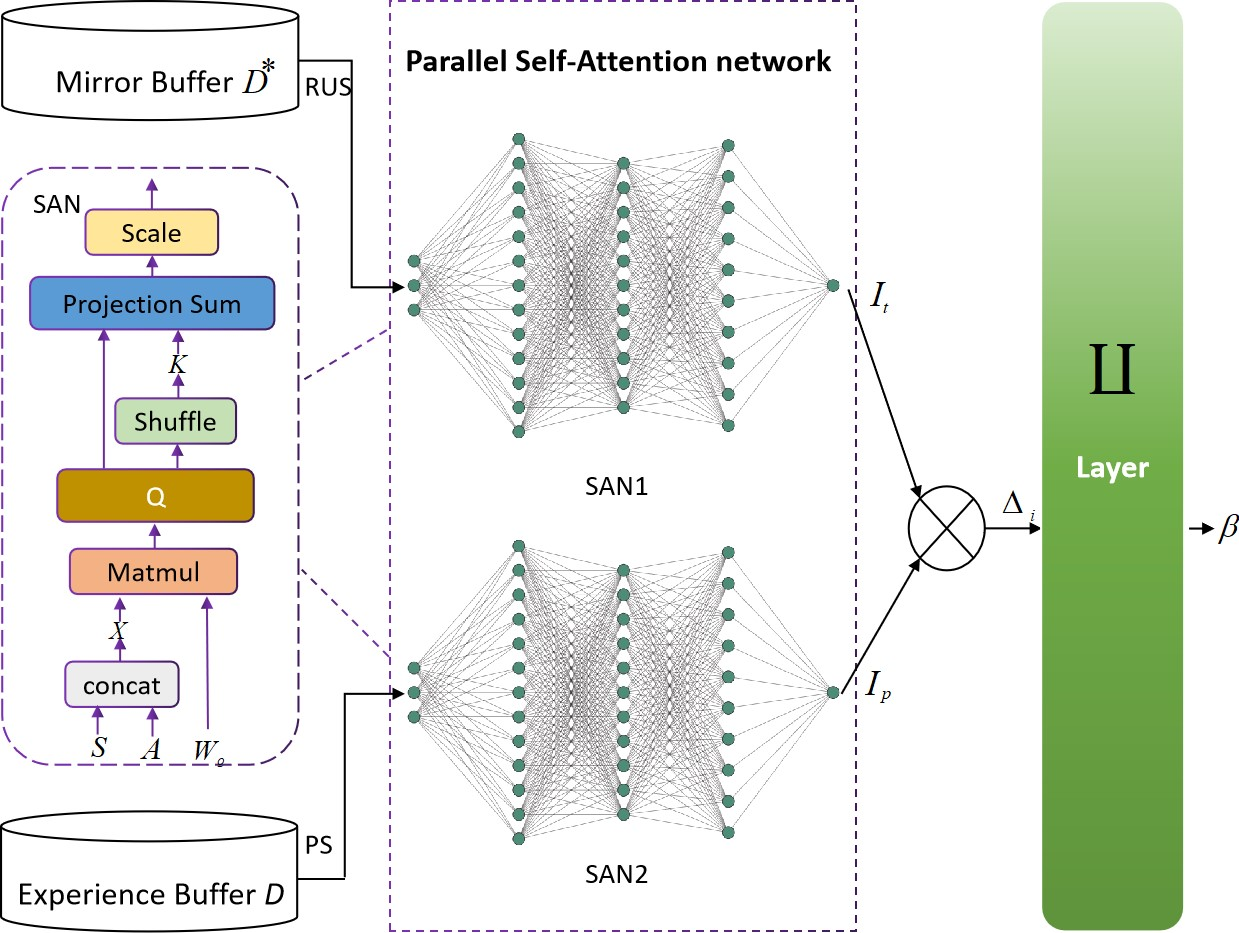
Directly Attention Loss Adjusted Prioritized Experience Replay
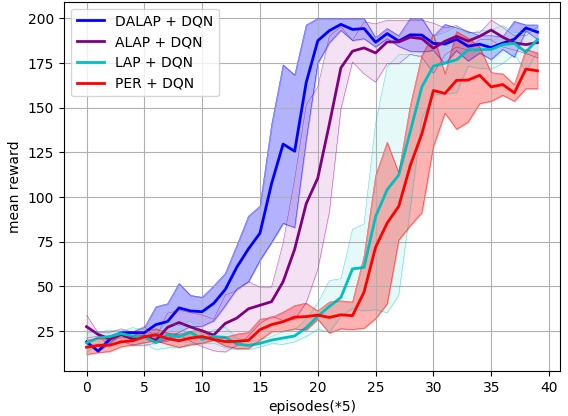
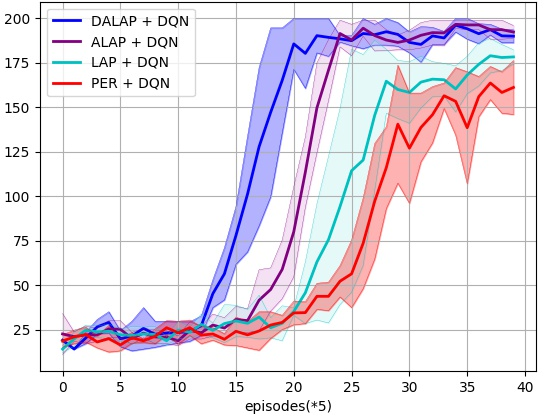
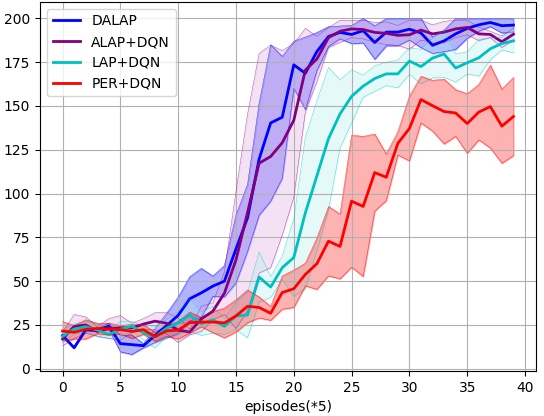
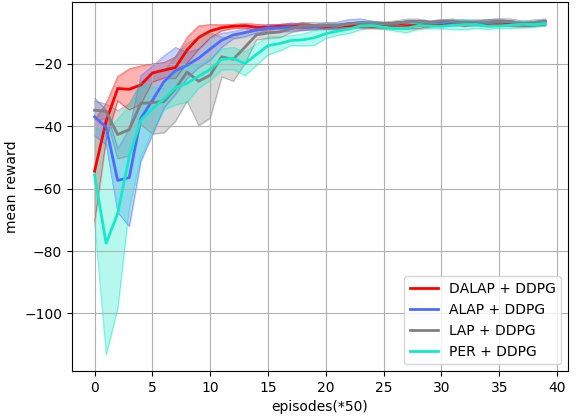
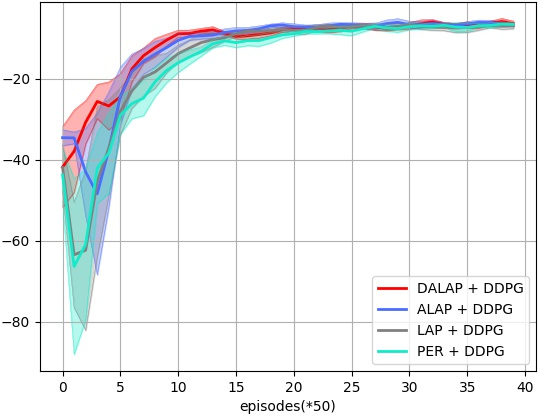
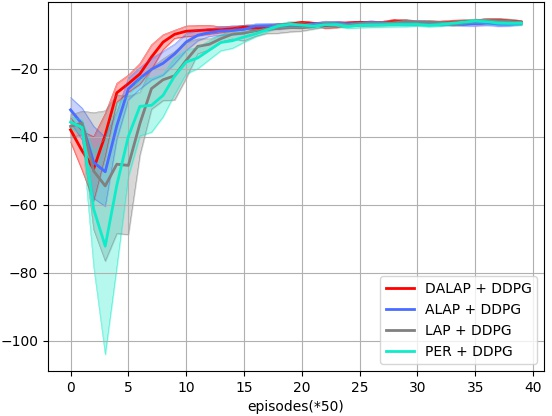
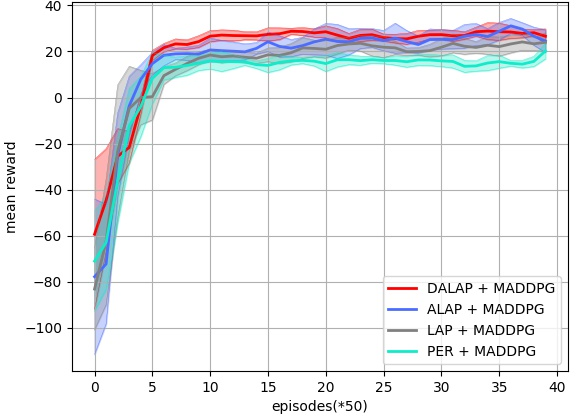
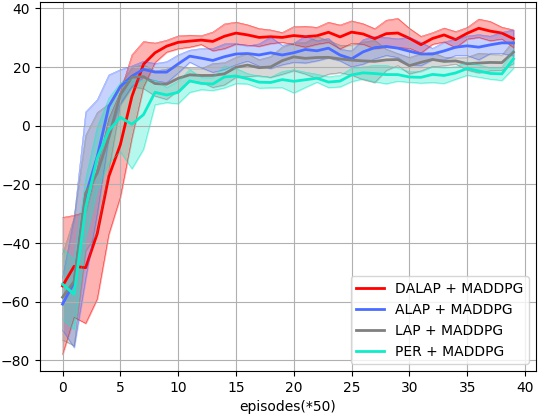
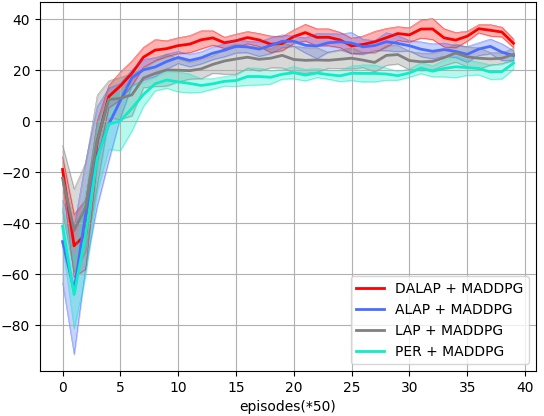
Abstract: Prioritized Experience Replay (PER) enables the model to learn more about relatively important samples by artificially changing their accessed frequencies. However, this non-uniform sampling method shifts the state-action distribution that is originally used to estimate Q-value functions, which brings about the estimation deviation. In this article, an novel off policy reinforcement learning training framework called Directly Attention Loss Adjusted Prioritized Experience Replay (DALAP) is proposed, which can directly quantify the changed extent of the shifted distribution through Parallel Self-Attention network, so as to accurately compensate the error. In addition, a Priority-Encouragement mechanism is designed simultaneously to optimize the sample screening criterion, and further improve the training efficiency. In order to verify the effectiveness and generality of DALAP, we integrate it with the value-function based, the policy-gradient based and multi-agent reinforcement learning algorithm, respectively. The multiple groups of comparative experiments show that DALAP has the significant advantages of both improving the convergence rate and reducing the training variance.
- L. Lin, “Self-improving reactive agents based on reinforcement learning, planning and teaching,” Machine Learning, vol. 8, no. 3, pp. 293–321, 1992.
- T. Schaul, J. Quan, I. Antonoglou, and D. Silver, “Prioritized experience replay,” in International Conference on Learning Representations, 2016.
