- The paper demonstrates that continuous training and fine-tuning significantly enhance LLM accuracy for medical QA, raising F1 scores from 14.1% to 38.8%.
- It leverages a curated Chinese medical corpus and the CMExam dataset to effectively impart domain-specific knowledge and improve reasoning capabilities.
- The study addresses catastrophic forgetting by balancing specialization gains with the retention of general language skills across tasks.
Continuous Training and Fine-tuning for Domain-Specific LLMs in Medical Question Answering
Introduction
The development and application of domain-specific LLMs is essential for maintaining high performance in specialized fields such as healthcare, law, and engineering. Despite the impressive capabilities of models like GPT-3 and Llama, their general-purpose nature often leads to insufficient expertise in specialized domains, particularly in medical question answering tasks. Training domain-specific models from scratch is computationally prohibitive; thus, the paper presents an effective approach for adapting base models to such domains using continuous training and fine-tuning.
Methodology
Base Models
The adaptation process begins with utilizing Llama-2-13B and its Chinese variant, Chinese-Llama-2-13B, as base models. These models, pre-trained on vast corpora with extensive token contexts, serve as the foundation for imparting domain-specific knowledge while maintaining general representation capabilities.
Continual Training
The continuous training stage involves further pre-training the models on a curated dataset derived from Chinese medical references, comprising approximately 1 billion tokens. This dataset encompasses formal medical terminologies and diverse subtopics such as infectious diseases and gynecology, facilitating the acquisition of comprehensive medical knowledge for the models.
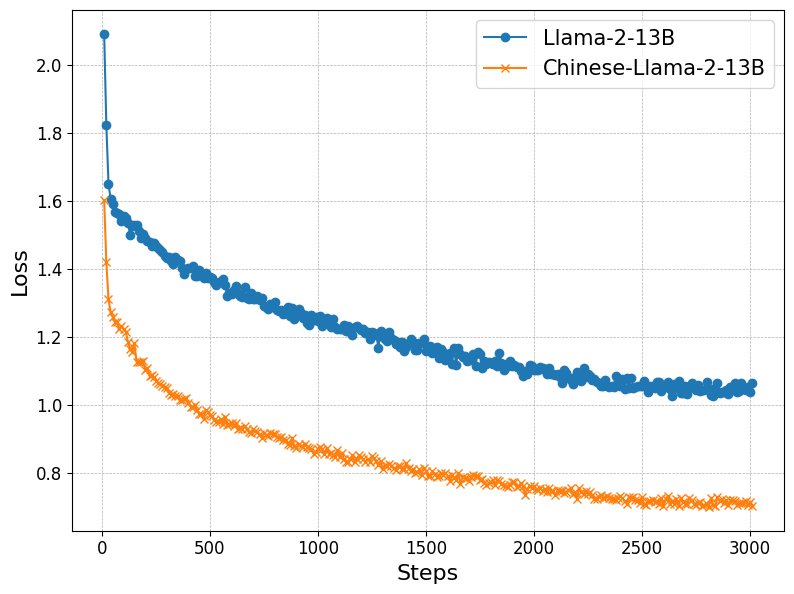
Figure 1: Continual training loss on encyclopedia QA dataset.
Fine-tuning
Fine-tuning is conducted using CMExam, a robust dataset consisting of 54,000 Chinese medical licensing examination questions. The questions span multiple disease categories and clinical departments, accompanied by detailed reasoning explanations. This step aims to enhance the reasoning capabilities of the models, crucial for effective medical question answering.
Results
The methodological focus on continual training and instruction fine-tuning demonstrates tangible improvements in the models' domain-specific accuracy without significant degradation of general capabilities. Specifically, the training increases F1 scores markedly, from initial suboptimal percentages to competitive levels comparable to GPT-3.5, using considerably fewer computational resources. For instance, the Llama-2-13B’s question reasoning performance notably improved from 14.1% to 38.8% in F1 score.
Evaluation of Knowledge Retention
A challenging aspect of the adaptation process is the potential for catastrophic forgetting, where gains in the medical domain could lead to losses in general knowledge. While metrics such as CMMLU reveal these trends, the strategic use of continuous training epochs mitigates such setbacks, balancing specialization with knowledge retention.
Challenges in Cross-lingual Mix
Attempts to improve model performance by integrating English datasets (MedQA and MedMCQA) for fine-tuning resulted in unexpected degradation on Chinese benchmarks. This outcome highlights the complexities of cross-lingual transfer learning, indicating that methods successful in one language do not universally translate to others without specialized adaptation strategies.
Conclusion
The paper successfully demonstrates that continuous training, complemented by domain-specific fine-tuning, can effectively tailor general LLMs to specialized fields such as medical question answering. While the risk of catastrophic forgetting requires careful management, the approach provides an efficient pathway for developing proficient domain-specific models. Future research should continue to explore techniques to optimize cross-lingual model adaptation and address knowledge retention challenges in specialized domains.

