- The paper presents a comprehensive review of LLM applications in genomics, emphasizing transformer-based models for capturing long-range dependencies.
- It details pre-training and fine-tuning strategies, including the use of Masked Language Modeling and hybrid architectures like Enformer for improved predictions.
- The review explores emerging alternative models beyond transformers, addressing computational challenges and proposing future research directions in genomic analysis.
Introduction
The paper provides a comprehensive review of how LLMs, predominantly based on transformer architectures, are applied in genomics. Building on a foundation historically set by convolutional neural networks (CNNs) and recurrent neural networks (RNNs), transformers have offered a new paradigm due to their superior ability to model long-range dependencies within genomic data. This document assesses existing architectures and posits future directions beyond the conventional transformer structure.
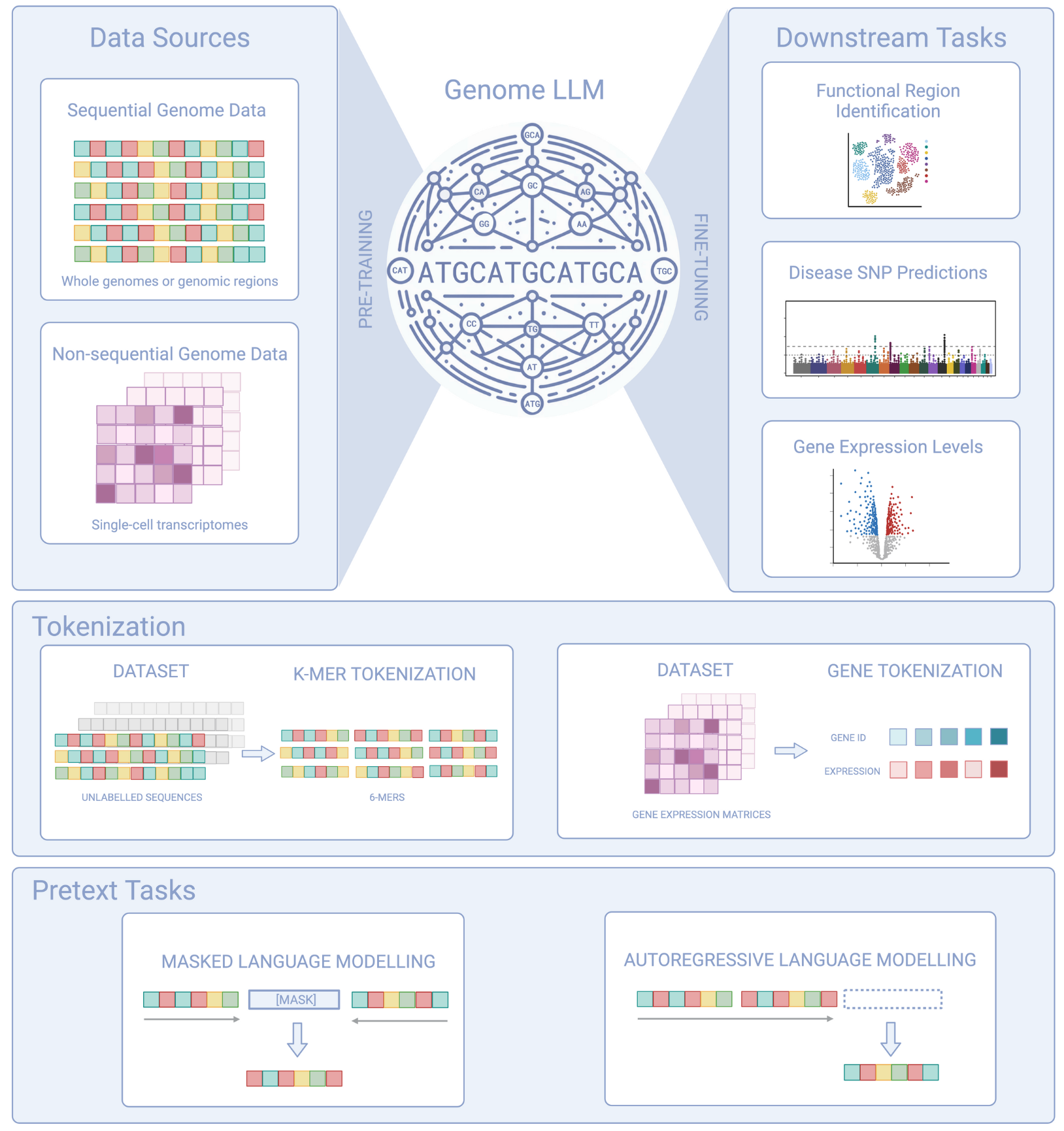
Figure 1: A big picture look at the power of Genome LLMs, illustrating their capacity to process sequential and non-sequential genomic data.
Multi-head Attention Mechanism
Transformers leverage self-attention and multi-head attention mechanisms to capture dependencies across all positions in a given sequence. This mechanism is crucial for genomic sequences, allowing models to consider long-range genomic interactions that span large genomic regions, potentially improving predictions of regulatory regions or SNP functionality.
