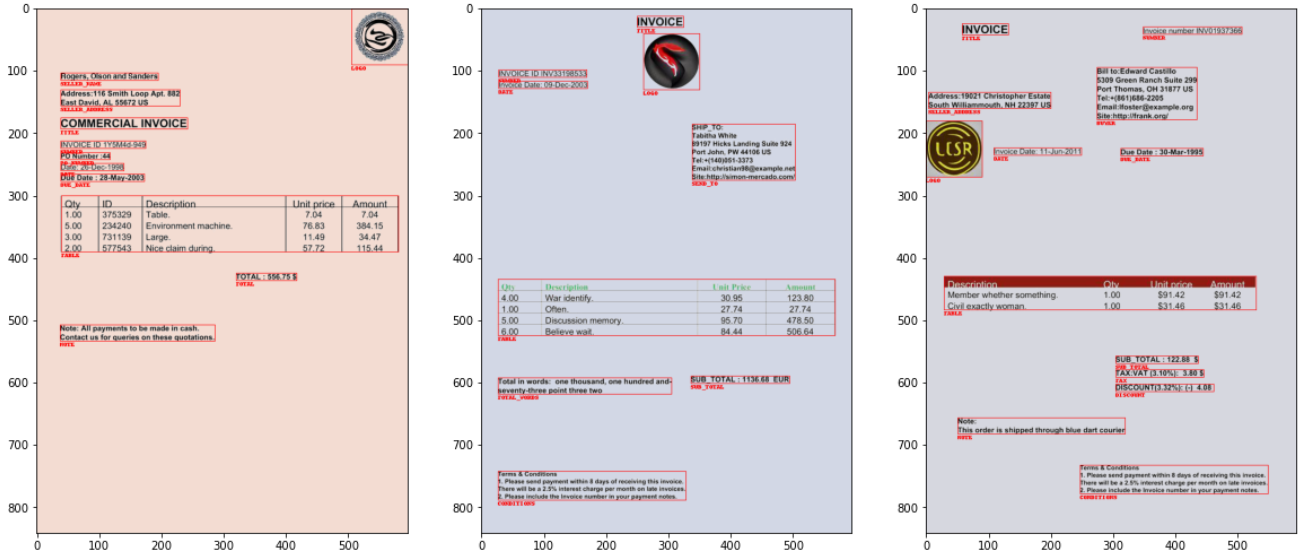
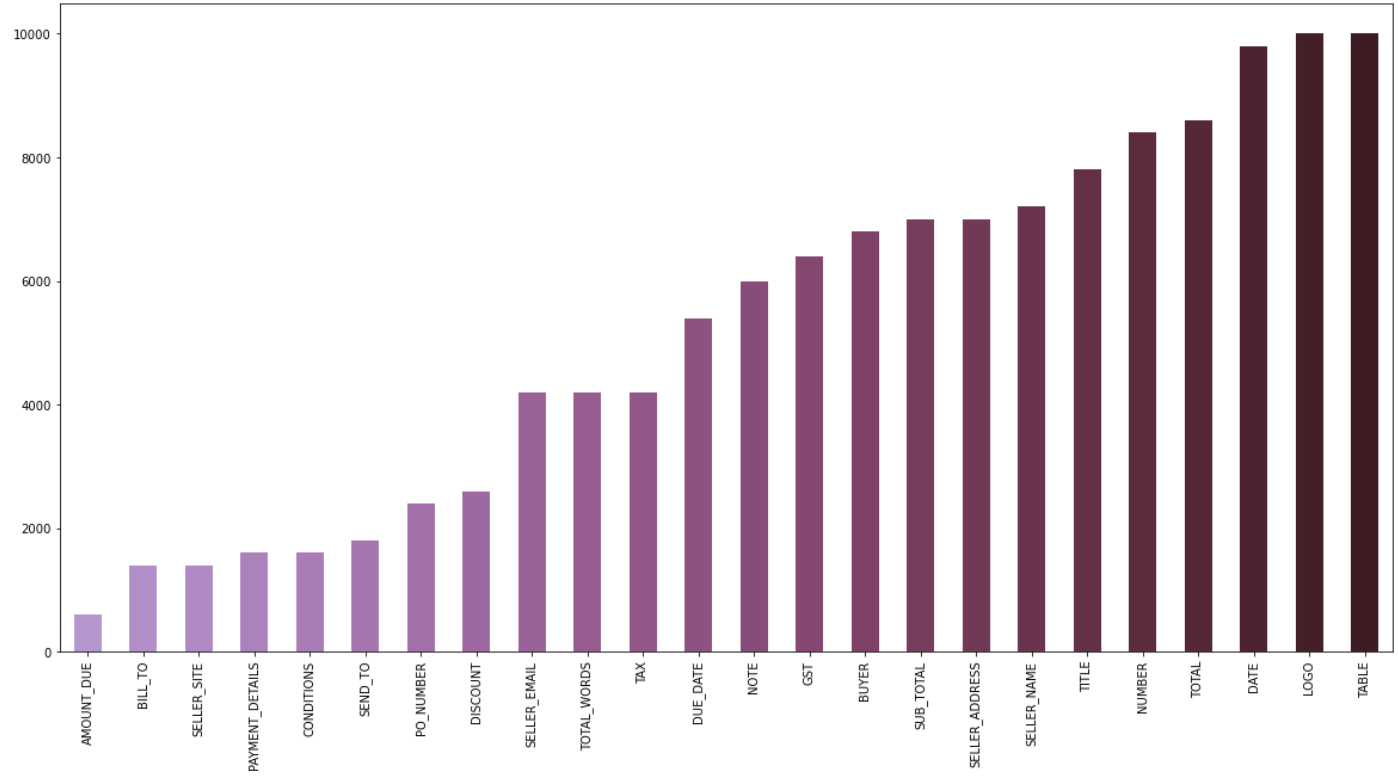
- The paper presents FATURA, a new dataset with 10,000 invoice images featuring 50 distinct layouts for enhanced document analysis.
- It details a comprehensive methodology including multi-format annotations (COCO, LayoutLMv3, and standard) and evaluation strategies across intra- and inter-template settings.
- Experiments with visual (YOLOS), multi-modal (LayoutLMv3), and hybrid approaches demonstrate improved structured data extraction despite OCR and segmentation challenges.
"FATURA: A Multi-Layout Invoice Image Dataset for Document Analysis and Understanding" (2311.11856)
Overview
The paper introduces FATURA, a comprehensive dataset designed as a resource for document analysis and understanding, particularly for invoices. The dataset includes 10,000 invoices with 50 unique layouts, making it the most extensive open invoice image dataset available. Key to document analysis is the need for annotated data that encompasses both text transcription and precise bounding-box annotations, which FATURA provides freely for researchers. Additionally, the paper discusses the development of benchmarks and evaluates various strategies for document understanding tasks utilizing the dataset.
Dataset Construction and Features
FATURA is structured to address the challenges associated with analyzing invoices, such as varying formats and privacy concerns. The dataset generation process involves several steps:
Evaluation Strategies
The paper outlines two evaluation strategies to test model performance using FATURA:
- Intra-Template Evaluation: Models are trained and tested on images from the same templates, exposing them to multiple content variations but familiar layouts.