- F. Bu, D. Chang, “Double prioritized state recycled experience replay,” in IEEE International Conference on Consumer Electronics, pp. 1–6, 2020.
- X. Tao, A. S. Hafid, “DeepSensing: a novel mobile crowdsensing framework with double deep q-network and prioritized experience replay,” IEEE Internet of Things Journal, vol. 7, no. 12, pp. 11547–11558, 2020.
- Y. Yue, B. Kang, “Offline prioritized experience replay,” arXiv:2306.05412, 2023.
- S. Fujimoto, D. Meger, and D. Precup “An equivalence between loss functions and non-uniform sampling in experience replay,” in Proceedings of the 34th International Conference on Neural Information Processing Systems, vol. 33, pp. 14219–14230, 2020.
- B. Saglam, F. B. Mutlu, D. C. Cicek, S. S. Kozat, “Actor prioritized experience replay,” arXiv:2209.00532, 2022.
- Z. Y. Chen, H. P. Li, and R. Z. Wang, “Attention Loss Adjusted Prioritized Experience Replay,” arXiv:2309.06684, 2023.
- J. Gao, X. Li, W. Liu and J. Zhao, “Prioritized experience replay method based on experience reward,” in International Conference on Machine Learning and Intelligent Systems Engineering, pp. 214–219, 2021.
- A. Gruslys, W. Dabney, “The reactor: a fast and sample-efficient actor-critic agent for reinforcement learning,” arXiv:1704.04651, 2017.
- P. Sun, W. Zhou, and H. Li, “Attentive experience replay,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 34, no. 4, pp. 5900–5907, 2020.
- M. Brittain, J. Bertram, X. Yang, and P. Wei, “Prioritized sequence experience replay,” arXiv:2002.12726, 2020.
- V. Mnih, K. Kavukcuoglu, D. Silver, “Human-level control through deep reinforcement learning,” Nature, vol. 518, no. 7540, pp. 529–533, 2015.
- J. Sharma, P. A. Andersen, O. C. Granmo and M. Goodwin, “Deep Q-Learning With Q-Matrix Transfer Learning for Novel Fire Evacuation Environment,” IEEE Transactions on Systems, Man, and Cybernetics: Systems, vol. 51, no. 12, pp. 7363–7381, 2021.
- P. Timothy, J. Hunt, “Continuous control with deep reinforcement learning,” in International Conference on Learning Representations, 2016.
- R. Yang, D. Wang, and J. Qiao, “Policy gradient adaptive critic design with Ddynamic prioritized experience replay for wastewater treatment process control,” IEEE Transactions on Industrial Informatics, vol. 18, no. 5, pp. 3150–3158, 2022.
- R. Lowe, Y. Wu, A. Tamar, J. Harb, O. P. Abbeel, and I. Mordatch, “Multi-agent actor-critic for mixed cooperative-competitive environments,” in Proceedings of the 31th International Conference on Neural Information Processing Systems, pp. 6379–6390, 2017.
- H. Zhang, H. Wang, and Z. Kan, “Exploiting transformer in sparse reward reinforcement learning for interpretable temporal logic motion planning,” IEEE Robotics and Automation Letters, vol. 8, no. 8, pp. 4831-4838, 2023.
- H. Zhao, J. Wu, Z. Li, W. Chen, and Z. Zheng, “Double sparse deep reinforcement learning via multilayer sparse coding and nonconvex regularized pruning,” IEEE Transactions on Cybernetics, vol. 53, no. 2, pp. 765-778, 2023.
- G. Brockman, V. Cheung, L. Pettersson, J. Schneider, J. Schulman, J. Tang, and W. Zaremba“Openai gym,” arXiv:1606.01540, 2016.
- F. Rezazadeh, H. Chergui, L. Alonso, and C. Verikoukis, “Continuous Multi-objective Zero-touch Network Slicing via Twin Delayed DDPG and OpenAI Gym,” in IEEE Global Communications Conference, pp. 1-6, 2020.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.