- The paper demonstrates a modular prototype that combines pre-trained models for efficient multimodal image chat, editing, and segmentation.
- It leverages LLaVA's conversational interface, SEEM's segmentation, and GLIGEN's image generation to reduce additional training requirements.
- The system supports iterative visual refinements, enhancing creative workflows and practical applications in photography and education.
LLaVA-Interactive: An All-in-One Demo for Image Chat, Segmentation, Generation, and Editing
Introduction
The paper "LLaVA-Interactive: An All-in-One Demo for Image Chat, Segmentation, Generation and Editing" (2311.00571) presents a prototype system designed to facilitate advanced multimodal human-AI interactions. This framework is equipped to handle complex tasks by integrating visual and textual prompts, thereby enhancing the depth and breadth of human-AI dialogue. The system uniquely combines the capabilities of several pre-established AI models—LLaVA for visual chat, SEEM for image segmentation, and GLIGEN for image generation and editing—without necessitating further training.
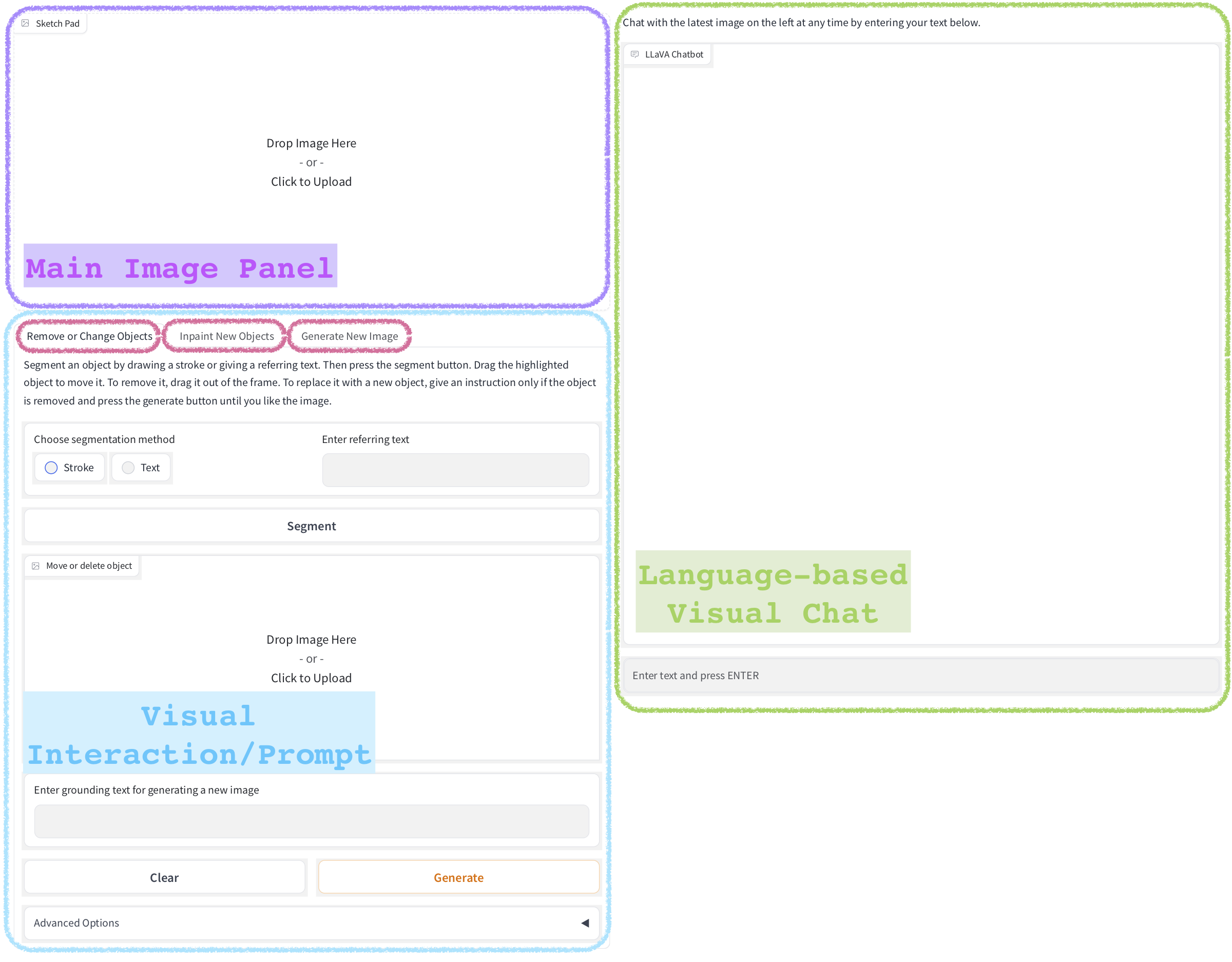
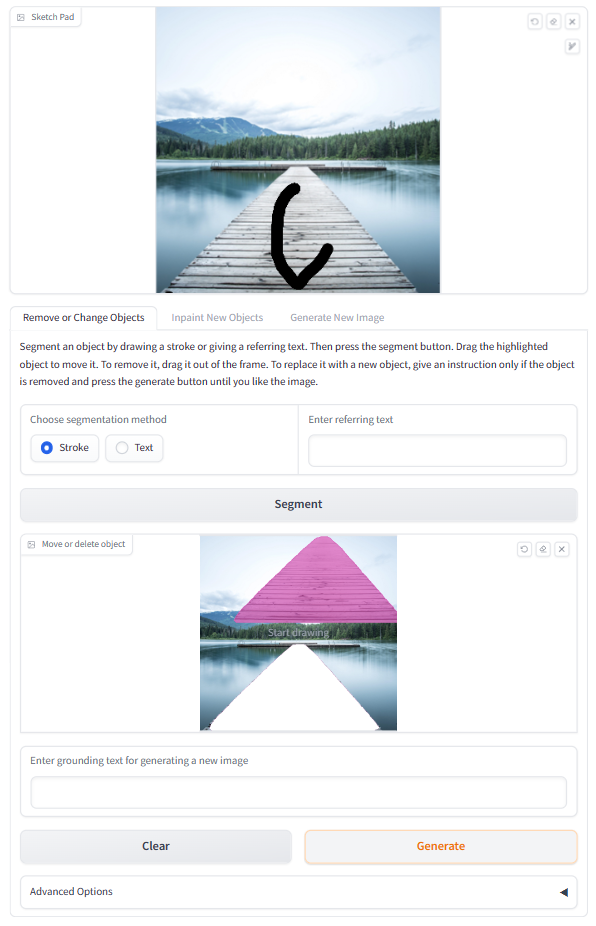
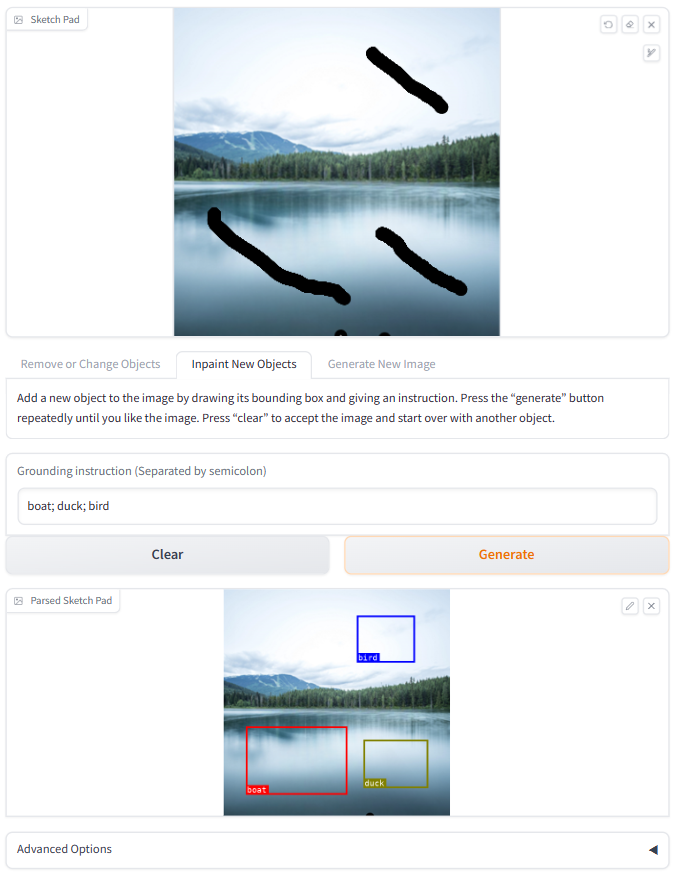
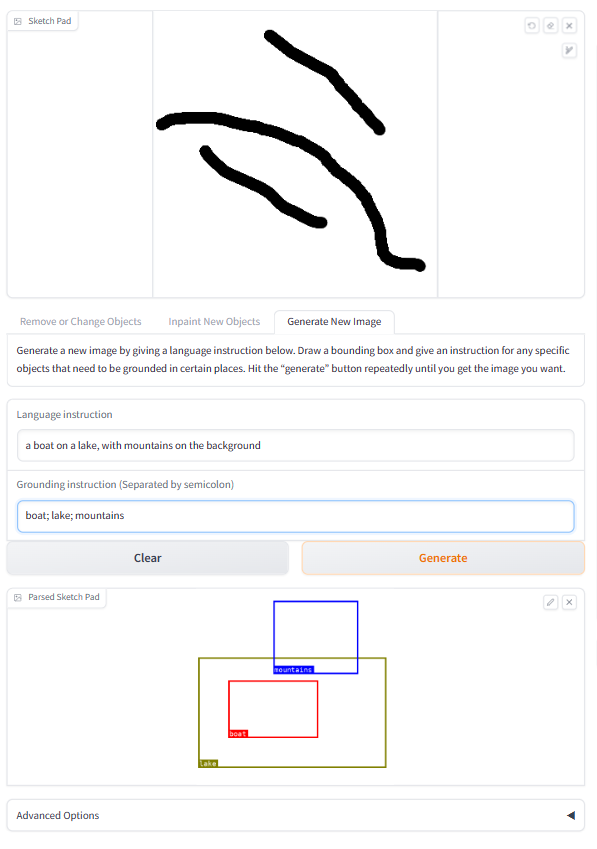



