Understanding the Effectiveness of Large Language Models in Detecting Security Vulnerabilities
Abstract: While automated vulnerability detection techniques have made promising progress in detecting security vulnerabilities, their scalability and applicability remain challenging. The remarkable performance of LLMs, such as GPT-4 and CodeLlama, on code-related tasks has prompted recent works to explore if LLMs can be used to detect vulnerabilities. In this paper, we perform a more comprehensive study by concurrently examining a higher number of datasets, languages and LLMs, and qualitatively evaluating performance across prompts and vulnerability classes while addressing the shortcomings of existing tools. Concretely, we evaluate the effectiveness of 16 pre-trained LLMs on 5,000 code samples from five diverse security datasets. These balanced datasets encompass both synthetic and real-world projects in Java and C/C++ and cover 25 distinct vulnerability classes. Overall, LLMs across all scales and families show modest effectiveness in detecting vulnerabilities, obtaining an average accuracy of 62.8% and F1 score of 0.71 across datasets. They are significantly better at detecting vulnerabilities only requiring intra-procedural analysis, such as OS Command Injection and NULL Pointer Dereference. Moreover, they report higher accuracies on these vulnerabilities than popular static analysis tools, such as CodeQL. We find that advanced prompting strategies that involve step-by-step analysis significantly improve performance of LLMs on real-world datasets in terms of F1 score (by upto 0.18 on average). Interestingly, we observe that LLMs show promising abilities at performing parts of the analysis correctly, such as identifying vulnerability-related specifications and leveraging natural language information to understand code behavior (e.g., to check if code is sanitized). We expect our insights to guide future work on LLM-augmented vulnerability detection systems.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Practical Applications
Immediate Applications
Below is a curated set of practical use cases that can be deployed now, leveraging the paper’s findings on LLM-based vulnerability detection, explainability, and prompting strategies.
- IDE and code review assistant for CWE-aware, dataflow-driven vulnerability explanations
- Sectors: software, cybersecurity
- Tools/products/workflows: IDE plugin or PR bot that applies the Dataflow analysis-based prompt to provide source–sink–sanitizer reasoning, flags likely CWEs, and suggests mitigations.
- Why now: The paper shows GPT-4 and CodeLlama deliver usable F1 scores on synthetic datasets and produce explainable dataflow traces for many classes (e.g., OS command injection).
- Assumptions/dependencies: Code snippets must fit within context windows; best performance for localized vulnerabilities; cloud LLM use requires code privacy controls (or on-prem models).
- CI/CD pre-commit and pull-request scanning for Top-25 CWEs
- Sectors: software, DevSecOps
- Tools/products/workflows: Pipeline step that runs CWE-specific and Dataflow analysis-based prompts, posts findings as annotations; integrates with GitHub/GitLab.
- Why now: The prompting strategies yield competitive detection and interpretable outputs without needing full project builds.
- Assumptions/dependencies: Token/cost budgeting; rate limits; false positives/negatives must be managed with thresholds and human triage; limited context harms inter-procedural detection.
- Hybrid SAST augmentation (LLM + static analysis) for coverage gaps
