- The paper demonstrates that LLMs guide high-level decision-making, significantly improving sample efficiency in solving long-horizon tasks.
- The methodology leverages LLM-provided skill priors to bias action selection, reducing the need for manual reward shaping in hierarchical RL.
- Experimental results across MiniGrid, SkillHack, Crafter, and robotic tasks show superior performance and adaptability compared to traditional baselines.
Detailed Analysis of "LLM Augmented Hierarchical Agents"
Introduction
The paper "LLM Augmented Hierarchical Agents" explores the integration of LLMs with Hierarchical Reinforcement Learning (HRL) to enhance the learning efficiency of agents tasked with solving long-horizon, temporally-extended tasks. By using LLMs to guide high-level decision-making, the research addresses challenges in RL such as sparse rewards and inefficient sample usage, making it possible for autonomous agents to learn complex policies in a more sample-efficient manner. The authors evaluate their method across both simulated environments and real-world scenarios, showcasing improvements over traditional baseline methods.
Methodology
The core methodology leverages the semantic understanding encoded within LLMs to guide high-level actions in HRL. LLMs, trained on massive text corpora, offer a reservoir of common-sense priors that can be tapped to bias action selection toward meaningful, task-relevant choices. The method involves:
- Skill Priors via LLMs: Using LLMs to evaluate the relevancy of a skill or sub-task based on a given high-level task description and current state. This is achieved through the function fLLM, which estimates the probability of a skill being relevant to the task.
- Hierarchical Policy Structure: The agent operates under a hierarchical policy where low-level skills execute primitive actions, guided by high-level policies influenced by LLM-derived skill priors. The influence of LLMs diminishes as training progresses, ensuring the agent is independent of LLM guidance during deployment.
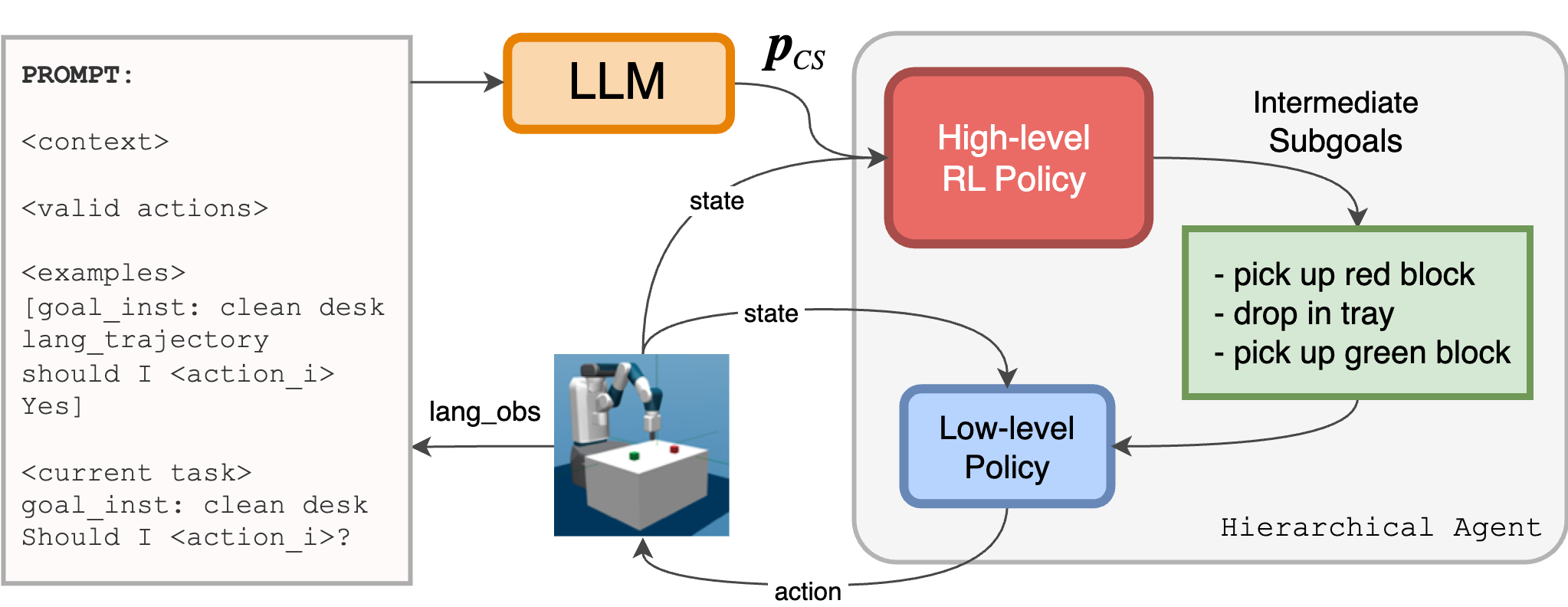
Figure 1: The LLM to guides the high-level policy and accelerates learning. It is prompted with the context, some examples, and the current task and observation. The LLM's output biases high-level action selection
Experiments
The efficacy of LLM-guided hierarchical agents was tested in several environments, including MiniGrid, SkillHack, Crafter, and a real-world uArm robotic experiment. Each of these setups provided unique challenges that highlighted different aspects of the method's advantages.
