- The paper introduces a benchmark that shows a 37.5% accuracy boost when using Knowledge Graphs for complex enterprise SQL queries.
- It details a tailored enterprise SQL schema and a domain-specific ontology to enhance LLM query performance.
- Experimental findings reveal that integrating KGs reduces query errors and improves semantic context with LLMs.
Understanding the Role of Knowledge Graphs on LLM's Accuracy for SQL Databases
Introduction
The paper explores the accuracy of LLMs in answering questions about enterprise SQL databases, particularly focusing on how Knowledge Graphs (KGs) might enhance this accuracy. Although several existing benchmarks such as Spider and WikiSQL have shown effectiveness for general Text-to-SQL tasks, their applicability to enterprise settings—characterized by complex, high-dimensional data schemas and business-specific requirements—remains an open question.
To bridge this gap, this study introduces a benchmark specifically tailored to enterprise settings within the insurance domain. It evaluates the performance of LLMs in answering enterprise questions directly on SQL databases and through a KG.
Benchmark Framework
Enterprise SQL Schema
The benchmark uses a subset of the OMG Property and Casualty Data Model, focusing on 13 primary tables that cover key aspects such as claims, policies, and financial transactions. This schema is a common representation within the insurance industry, thus providing a robust testbed for evaluating LLM capabilities.
Enterprise Questions
A set of 43 natural language questions was designed to span various levels of complexity in both question structure and schema requirements. These questions are classified into four quadrants based on their complexity (Figure 1):
- Low Question/Low Schema Complexity
- High Question/Low Schema Complexity
- Low Question/High Schema Complexity
- High Question/High Schema Complexity
These quadrants help in assessing the accuracy improvements that KGs offer for differently complex scenarios.
Context Layer
Complementing the SQL schema is a context layer comprising a domain-specific ontology (Figure 2) and mappings that facilitate the creation of a KG representation. This contextual information is crucial for the LLM to leverage domain semantics, aiming to enhance its understanding and accuracy when answering questions.
Experimental Setup and Results
Aligning with the paradigm of zero-shot prompting, GPT-4 was utilized within this benchmark to convert natural language questions into SQL and SPARQL queries. The execution of these queries against the databases provides insights into the LLM's accuracy in producing correct answers.
Overall Execution Accuracy (OEA) results were aggregated across all questions.
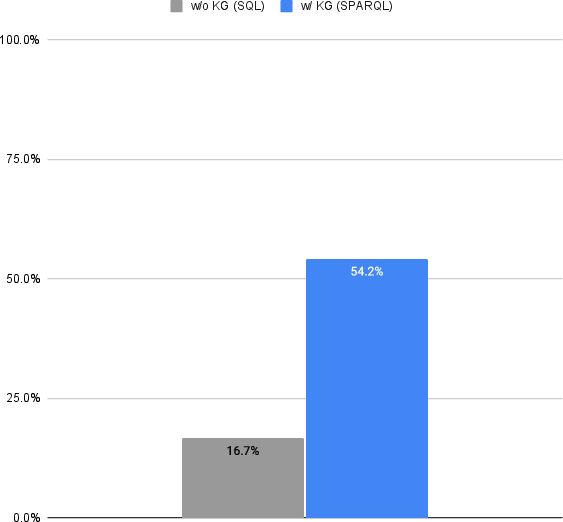
Figure 3: Average Overall Execution Accuracy (AOEA) of SPARQL and SQL for all the questions in the benchmark.
The benchmark showed that directly querying SQL databases using LLMs achieves an accuracy of 16.7%. In contrast, employing a KG representation significantly boosts accuracy to 54.2%, presenting a 37.5% improvement. This substantial increase underscores the effectiveness of KGs in providing necessary context for complex enterprise data models.
