- The paper introduces a novel evaluation framework assessing LLMs' temporal grounding using benchmarks like McTACO, CaTeRS, and TempEvalQA-Bi.
- Results show that models, including GPT-4, perform significantly below human levels and specialized models in temporal commonsense and event ordering.
- The study suggests that addressing these limitations requires revised training paradigms incorporating real-world event sequences and enhanced temporal reasoning.
Are LLMs Temporally Grounded?
Understanding how LLMs handle temporal information is vital for ensuring their effectiveness in tasks involving narratives and events. Recent explorations into LLMs' grounding abilities suggest significant limitations in their temporal reasoning capacity when compared to humans and smaller, specialized models. This essay examines these deficiencies and the implications for future AI development.
Evaluation Framework
To assess temporal grounding in LLMs, this study introduced a framework targeting three key abilities: commonsense knowledge about events, event ordering, and the satisfaction of temporal constraints ensuring self-consistency. The evaluation utilized benchmarks like McTACO for commonsense reasoning, CaTeRS for event ordering, and a curated TempEvalQA-Bi dataset for testing self-consistency in timelines.
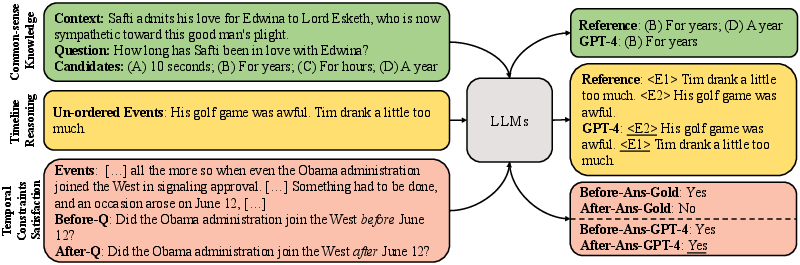
Figure 1: Examples from three datasets to evaluate the temporal grounding of LLMs based on common-sense knowledge about events, timeline reasoning, and temporal constraints satisfaction.
Benchmark Evaluation
Commonsense Knowledge
Results from the McTACO benchmark indicate that current LLMs, such as GPT-4, lag significantly behind human performance. Even with few-shot or chain-of-thought prompting, these models struggle to achieve high accuracy in typical temporal commonsense questions, like durations and typical times for events.
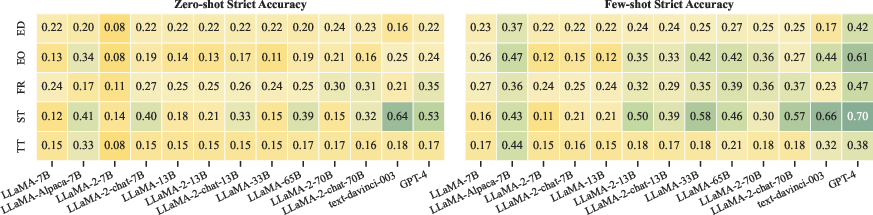
Figure 2: Strict accuracy of all tested LLMs for different reasoning categories in McTACO.
Event Ordering
The CaTeRS benchmark revealed that state-of-the-art LLMs fall short in arranging events chronologically, despite recent advances in models and prompting techniques. The performance of LLMs often did not exceed that of specialized models like TemporalBART, indicating a potential specialization gap.
Temporal Constraints and Self-consistency
When tasked with maintaining consistency in temporal relations, LLM predictions often lacked coherence, as shown in TempEvalQA-Bi results. Even GPT-4, while more capable than others, exhibited inconsistent temporal reasoning, particularly in scenarios requiring the flipping of temporal statements.