- Sectors: cybersecurity tooling
- Tools/products/workflows: Use LLMs to (a) triage static analyzer findings, (b) propose missing sinks/sources/sanitizers (e.g., exec variants), and (c) prioritize high-risk classes (like CWE-78).
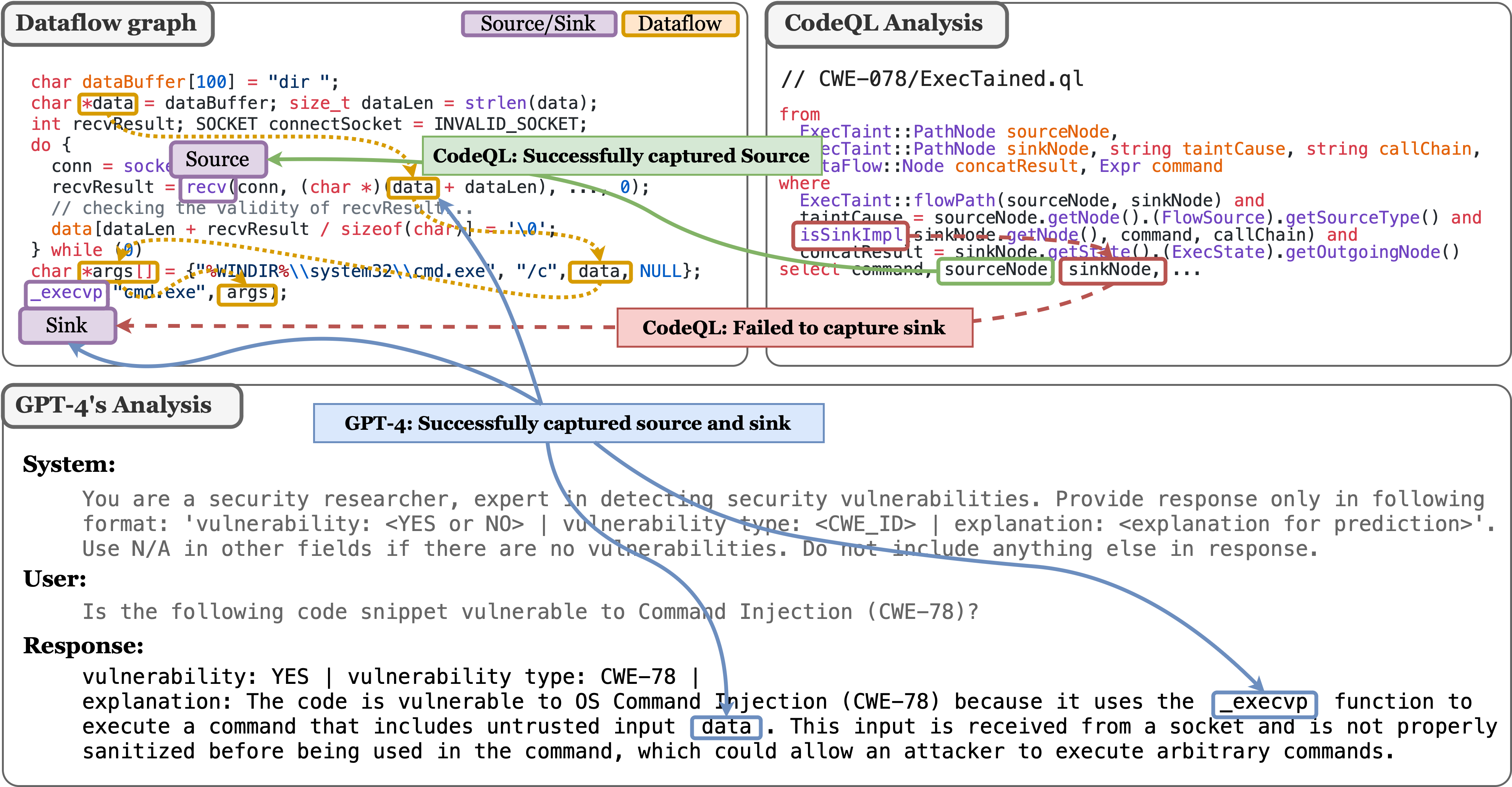
- Why now: Paper shows LLMs caught many OS command injection cases that CodeQL missed due to incomplete sink specifications.
- Assumptions/dependencies: Human-in-the-loop validation; ongoing spec curation; careful handling to avoid new false positives.
- Security documentation and developer guidance generation
- Sectors: software, education
- Tools/products/workflows: Automatically generate human-readable explanations for flagged issues (CWE mapping, dataflow paths), code snippets for sanitization, and secure patterns.
- Why now: LLM explanations are already reliable for many classes and improve developer understanding.
- Assumptions/dependencies: Explanations need review; tailor guidance to organizational code standards and libraries.
- Vulnerability triage for CVE-linked commits in open-source maintenance
- Sectors: open-source, software maintenance
- Tools/products/workflows: Classify diffs by CWE; summarize root cause and recommended fixes; help maintainers quickly assess and respond.
- Why now: LLMs can classify and explain at the method level without full build contexts.
- Assumptions/dependencies: Commit diffs must be clean and representative; caution for complex multi-file changes.
- Targeted scanning of “hard-to-build” or monolithic systems
- Sectors: embedded, energy/ICS, robotics
- Tools/products/workflows: Apply LLM prompts to partial code or components where building or complete analysis is impractical.
- Why now: LLMs do not require compilation and can reason over localized vulnerabilities.
- Assumptions/dependencies: Reduced accuracy for non-local context; need secure deployment (on-premise) in regulated environments.
- Developer training and secure coding coursework
- Sectors: education, workforce development
- Tools/products/workflows: CWEs with example prompts, dataflow-based analyses, and adversarial variations to teach resilience; interactive exercises in courses.
- Why now: The paper provides prompt patterns and measured performance across datasets, enabling immediate curriculum design.
- Assumptions/dependencies: Curate examples; ensure correctness of explanations; integrate assessments.
- Compliance and audit support with explainable findings
- Sectors: finance, healthcare, government
- Tools/products/workflows: Generate CWE-tagged, explainable vulnerability reports for audits and SDLC checkpoints; map findings to policy controls.
- Why now: Explainability makes results defensible and useful for compliance narratives.
- Assumptions/dependencies: Governance for usage of AI outputs; SOPs to reconcile disagreements with traditional tools; privacy controls.
- Bug bounty reconnaissance and triage enhancement
- Sectors: cybersecurity services, bounty programs
- Tools/products/workflows: Use LLM scanners to surface likely CWE-prone areas and produce human-readable exploitable paths for deeper manual verification.
- Why now: Strong detection in certain CWE classes; fast explainability reduces triage overhead.
- Assumptions/dependencies: Legal/ethical constraints; no blind trust in AI outputs; keep human validation.
- Academic experimentation and benchmarking
- Sectors: academia, research
- Tools/products/workflows: Reproduce and extend the paper’s evaluations and prompt variants; measure robustness to adversarial code; compare across languages.
