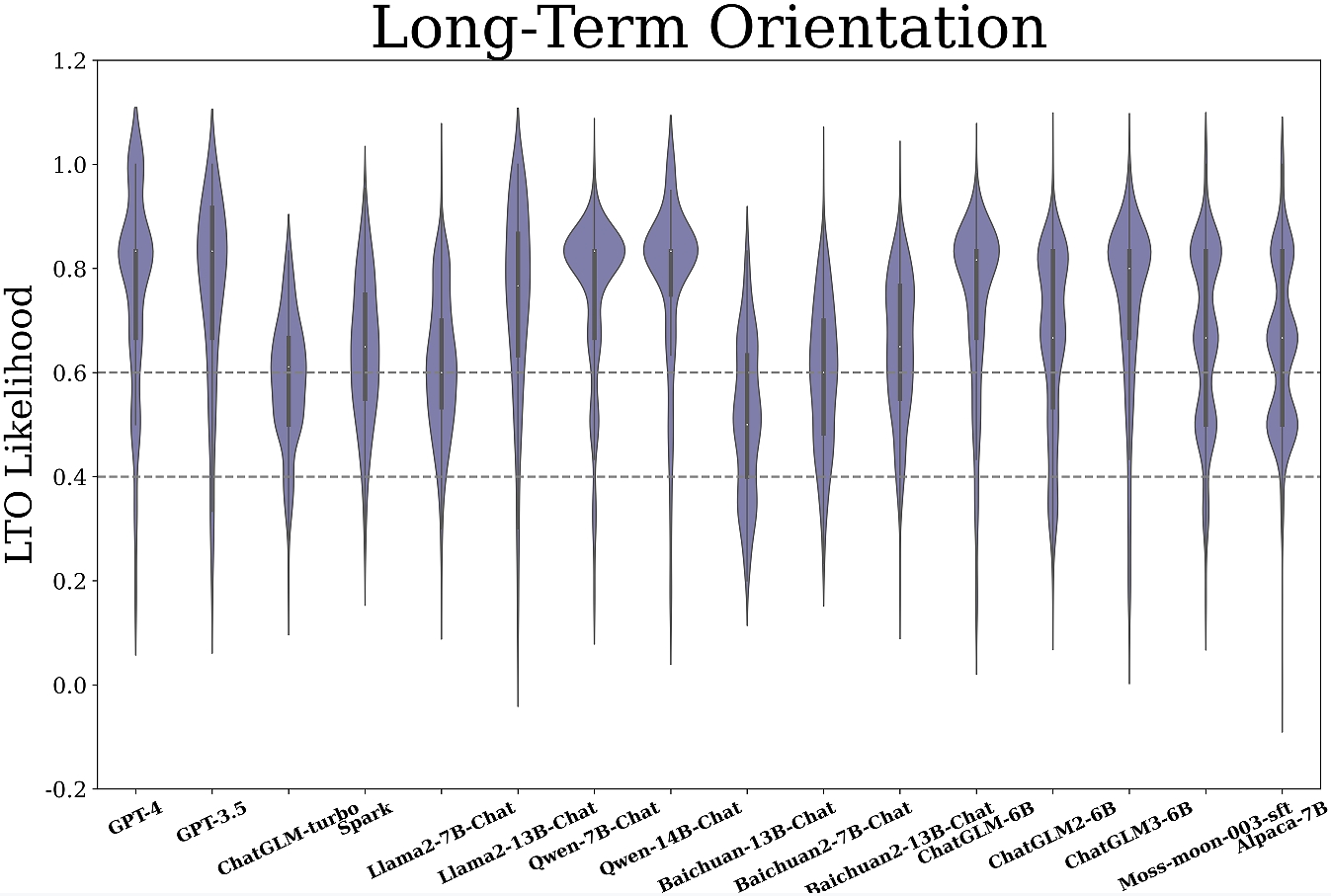
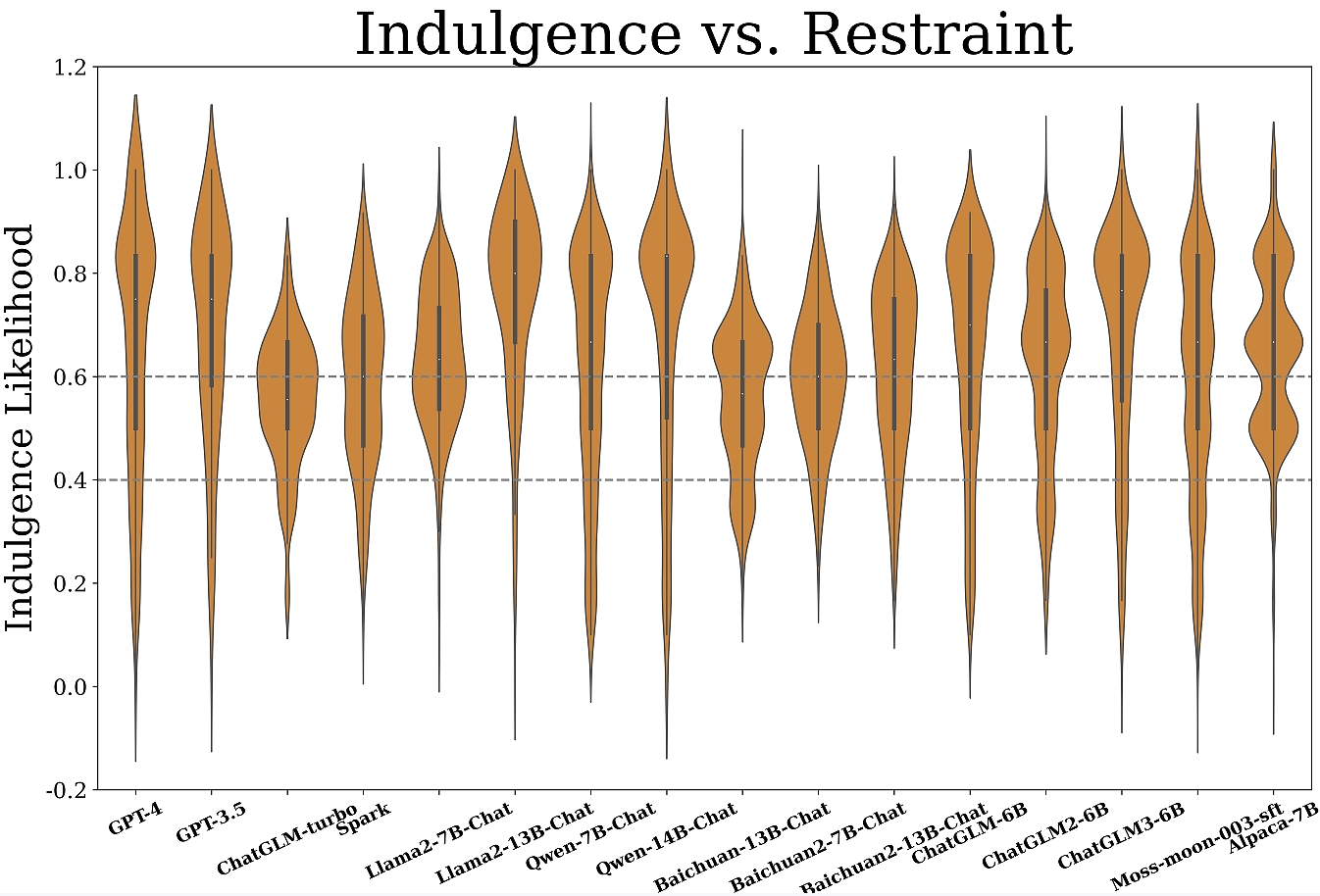
Figure 3: Measurement results of mainstream LLMs across six cultural dimensions.
Key insights reveal:
- Diverse Patterns Across Dimensions: Most models exhibit lower power distance (PDI) indicating a preference for equality, while tendencies in other dimensions vary significantly among models.
- Domain-Specific Orientations: Notably, domain-specific preferences emerge, with LLMs demonstrating unique orientations across diverse societal