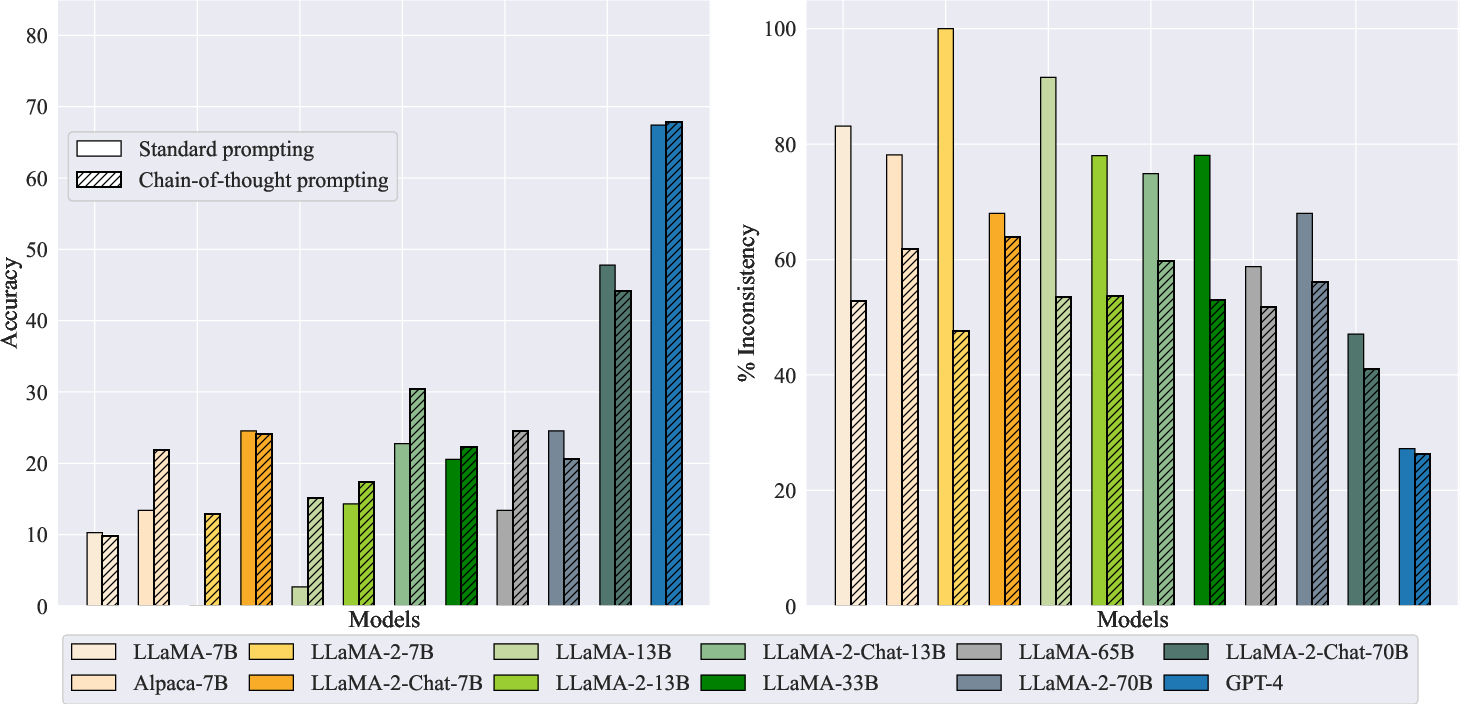
Figure 3: Accuracy (higher is better) and percentage of inconsistent reasoning (lower is better) on TempEvalQA-Bi for LLMs prompted with a chain of thoughts or not.
Factors Affecting Temporal Grounding
Pre-training and Instruction Tuning
The study highlighted a deficiency of temporal information in LLM pre-training datasets. Sentence ordering in such datasets does not strongly correlate with event ordering, limiting LLMs' ability to infer temporal logic naturally. Additionally, instruction-tuning mixtures seldom include tasks specific to temporal reasoning, further restricting models' ability to learn such skills effectively.
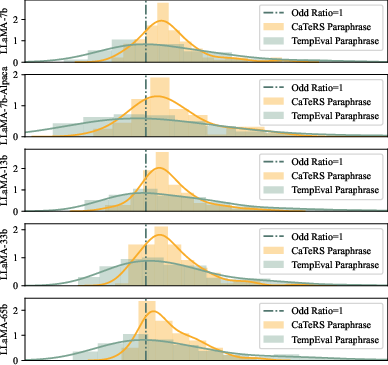
Figure 4: Density plot of the odds ratio under several LLMs for ordered and permuted event paraphrases.
Scaling Models and Examples
Scaling up model parameters or few-shot examples did not consistently enhance performance, suggesting that mere increases in model size do not equate to better temporal grounding. This finding challenges the notion that larger models inherently offer more intelligence in complex reasoning tasks without adequate specialized training.
Implications and Future Directions
The persistent limitations observed in LLMs highlight the importance of revising training paradigms to incorporate a more grounded approach, possibly involving interaction with both simulated and real-world environments. Enhancing perception and action capabilities might offer richer temporal understanding, enabling models to simulate and predict event sequences more reliably.
Conclusion
This research underscores the gaps in temporal grounding among LLMs, particularly in maintaining coherence and reasoning about temporal sequences. Addressing these gaps requires innovate training strategies that emphasize grounded learning, enabling LLMs to perform more reliably and align more closely with human-like reasoning.