- The paper introduces two novel methods—retrieval-based detection and TS-Guessing—to identify overlapping data between training corpora and benchmark datasets.
- The study reports a 57% exact match rate on MMLU using TS-Guessing, highlighting significant contamination risks in benchmark evaluations.
- The paper underscores the need for transparent benchmark construction and improved data handling practices to ensure valid performance assessments of LLMs.
Investigating Data Contamination in Modern Benchmarks for LLMs
Introduction
The paper systematically examines the phenomenon of data contamination within evaluation benchmarks for LLMs. The inflated benchmark scores often seen across various LLMs indicate a potential exposure of these models to benchmark data during their training phase. This situation is exacerbated by the opaque nature of training datasets used in both proprietary and open-source LLMs, raising significant concerns regarding their validity as performance indicators.
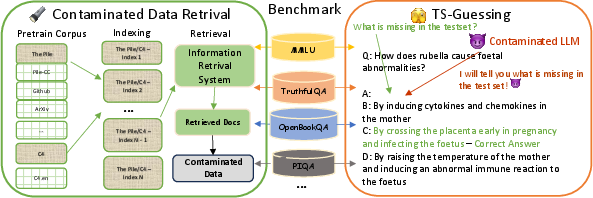
Figure 1: Illustration of our method for identifying data contamination in modern benchmarks, showcasing both the retrieval-based system and TS-Guessing approach.
Methodology
Retrieval-Based Contamination Detection
To identify overlaps between pre-training corpora and benchmark data, the authors establish an IR system leveraging Pyserini, focusing on widely-used pretraining corpora like The Pile and C4. They employ a 13-gram tokenization strategy for chunking documents and calculate the highest similarity scores between these chunks and benchmark data.
Testset Slot Guessing (TS-Guessing)
This novel protocol involves two main settings:
- Question-Based Guessing: Here, the central part of a question is masked, and models predict the missing keyword.
- Question-Multichoice Guessing: In this more challenging task, a wrong multiple-choice option is masked, testing whether the model can guess it accurately.


Figure 2: Illustration of two tasks within TS-Guessing, depicting question templates and hint utilization.
Results
Detection of Contamination
The paper reports significant instances of data contamination especially within the MMLU and TruthfulQA benchmarks. Notably, the TS-Guessing protocol yields a 57% exact match rate for GPT-4 on MMLU, suggesting substantial overlap between benchmark data and training corpora. The findings indicate that benchmark data previously considered isolated might inadvertently be part of model training sets, significantly skewing evaluation metrics.
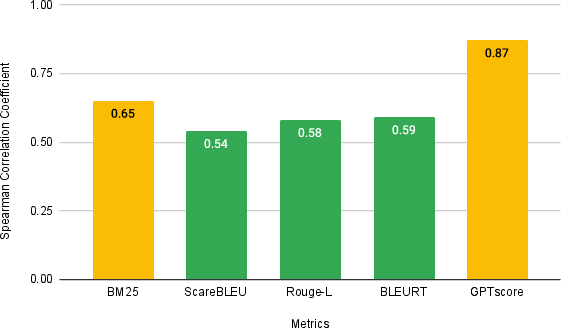
Figure 3: Spearman correlations between text generation quality and human evaluation scores across multiple examples.
Discussion
The research highlights the need for new methodologies in detecting and mitigating data contamination. While retrieval systems demand full access to training corpora, the model-agnostic TS-Guessing can evaluate both open and closed-source models. However, the latter's dependency on the LLM's ability to follow instructions might limit its applicability across different contexts.
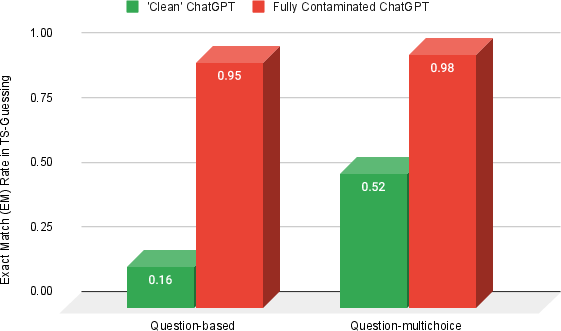
Figure 4: Contaminated Experiment Conducted on MMLU in ChatGPT, demonstrating near 100% EM rate after fine-tuning with MMLU test set, showing our method's sensitivity.
The study underscores the risk of relying on potentially contaminated benchmarks, especially when these data sets are publicly available. This exposure could artificially inflate LLM performance figures, leading to incorrect assumptions about model capabilities.
Conclusion
The paper contributes two significant methodologies for detecting data contamination, emphasizing the pressing need for transparent and robust benchmark construction. Future research could refine these approaches, particularly the TS-Guessing protocol, to develop more sophisticated contamination detection algorithms, ultimately fostering a more accurate assessment landscape for LLMs.

Figure 5: Evident Data contamination example in the TruthfulQA benchmark with overlap with C4 corpus, highlighting training exposure risk.
Implications
Enhancing benchmark transparency and reducing contamination risk will be crucial for future LLM developments. These findings call for better documentation and data handling practices to ensure that task benchmarks truly reflect the intended isolation from training corpora, ensuring integrity and reliability in LLM evaluations.