MiniGrid Experiments
Three tasks—UnlockReach, KeyCorridor v0, and KeyCorridor v1—were used to test the approach in a grid world. The experiments demonstrated that agents utilizing LLM guidance significantly outperformed both vanilla HRL agents and those relying on manually shaped rewards.
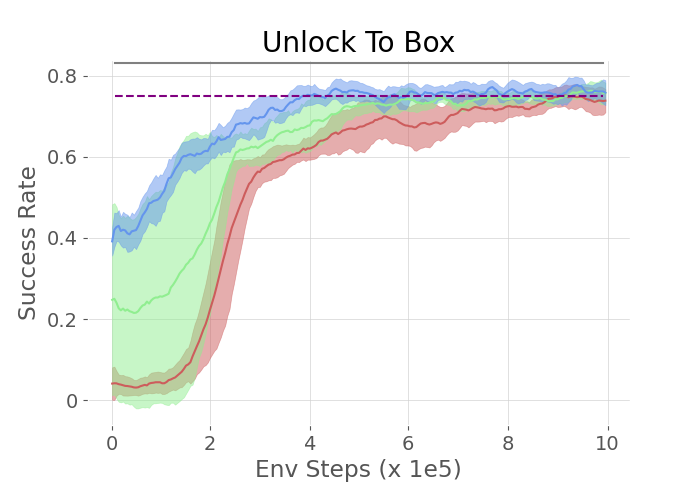
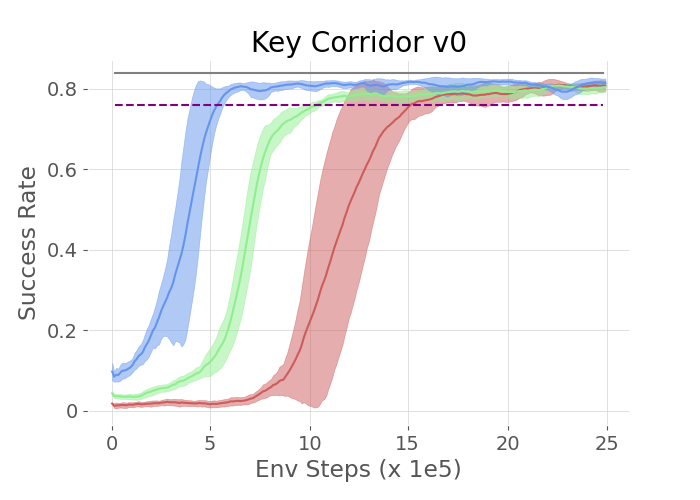
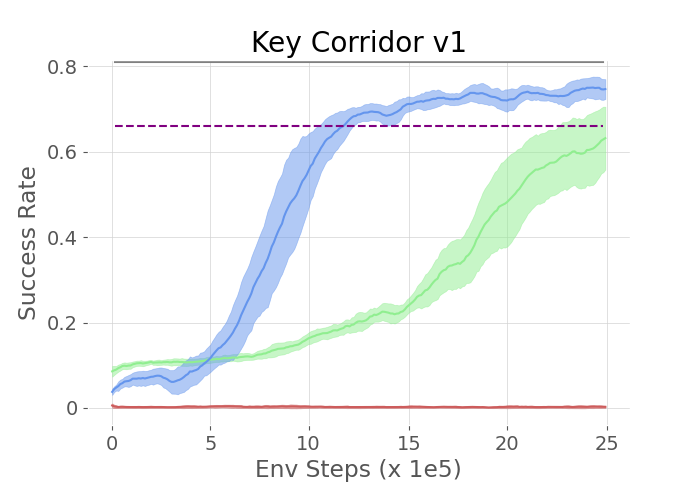

Figure 2: The plots show the success rate of different methods on the three tasks in the MiniGrid Environment.