Figure 1: The user interface of LLaVA-Interactive. (a) The overall layout, including three main panels with functionalities in magenta rounded rectangles, as detailed in (b,c,d).
System Architecture
The architecture of LLaVA-Interactive is characterized by its ability to process both linguistic and visual prompts, thus meeting a range of sophisticated multimodal tasks. Unlike previous models like GPT-4V, which primarily focus on text-based interactions augmented by images, LLaVA-Interactive allows for a richer array of interactions, including the modification and creation of images based on user-generated visual cues.
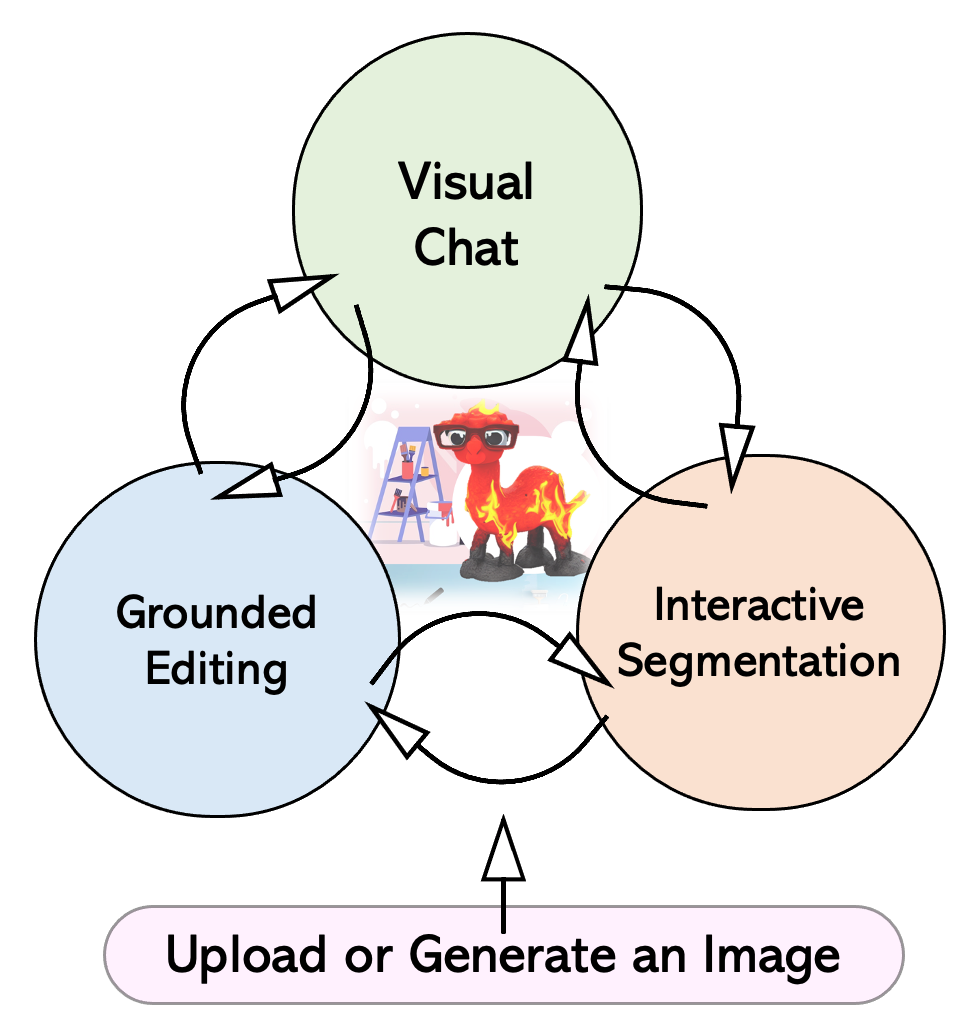
Figure 2: The workflow of LLaVA-Interactive.