- Inter-Template Evaluation: Models are trained on certain templates and tested on entirely different ones, evaluating their ability to generalize across various layouts.
Experiments and Results
Several approaches were tested on FATURA:
Visual-Based Approach with YOLOS
YOLOS was used for object detection, showing high performance at recognizing text regions within familiar templates, but struggling with unseen templates due to its focus on layout rather than textual comprehension.
- Intra-Template Success: Demonstrated by high mAP scores on familiar templates.
- Inter-Template Challenge: Performance dropped significantly when models were trained and tested on dissimilar templates.
Multi-Modal Approach with LayoutLMv3
LayoutLMv3 leverages both visual and textual information for a token classification task.
- Employed at the region level to mitigate reliance on precise word-level bounding boxes and OCR errors.
- Exhibited robust classification capabilities across various document structures.
Hybrid Approach
A novel combination of YOLOS and LayoutLMv3 for improved document understanding.
Conclusion
The FATURA dataset addresses existing gaps in document analysis, providing high-quality, diverse invoice data essential for advancing AI models in this domain. The various evaluation strategies and hybrid approaches highlight both the potential and limitations of current models, informing future research directions.
Ongoing efforts to expand this dataset to include multi-lingual invoices will further broaden its utility, presenting opportunities to refine models capable of handling diverse document types across languages. Lastly, while the hybrid approach presents notable improvements, the importance of high-precision OCR and segmentation remains a critical focus for future studies.