SkillHack and Crafter
In more complex environments like SkillHack and Crafter, the hierarchical agents guided by LLMs continued to exhibit superior learning efficiency and success rates compared to baseline methods. SkillHack's Battle and FrozenLavaCross tasks, along with Crafter's GetStone and MakeStonePickaxe objectives, demonstrated how the method effectively handles longer, more sequential task structures.
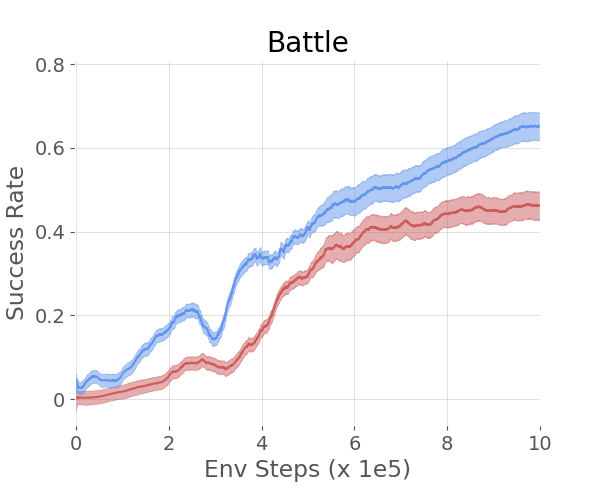
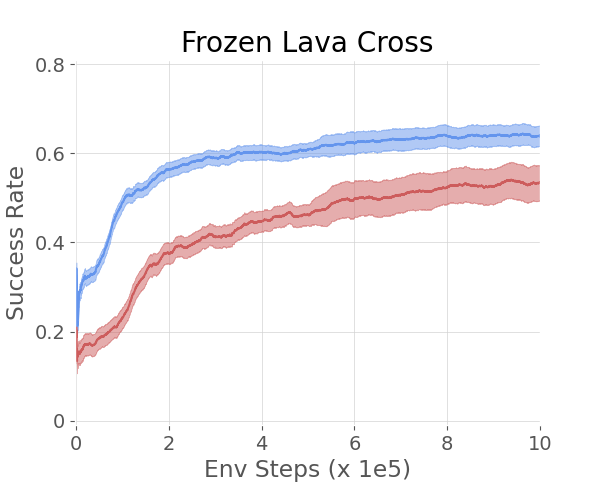
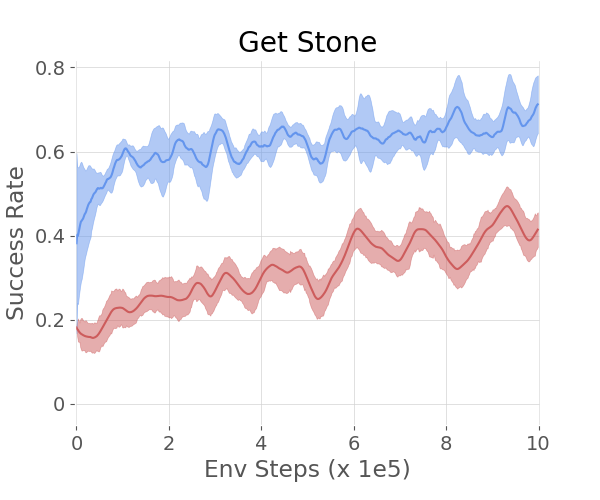
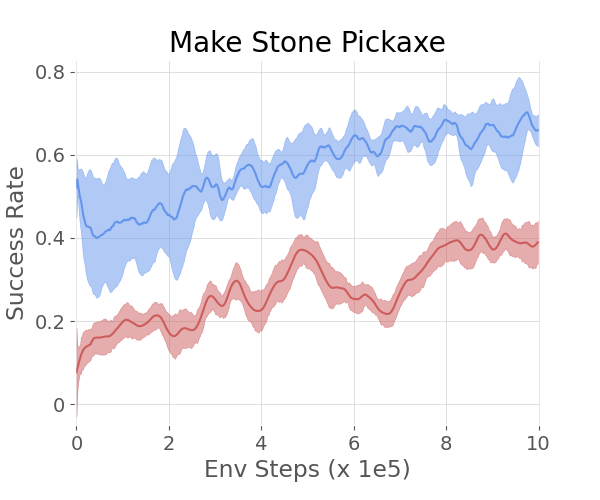

Figure 3: The 2 plots on the left show the success rate of different methods on the SkillHack - Battle and Frozen Lava Cross. The 2 plots on the right show the success rate of different methods on the Crafter - Get Stone and Make Stone Pickaxe.
uArm Robot