The system operates through a straightforward workflow (Figure 2) where images can be interactively manipulated through segmentation, editing, or complete generation. It supports an efficient multi-turn dialogue paradigm enabling iterative improvement and refinement of visual content.
Methodology
LLaVA-Interactive does not rely on training models from scratch. Instead, it leverages pre-trained models: LLaVA for conversational visual overlays, SEEM for segmentation, and GLIGEN for grounding language instructions in visual outputs. This modular architecture allows LLaVA-Interactive to achieve high functionality with reduced computational costs.
Visual Prompting
A significant feature is the system's ability to handle diverse visual prompts such as strokes and bounding boxes, which are intuitive for users to specify areas of interest for editing or generation tasks. This facilitates a more fluid and responsive interaction paradigm compared to systems relying solely on textual input.
Practical Applications
LLaVA-Interactive's potential is demonstrated through various use cases such as supporting photographic artists (Figure 3) and facilitating iterative visual scene creation (Figures 4 and 5). These examples illustrate the system's capacity to enhance creative workflows through interactive enhancements and prompt-driven transformations.
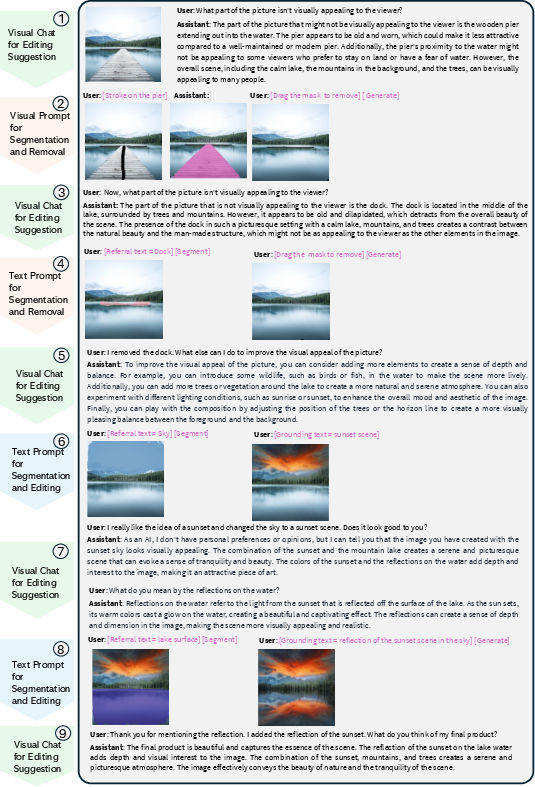
Figure 3: The use case study of LLaVA-Interactive as a photographic artist engaging in multi-turn multimodal image editing.
Evaluation and User Studies
The paper presents a preliminary evaluation of LLaVA-Interactive across different scenarios, each emphasizing the system's ability to enable complex task completion with minimal human intervention. Applications such as graphic design for thematically rich posters (Figures 6-8) and interactive education tools (Figures 15-17) underscore the system's versatility and applicability across domains.
Conclusion
LLaVA-Interactive stands out by seamlessly integrating multiple pre-trained models into a cohesive, user-friendly framework for multimodal interactions. Its ability to support text and visual input/output in a unified interface opens up new possibilities for AI-assisted creativity and design. Future advancements could involve integrating superior model variants to further enhance the specific skills within LLaVA-Interactive or developing more foundational models with native support for a broader range of tasks.
The open-source nature of LLaVA-Interactive encourages ongoing contributions from the research community, fostering continued innovation in the field of multimodal AI systems.