Phonetic-aware speaker embedding for far-field speaker verification
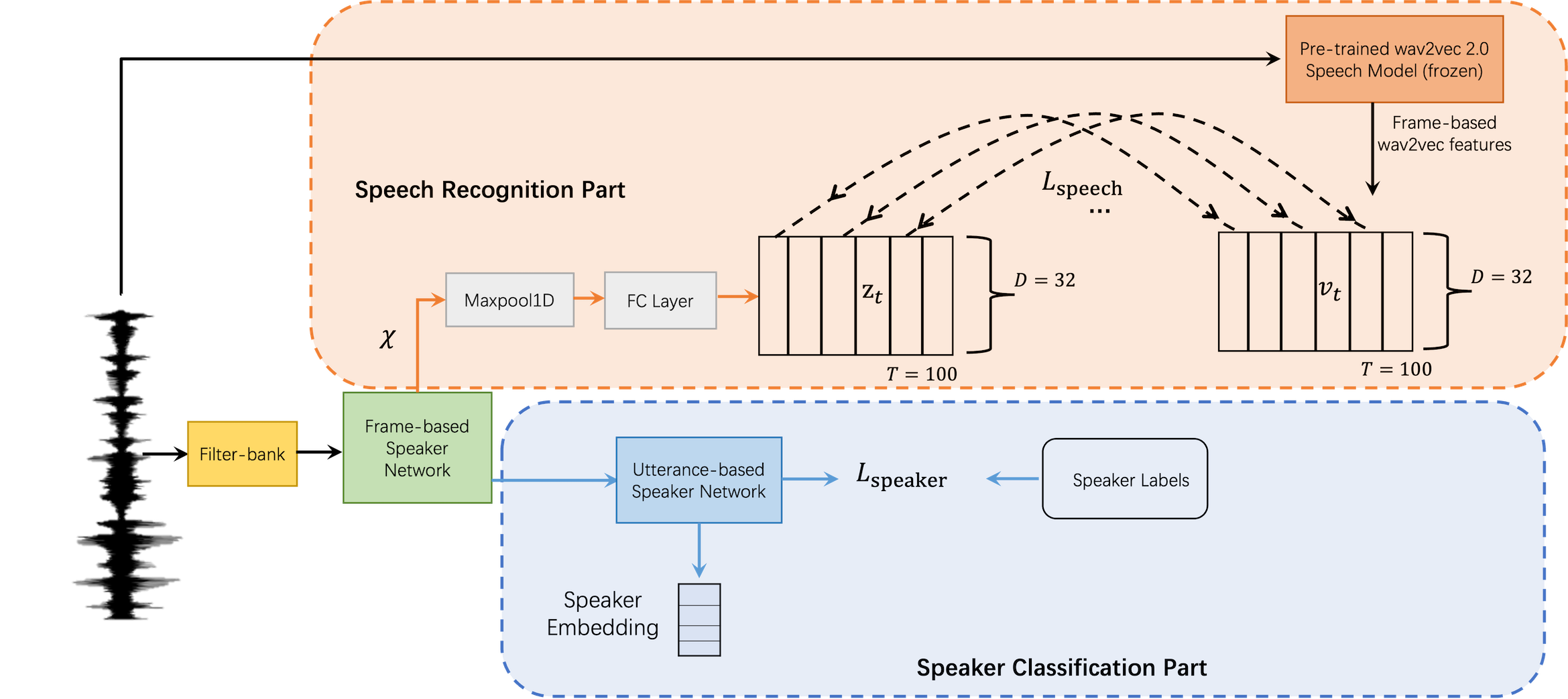
Abstract: When a speaker verification (SV) system operates far from the sound sourced, significant challenges arise due to the interference of noise and reverberation. Studies have shown that incorporating phonetic information into speaker embedding can improve the performance of text-independent SV. Inspired by this observation, we propose a joint-training speech recognition and speaker recognition (JTSS) framework to exploit phonetic content for far-field SV. The framework encourages speaker embeddings to preserve phonetic information by matching the frame-based feature maps of a speaker embedding network with wav2vec's vectors. The intuition is that phonetic information can preserve low-level acoustic dynamics with speaker information and thus partly compensate for the degradation due to noise and reverberation. Results show that the proposed framework outperforms the standard speaker embedding on the VOiCES Challenge 2019 evaluation set and the VoxCeleb1 test set. This indicates that leveraging phonetic information under far-field conditions is effective for learning robust speaker representations.