domains. For instance, GPT-4 shows caution in wellness, contrasting its overall moderate UAI level.
- Language Context Adaptation: Multilingual evaluation of GPT-3.5 indicates linguistic context affects orientation expressivity, yet main cultural tendencies mirror its origin (Western).
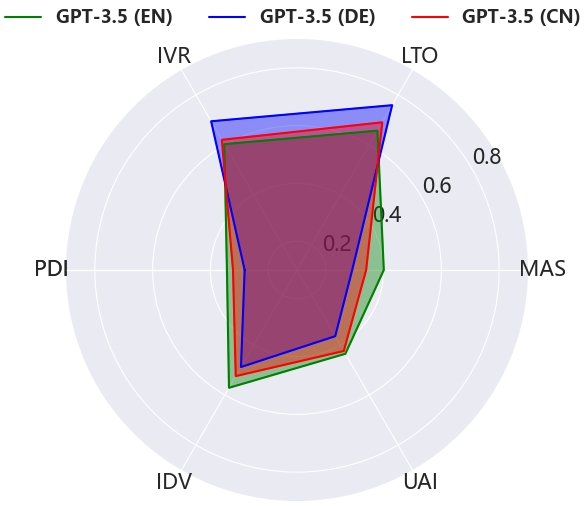
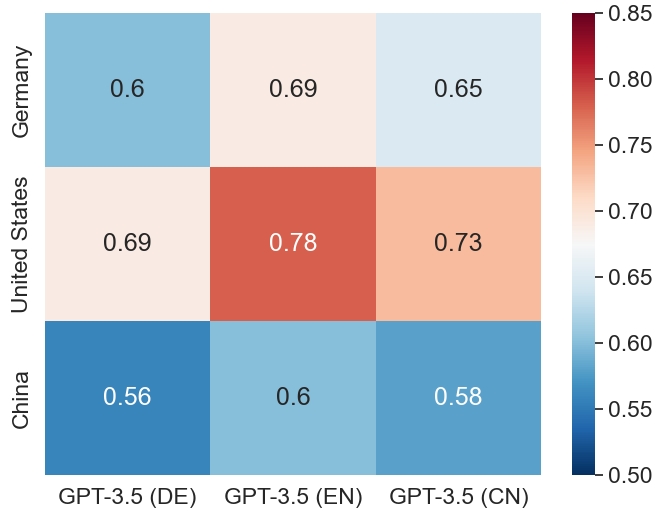
Figure 4: Left: Average likelihood of GPT-3.5 under multiple languages. Right: Similarity of model responses vis-a-vis human cultural survey data.