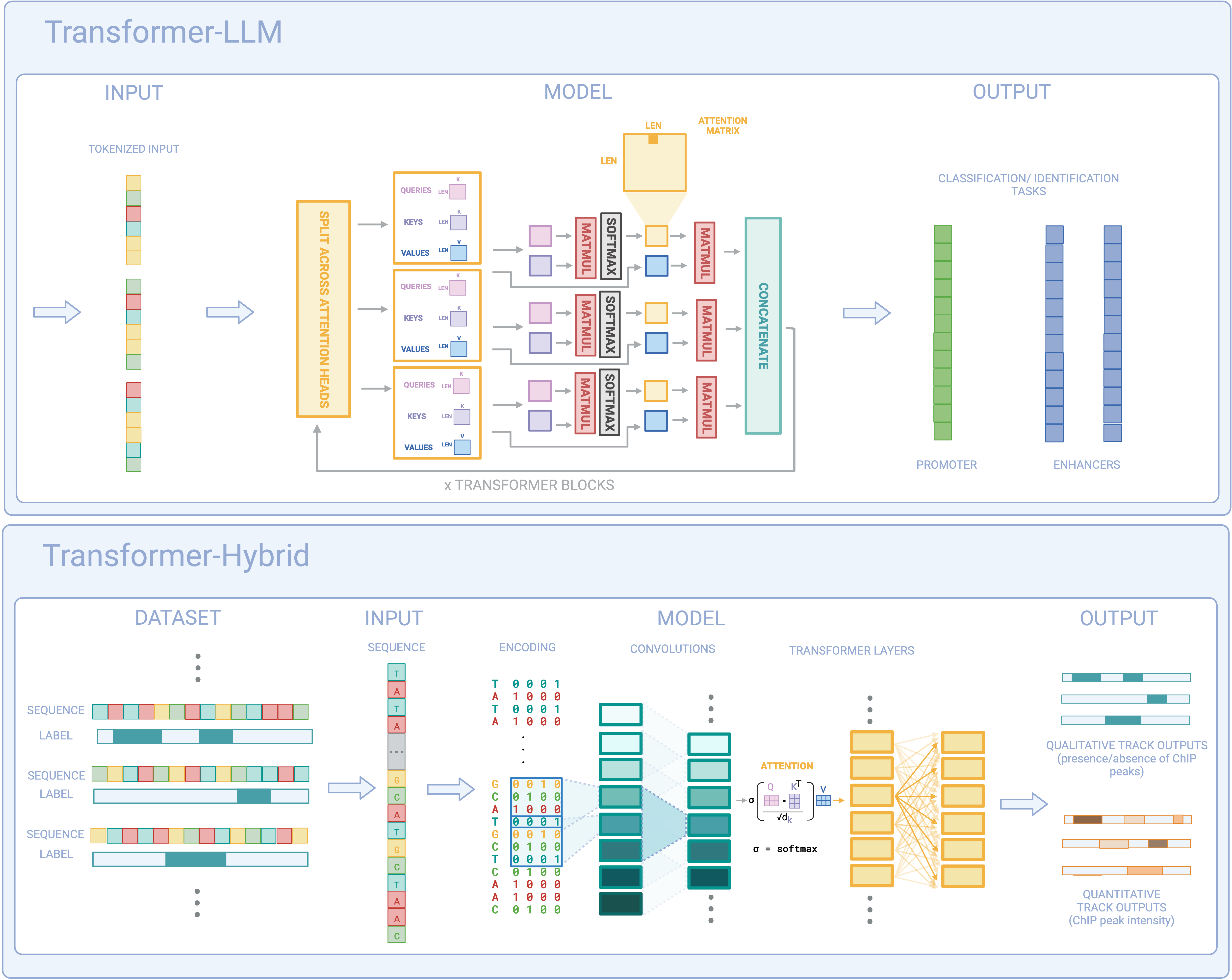
Figure 2: Transformer-LLMs and Transformer-Hybrids showcasing k-merized data handling through the attention mechanism.
Pre-training and Fine-tuning
A significant advantage of transformers in genomics is their ability to undergo unsupervised pre-training. This involves using large amounts of unlabelled genomic data to capture patterns and representations, subsequently fine-tuned on specific tasks like predicting transcription factor binding sites or promoter regions. Techniques such as Masked Language Modelling (MLM) typically dominate this space, providing models with the ability to understand genomic contexts effectively.
Enformer and related models act as hybrids. They utilize initial CNN layers to condense information before passing it to transformers. These models have demonstrated superior performance in predicting genomic assay outcomes by optimizing the balance between convolutional and attention layers, thereby enhancing context windows without overwhelming computational resources.
Alternative Architectures
The paper discusses emerging architectures designed to surpass transformers, such as HyenaDNA, which eschews the attention mechanism in favor of long convolutions and data-dependent gating. This approach aims to maintain the benefits of LLMs while bypassing the quadratic complexity inherent in attention mechanisms.
LLMs for Non-sequential Data
Models like Geneformer and scGPT represent a shift toward using LLMs for non-sequential single-cell data. By employing innovative tokenization and training regimes adapted from NLP, these models redefine how single-cell transcriptomics data is processed, with tasks ranging from gene expression predictions to multi-omic integrations.
