- The paper proposes a novel automated method to improve character consistency through iterative identity extraction and clustering in diffusion models.
- It leverages K-MEANS++ on image embeddings and refines LoRA weights to enhance visual identity reliability.
- User studies and quantitative metrics demonstrate significant improvements in consistency, supporting applications in storytelling and image editing.
Summary of "The Chosen One: Consistent Characters in Text-to-Image Diffusion Models"
Introduction
The paper "The Chosen One: Consistent Characters in Text-to-Image Diffusion Models" (2311.10093) addresses the challenge of generating consistent characters using text-to-image diffusion models. High-quality image generation from textual descriptions has made substantial progress recently, yet maintaining visual consistency across different scenes remains unsolved, crucial for applications like story visualization and game development. Unlike conventional methodologies relying on multiple images or manual processes, this paper proposes an automated solution leveraging solely text prompts.
Methodology Overview
The proposed approach iteratively enhances identity consistency through clustering and identity extraction:
- Identity Clustering: Utilizes K-MEANS++ on embedded images obtained from text prompts, selecting the most cohesive cluster which reflects shared semantic characteristics.
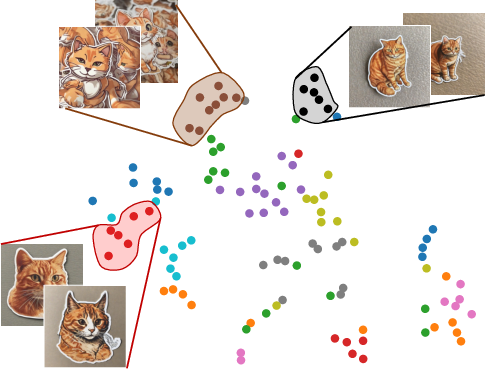
Figure 1: Embedding visualization. Given generated images for the text prompt "a sticker of a ginger cat", different colors indicate distinct clusters with shared characteristics.
- Identity Extraction: Refines character representation by optimizing LoRA weights and text embeddings iteratively, ensuring consistency without overfitting.

Figure 2: Identity consistency. Given the prompt "a Plasticine of a cute baby cat with big eyes", our method consistently produces the same cat across iterations.
The iterative process converges when images generated exhibit a significantly reduced average pairwise Euclidean distance in their semantic embedding space.
Experimental Results
The paper demonstrates superior identity consistency and prompt adherence when compared against notable personalization techniques (e.g., TI, LoRA DB, IP-adapter):
- Quantitative Metrics: Employing automatic evaluation, the method shows balanced performance in identity consistency and prompt similarity relative to existing approaches.








Figure 3: Qualitative comparison to naïve baselines.
- User Studies: Results indicate substantial improvements in perceived consistency, which align with quantitative metrics, validating the effectiveness of the clustering and iterative identity refining process.
Figure 4: Qualitative comparison to baselines.
Applications
The model's applicability spans diverse domains:
- Story Illustrations: Providing consistency in character portrayal through sequential narrative scenes.
- Local Image Editing: Facilitates isolated character alterations within larger compositions through Blended Latent Diffusion integration.









Figure 5: Applications. Our method can be used for various applications, such as illustrating a full story with the same consistent character.
Limitations and Future Directions
Several constraints were identified during experimentation:
- Identity Divergence: Certain configurations may fail to converge fully, reflecting slight character attribute variations.


Figure 6: Limitations. Our method sometimes fails to converge to a fully consistent identity.
- Encompassing Supporting Characters: Generating supplementary character identities alongside primary subjects is non-trivial and requires further exploration.
Potential areas for future development include enhancing computational efficiency and exploring simultaneous multi-subject identity extraction.
Conclusion
The paper successfully introduces a groundbreaking approach to consistent character generation using text-to-image diffusion models. This contribution impacts storytelling and digital media significantly, empowering creators with automated, high-fidelity, consistent character design tools. The solutions address inherent diffusion model variability and enable broad applications in creative, educational, and entertainment domains. While limitations persist, the foundation for future research into robust, automated identity consistency methodologies is firmly established.