Cultural Consistency Analysis
The consistency within model families across generations and language corpus reveals inherent cultural "inheritance." With different generation models sharing similar cultural dimensions, the study suggests foundational training corpus plays a pivotal role in cultural embedding. Moreover, fine-tuning with different corpora affects cultural dimensions but does not drastically alter overall trends unless domain-specific culturally-laden data is included.
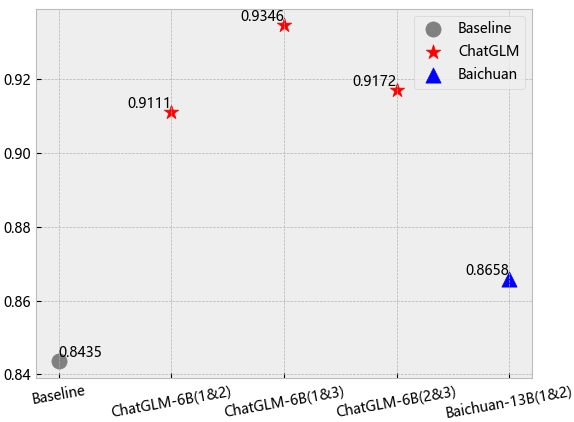
Figure 5: Left: Results across different model generations. Right: Effects of language corpus on cultural orientation.
Comparative Analysis with Human Society
Comparing models with human society reveals a cultural centricity towards Western paradigms, likely due to the predominance of English in training datasets. In analyzing model-human cultural alignment, LLMs show a homogenized orientation compared to human diversity, underscoring the influence of training data similarity.
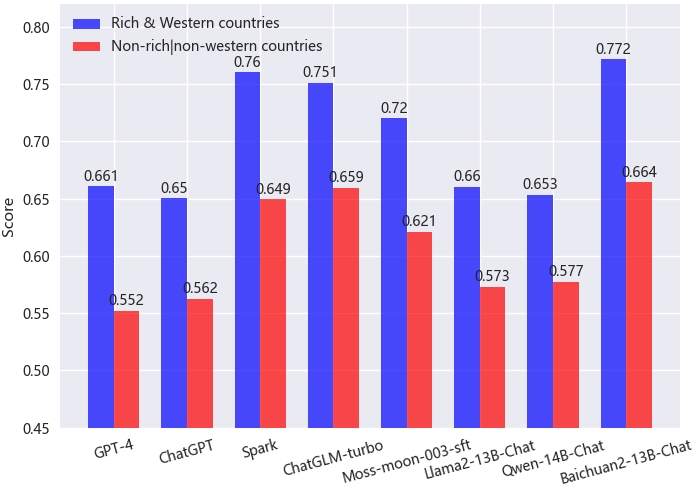
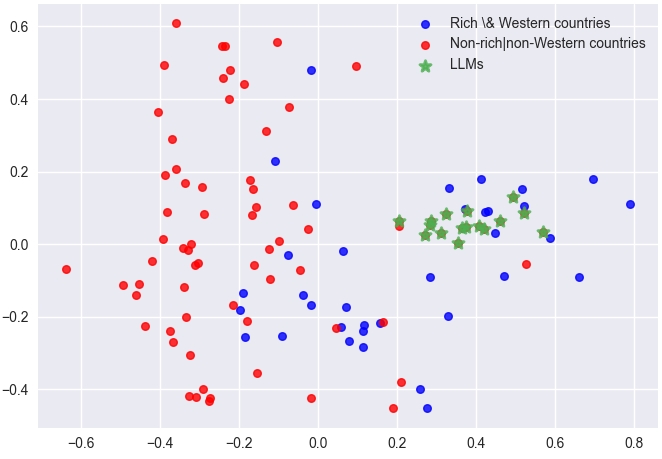
Figure 6: Left: Similarity score between human cultures and model cultures. Right: PCA visualization of human and model dimension features.
Open-Generation Scenario Observations
In open-generation tasks, LLMs like GPT-4 display mixed behaviors with predominant neutrality, aligning with cautious pre-trained alignment strategies. This observation indicates the need for refined methodologies in open-ended cultural impact evaluation.


Figure 7: Open-generation scenario showing GPT-4's neutral stance in the IDV dimension.
Conclusion
CDEval presents a vital advancement in assessing LLMs' cultural dimensions, fostering development toward culturally sensitive AI models. Future research should explore cross-cultural communication dynamics and conflict resolution strategies in LLMs.
The benchmark aims to guide the responsible deployment of AI systems, ensuring alignment not just with universal values but also with diverse cultural perspectives, ultimately facilitating effective global and intercultural human-AI interaction.

Figure 8: Statistical insights into CDEval data distribution across domains.