- Why now: Datasets (OWASP, Juliet, CVEFixes) and prompt designs are readily applicable to research setups.
- Assumptions/dependencies: Access to LLMs; careful handling of data leakage and adversarial conditions.
Long-Term Applications
The applications below will benefit from further research, scaling, or productization to reach reliable, inter-procedural, enterprise-grade performance.
- End-to-end hybrid analysis platforms with code-aware retrieval and inter-procedural reasoning
- Sectors: software, cybersecurity tooling
- Tools/products/workflows: Combine LLM dataflow reasoning with static analysis, code indexing/RAG, and symbolic execution to gather non-local context across files and services.
- Why later: Paper shows performance drops on real-world samples due to missing broader context; RAG + analysis is needed for scale.
- Assumptions/dependencies: Scalable code indexing; orchestration of multiple analyzers; cost and latency tuning; robust evaluation.
- Automated API specification generation for static analyzers (source/sink/sanitizer discovery)
- Sectors: cybersecurity tooling
- Tools/products/workflows: “SpecBot” that continuously mines projects/libraries to propose and update CodeQL-like specifications; includes confidence scoring and review workflows.
- Why later: LLMs demonstrated knowledge of missing sinks (e.g., exec variants); turning this into maintainable specs needs verification and governance.
- Assumptions/dependencies: Human curation; reproducible tests; audit trails; integration with rule repositories.
- AI-assisted auto-remediation and patch synthesis validated by tests and analysis
- Sectors: software
- Tools/products/workflows: Generate sanitized code variants; auto-create unit/integration tests; verify with static analysis and fuzzing before merge.
- Why later: Requires high-precision fix generation and multi-tool validation; reduces risk while scaling remediation.
- Assumptions/dependencies: Test generation quality; rollback strategies; performance and correctness regressions monitoring.
- Domain-specific, on-prem LLMs for sensitive codebases
- Sectors: finance, healthcare, defense, critical infrastructure
- Tools/products/workflows: Fine-tuned models for in-house stacks (Java/C/C++/Rust) with hardened privacy/security controls and adversarial robustness features.
- Why later: Paper shows fine-tuning smaller models helps synthetic tasks but generalization is limited; robust enterprise-grade models need curated data and red-teaming.
- Assumptions/dependencies: High-quality domain datasets; strong MLOps; adversarial testing; cost of training/serving.
- LLM-guided fuzzing and driver generation
- Sectors: software, cybersecurity
- Tools/products/workflows: Use LLMs to generate fuzz drivers, seed inputs, and harness code targeting discovered dataflow paths; integrate with coverage-guided fuzzers.
- Why later: Bridges scale limitations of fuzzing with AI-generated drivers informed by vulnerability reasoning.
- Assumptions/dependencies: Stable interfaces to fuzzers; validation of generated harnesses; resource-intensive pipelines.
- Security supply chain risk scoring integrated with SBOMs
- Sectors: software supply chain, policy/compliance
- Tools/products/workflows: LLM-based vulnerability scanning across dependencies; CWE mapping to SBOM artifacts; risk dashboards for procurement and compliance.
- Why later: Needs broad ecosystem data and standardized reporting.
- Assumptions/dependencies: Data freshness; SBOM interoperability; governance and audits.
- Standards and governance for explainable AI SAST
- Sectors: policy, regulators, consortia
- Tools/products/workflows: Guidance on acceptable use, explainability requirements, metrics (precision/recall/F1), and model robustness for vulnerability detection in regulated industries.
- Why later: Multi-stakeholder alignment required; field evidence to inform policy.
- Assumptions/dependencies: Industry buy-in; harmonization with existing secure SDLC standards; independent evaluations.
- Robust adversarial defense and evaluation frameworks for code analysis
- Sectors: academia, cybersecurity
- Tools/products/workflows: Standardized testbeds with dead-code injection, variable renaming, branch manipulation; automated resilience scoring and hardening techniques.
- Why later: Paper shows mild degradation (up to ~12.67% accuracy reduction); formalizing defenses improves trust.
- Assumptions/dependencies: Shared benchmarks; community adoption; continual updates as attacks evolve.
- Cross-language expansion (Python, JavaScript, Rust, Go) and multi-paradigm coverage
- Sectors: software
- Tools/products/workflows: Extend CWE-aware prompts and dataflow reasoning across languages and frameworks; support web, systems, and embedded stacks.
- Why later: Requires language-specific sources/sinks/sanitizers and larger context handling.
- Assumptions/dependencies: Language-specific datasets; tooling integration; generalization across paradigms.
- Interactive education platforms with adversarial code labs
- Sectors: education, workforce development
- Tools/products/workflows: Hands-on labs where learners see how attacks (e.g., dead-code injection) affect detection, and practice improving prompts/analysis.
- Why later: Needs curated content, instrumentation, and grading/autofeedback systems at scale.
- Assumptions/dependencies: Platform development; reliable scoring mechanisms; alignment with industry skills.
Collections
Sign up for free to add this paper to one or more collections.