- “Speaker verification using adapted gaussian mixture models,” Digital Signal Processing, vol. 10, no. 1-3, pp. 19–41, 2000.
- “Front-end factor analysis for speaker verification,” IEEE Transactions on Audio, Speech, and Language Processing, vol. 19, no. 4, pp. 788–798, 2010.
- “Phoneme recognition using time-delay neural networks,” in Backpropagation, pp. 35–61. Psychology Press, 2013.
- “BUT system description to voxceleb speaker recognition challenge 2019,” arXiv preprint arXiv:1910.12592, 2019.
- “ECAPA-TDNN: Emphasized channel attention, propagation and aggregation in TDNN based speaker verification,” in Proc. Interspeech, pp. 3830–3834, 2020.
- “Far-field speaker recognition,” IEEE Transactions on Audio, Speech, and Language Processing, vol. 15, no. 7, pp. 2023–2032, 2007.
- “Channel interdependence enhanced speaker embeddings for far-field speaker verification,” in 12th International Symposium on Chinese Spoken Language Processing (ISCSLP), 2021.
- Lu Yi and Man-Wai Mak, “Adversarial separation and adaptation network for far-field speaker verification.,” in Proc. Interspeech, 2020, pp. 4298–4302.
- “Robust speaker verification using population-based data augmentation,” in ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2022, pp. 7642–7646.
- “Speaker embedding extraction with phonetic information,” arXiv preprint arXiv:1804.04862, 2018.
- “On the usage of phonetic information for text-independent speaker embedding extraction.,” in Proc. Interspeech, 2019, pp. 1148–1152.
- “wav2vec 2.0: A framework for self-supervised learning of speech representations,” Advances in Neural Information Processing Systems, vol. 33, pp. 12449–12460, 2020.
- “Connectionist temporal classification: Labelling unsegmented sequence data with recurrent neural networks,” in Proceedings of the 23rd international conference on Machine learning, 2006, pp. 369–376.
- “Margin matters: Towards more discriminative deep neural network embeddings for speaker recognition,” in Proc. Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), 2019, pp. 1652–1656.
- “Voxceleb: a large-scale speaker identification dataset,” arXiv preprint arXiv:1706.08612, 2017.
- “Voxceleb2: Deep speaker recognition,” arXiv preprint arXiv:1806.05622, 2018.
- “The kaldi speech recognition toolkit,” in Proc. IEEE workshop on automatic speech recognition and understanding, 2011, number CONF.
- “MUSAN: A music, speech, and noise corpus,” arXiv preprint arXiv:1510.08484, 2015.
- “A binaural room impulse response database for the evaluation of dereverberation algorithms,” in Proc. 16th International Conference on Digital Signal Processing, 2009.
- “The voices from a distance challenge 2019 evaluation plan,” arXiv preprint arXiv:1902.10828, 2019.
- “X-vectors: Robust DNN embeddings for speaker recognition,” in Proc. IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2018, pp. 5329–5333.
- “LibriSpeech: An ASR corpus based on public domain audio books,” in Proc. IEEE international conference on Acoustics, Speech and Signal Processing (ICASSP), 2015, pp. 5206–5210.
- “Analysis of score normalization in multilingual speaker recognition.,” in Proc. Interspeech, 2017, pp. 1567–1571.
- “STC speaker recognition systems for the voices from a distance challenge,” 2019.
- “Joint optimization of diffusion probabilistic-based multichannel speech enhancement with far-field speaker verification,” in Proc. IEEE Spoken Language Technology Workshop (SLT), 2023, pp. 428–435.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.