Further breakdowns by quadrant revealed that KGs improved accuracy across all categories, with both low and high schema complexity questions benefiting from their use:
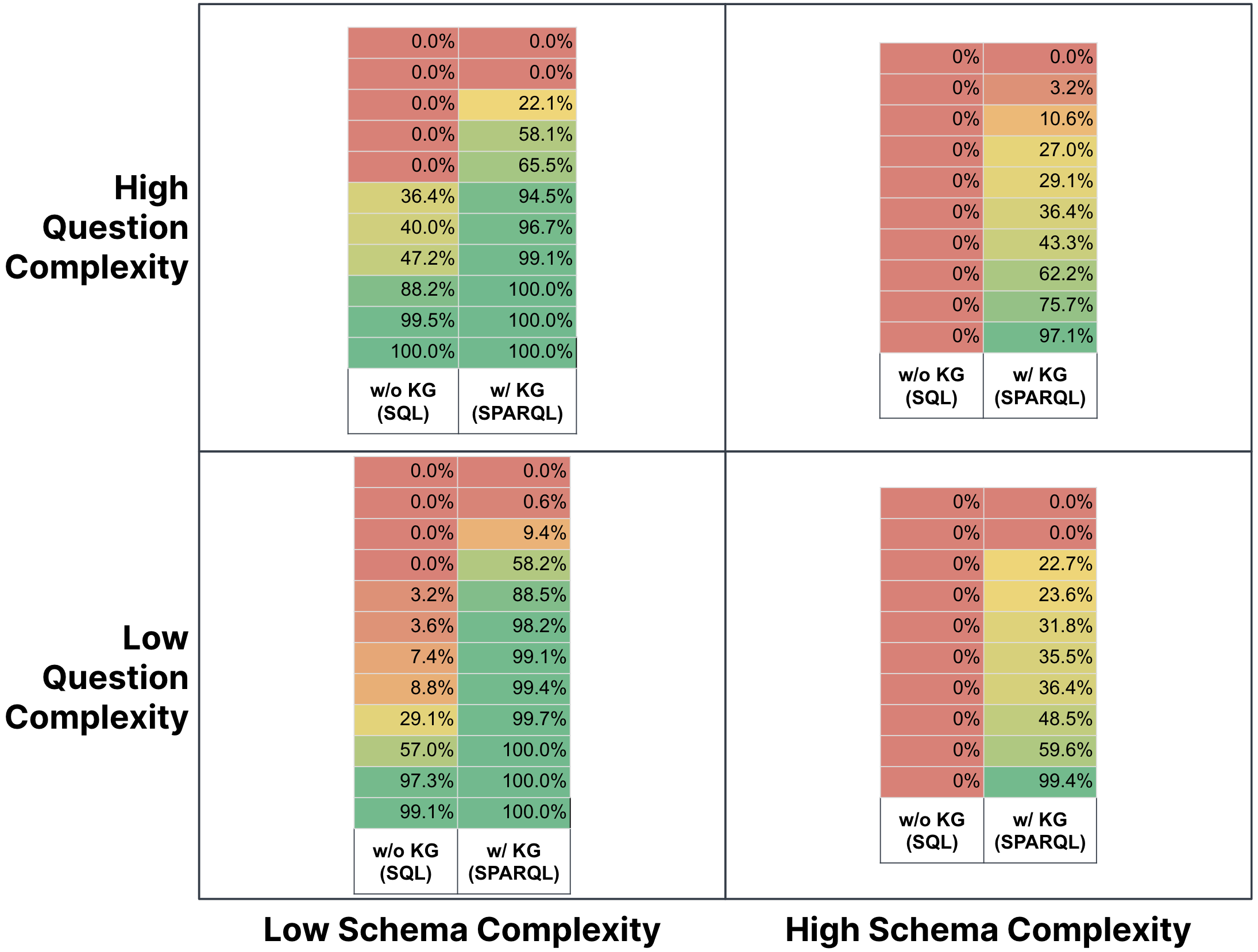
Figure 4: Overall Execution Accuracy (OEA) of SPARQL and SQL for each quadrant as a heatmap.
Discussion
These results provide empirical support for the hypothesis that KGs enhance LLM accuracy by supplying much-needed contextual and semantic information. KGs help mitigate challenges such as schema complexity and ambiguity in natural language questions by anchoring query generation in a well-defined semantic framework.
The examination of partial accuracies and query failures also revealed specific patterns of LLM missteps. SQL queries often exhibited hallucinations involving nonexistent columns and values, while SPARQL queries occasionally encountered path inconsistencies. Addressing these issues through improved KG design and better prompt engineering could further refine query accuracy.
Conclusion
The study confirms that incorporating KGs into LLM-based query systems significantly enhances the accuracy of responses to enterprise-scale questions over SQL databases. Given these findings, enterprises are encouraged to invest in KG infrastructure for improved data engagement.
Although the current benchmark results are promising, there is room for further exploration, particularly in expanding the ontology, refining mapping techniques, and extending the question set for more comprehensive evaluations. Future research should also explore user studies for qualitative insight and investigate the cost-benefit aspects of implementing KGs on an enterprise scale. By systematically addressing these areas, the gap between LLM capabilities and enterprise demands can be progressively minimized.