In real-world tests featuring a robotic arm tasked with block manipulation, the LLM-augmented framework efficiently solved tasks like DeskCleanUp and SwapBlocks. The use of tabular Q-learning in these experiments showcased the framework’s adaptability to simple, discrete state and action spaces.
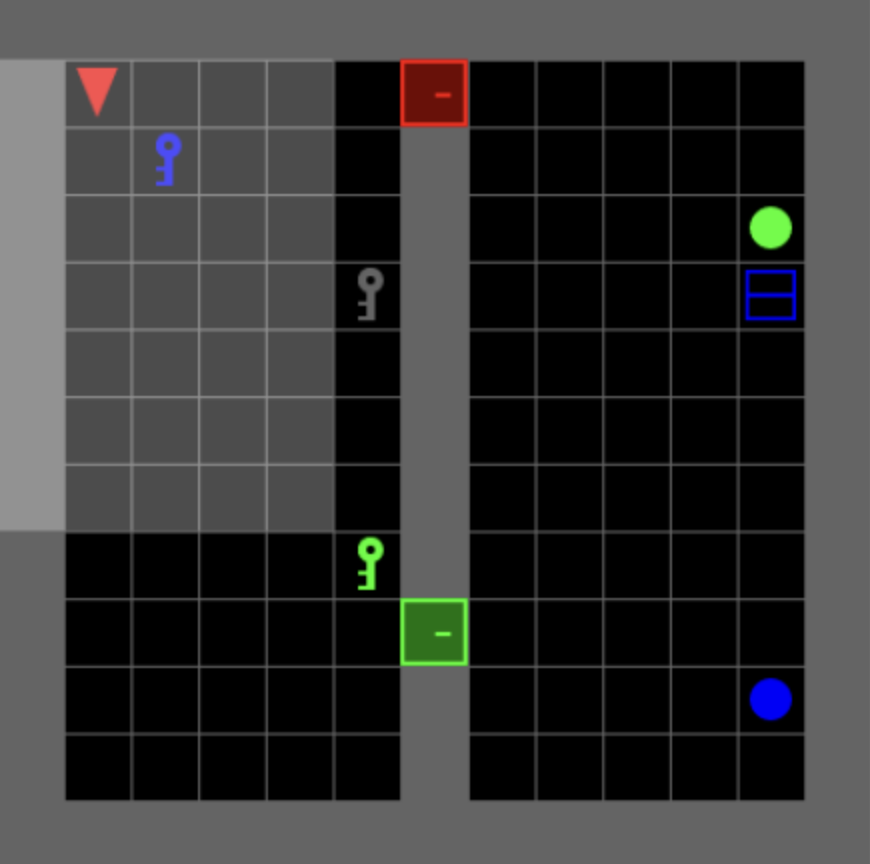

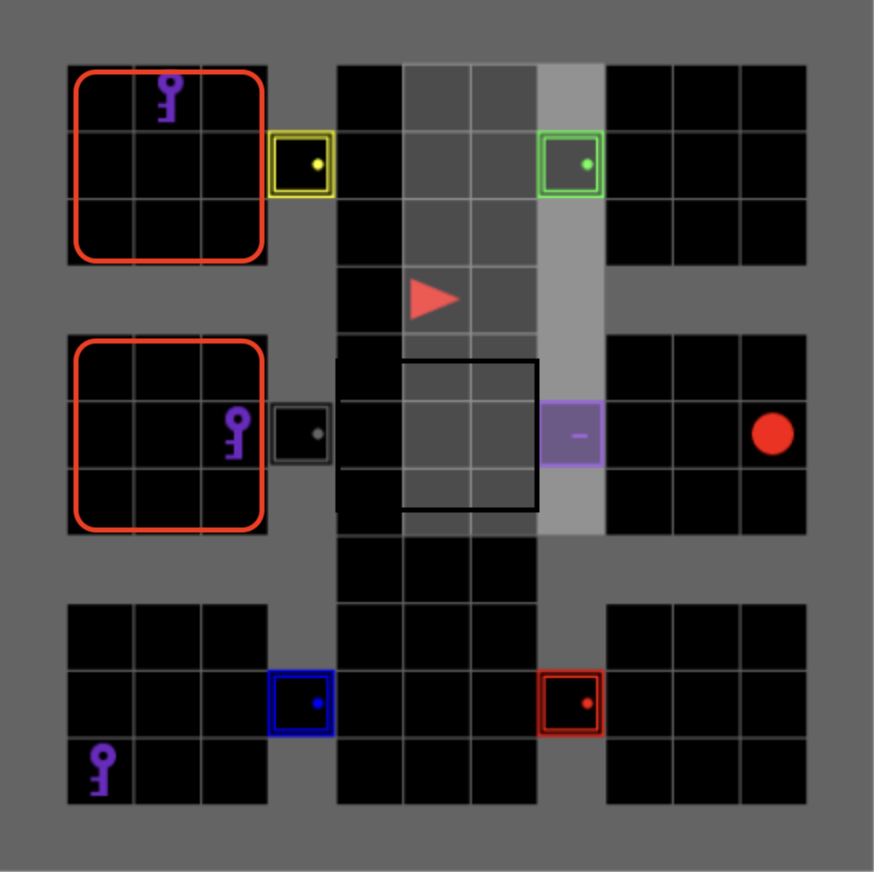
Figure 4: Goal: open the locked green door and go to the blue box \newline
Comparison and Analysis
The LLM-augmented method was compared to several baselines:
- Vanilla HRL: Struggles with exploration efficiency due to lack of guidance.
- Shaped HRL: Requires labor-intensive manual reward crafting.
- Oracle and SayCan Without Affordances: While comparable in performance, these methods often relied on continued LLM access, whereas the proposed system eliminates the need for LLMs during deployment, reducing operational costs and dependencies.
Discussion and Implications
The research illustrates that LLMs can significantly enhance the learning efficiency of hierarchical agents, simplifying the challenge of sample inefficiency in RL. By embedding common-sense reasoning into the decision-making process, these agents are better equipped to tackle tasks that require sophisticated temporal planning and decision-making.
This work opens avenues for further exploration, particularly in automating language-to-perception frameworks using emerging vision-LLMs and expanding multi-tier hierarchical models to address more extensive task domains. Such advancements could extend to numerous applications, from robotics to interactive AI systems needing efficient learning capabilities without exhaustive, manually-crafted guidance.
Conclusion
The integration of LLMs into hierarchical agents offers a promising route to address some of the core limitations of traditional RL methods. By leveraging LLMs to provide temporal and semantic guidance, this approach not only improves learning speed and efficacy but also reduces reliance on heavily engineered solutions, adapting well to both simulated and real-world environments.