Limitations and Future Directions
Long-Range Dependencies
While transformers excel at capturing long-range interactions, there remain limitations tied to context size and computational demands. Although models like Borzoi have extended context windows, the field continues to explore techniques to more effectively capture extensive genomic dependencies.
Interpretability and Computation
The inherent complexity and large scale of current LLM architectures in genomics pose challenges in interpretability and computational feasibility. Techniques such as Layer-Wise Relevance Propagation (LRP) and novel masking techniques are suggested for future exploration to tackle these limitations.
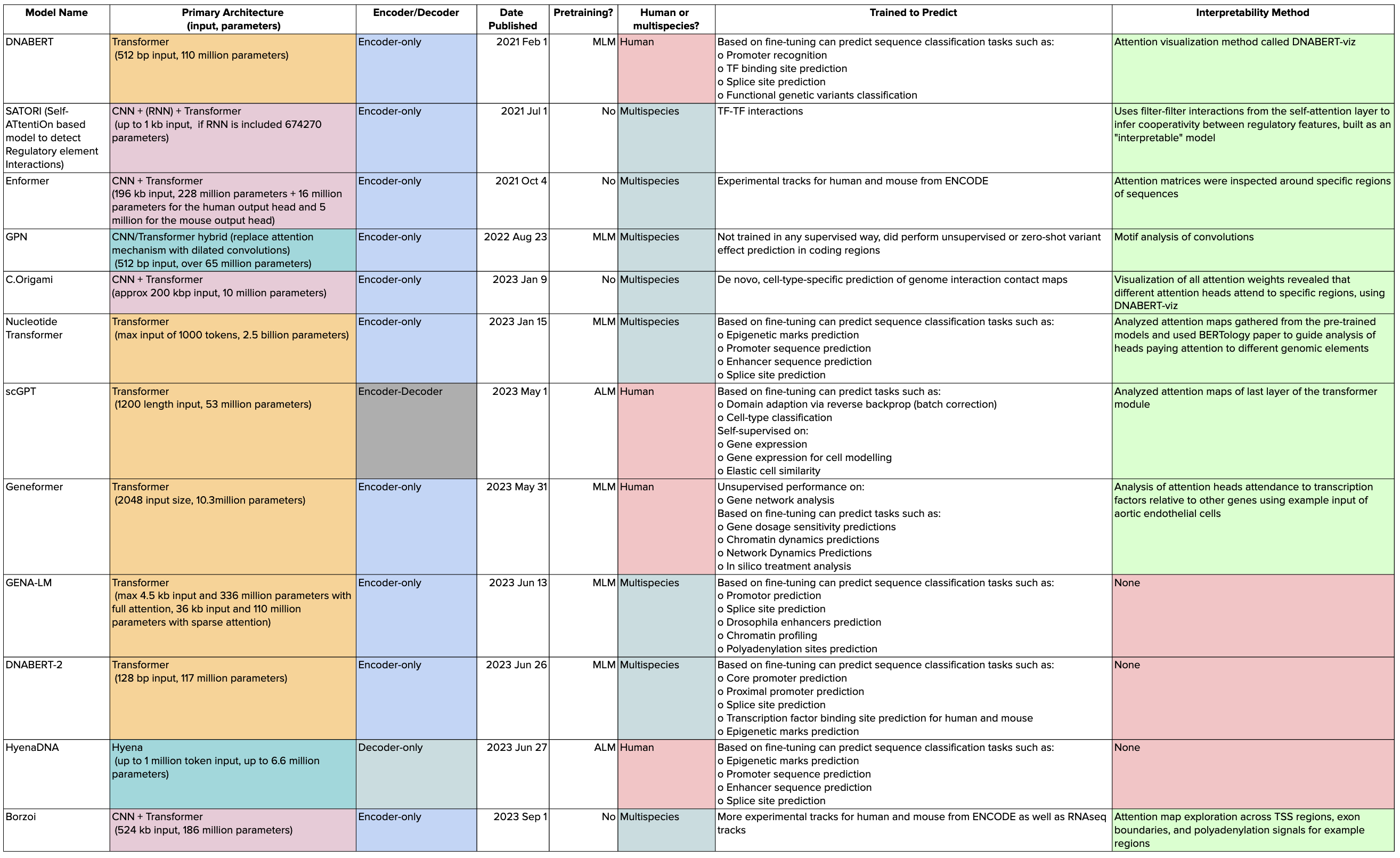
Figure 3: Compute requirements, shown in PFS-Days, reflect the intensive resources needed for training discussed models.
Conclusion
The exploration of LLMs in genomics reveals a promising future for these models in understanding genomic data. The advancements in transformer architectures, along with explorations into alternative structures such as Hyena layers and diffusion models, suggest an avenue for more scalable, interpretable, and resource-efficient genomic models. Future research is anticipated to further harness cross-species genomic data, improve interpretability methodologies, and refine pre-training techniques to elevate the predictive capacity and applicability of such models.

